社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
htmlcxx是C++中解析html格式数据的第三方库,这个库的特点就是快捷、轻量级。最近在使用的时候在解析html的时候,总有搜索标签的需求,所以自己封装了一个工具。
HtmlCxxUtils.h头文件/**
* HtmlCxxUtils类定义
*
* @author hestyle
* @version 1.0.0
*/
#ifndef _HTMLCXX_UTILS_
#define _HTMLCXX_UTILS_
#include "htmlcxx/include/ParserDom.h"
//导入htmlcxx.lib,请修改为你自己的路径
#pragma comment(lib,"htmlcxx/lib/htmlcxx.lib")
using namespace std;
using namespace htmlcxx;
class HtmlCxxUtils{
public:
HtmlCxxUtils();
~HtmlCxxUtils();
/*
* 在[beginIt,endIt)寻找第index个名为tagName的标签
* @param beginIt 搜索起始迭代器
* @param endIt 搜索尾端迭代器
* @param tagName 需要搜索标签名
* @param index 符合搜索条件的第index个(默认是第1个)
*/
static tree<HTML::Node>::iterator selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt,
string tagName, int index = 1);
/*
* 在[beginIt,endIt)寻找第index个名为tagName的标签,并且该标签中含有名为attrName的属性、属性值为attrValue
* @param beginIt 搜索起始迭代器
* @param endIt 搜索尾端迭代器
* @param tagName 需要搜索标签名
* @param attrName 标签含有的属性名
* @param attrValue 标签含有的attrName属性的值
* @param index 符合搜索条件的第index个(默认是第1个)
*/
static tree<HTML::Node>::iterator selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt,
string tagName, string attrName, string attrValue, int index = 1);
};
#endif // !_HTMLCXX_UTILS_
HtmlCxxUtils.cpp类文件/**
* HtmlCxxUtils类方法实现
*
* @author hestyle
* @version 1.0.0
*/
#include <iostream>
#include <string>
#include <vector>
#include "HtmlCxxUtils.h"
using namespace std;
using namespace htmlcxx;
HtmlCxxUtils::HtmlCxxUtils() {
}
HtmlCxxUtils::~HtmlCxxUtils() {
}
/*
* 在[beginIt,endIt)寻找第index个名为tagName的标签
* @param beginIt 搜索起始迭代器
* @param endIt 搜索尾端迭代器
* @param tagName 需要搜索标签名
* @param index 符合搜索条件的第index个(默认是第1个,可省略,注意声明设置了默认参数,实现方法不要写默认参数,否则会报错)
*/
tree<HTML::Node>::iterator HtmlCxxUtils::selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt,
string tagName, int index) {
tree<HTML::Node>::iterator it = beginIt;
for (; it != endIt; ++it) {
if (it->isTag()) {
//扩展子标签
it->parseAttributes();
//第index个名为tagName的标签
if (strcmp(it->tagName().c_str(), tagName.c_str()) == 0 && index-- == 1) {
return it;
}
}
}
//否则返回空
return NULL;
}
/*
* 在[beginIt,endIt)寻找第index个名为tagName的标签,并且该标签中含有名为attrName的属性、属性值为attrValue
* @param beginIt 搜索起始迭代器
* @param endIt 搜索尾端迭代器
* @param tagName 需要搜索标签名
* @param attrName 标签含有的属性名
* @param attrValue 标签含有的attrName属性的值
* @param index 符合搜索条件的第index个(默认是第1个,可省略,注意声明设置了默认参数,实现方法不要写默认参数,否则会报错)
*/
tree<HTML::Node>::iterator HtmlCxxUtils::selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt,
string tagName, string attrName, string attrValue, int index) {
tree<HTML::Node>::iterator it = beginIt;
for (; it != endIt; ++it) {
it = selectTag(it, endIt, tagName);
if (it == NULL) {
break;
}
//检查该标签是否含有attrName属性,并且属性值为attrValue
if (it->attribute(attrName).first && strcmp(it->attribute(attrName).second.c_str(), attrValue.c_str()) == 0 && index-- == 1) {
return it;
}
}
return NULL;
}
#include <iostream>
#include <string>
#include "htmlcxx/include/ParserDom.h"
#include "HtmlCxxUtils.h"
using namespace std;
using namespace htmlcxx;
int main() {
//需要解析的html文本
string htmlStr = "<div class="parent"><div class="children_1"><span>I am the first span!</span></div><div class="children_2"><span>I am the second span!</span></div></div><div class="parent">123456789<div>";
//解析html前设置,方式解析中文报错
setlocale(LC_ALL, ".OCP");
HTML::ParserDom parser;
tree<HTML::Node> dom = parser.parseTree(htmlStr);
//输出树中所有的文本节点
tree<HTML::Node>::iterator it = dom.begin();
tree<HTML::Node>::iterator end = dom.end();
//测试static tree<HTML::Node>::iterator selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt,string tagName, int index = 1);
//查找html中的第一个span(不写index参数,默认是第一个)
tree<HTML::Node>::iterator firstSpanIt = HtmlCxxUtils::selectTag(it, end, "span");
if (firstSpanIt != NULL) {
//注意,上面的额搜索只搜索到了span标签,需要后一个位置进入span标签的内部
firstSpanIt++;
cout << "第一个span标签内部的text:" + firstSpanIt->text() << endl;
}
//查找html中的第2个span(不写index参数,默认是第一个)
tree<HTML::Node>::iterator secondSpanIt = HtmlCxxUtils::selectTag(it, end, "span", 2);
if (firstSpanIt != NULL) {
//注意,上面的额搜索只搜索到了span标签,需要后一个位置进入span标签的内部
secondSpanIt++;
cout << "第二个span标签内部的text:" + secondSpanIt->text() << endl;
}
//测试static tree<HTML::Node>::iterator selectTag(tree<HTML::Node>::iterator& beginIt, tree<HTML::Node>::iterator& endIt, string tagName, string attrName, string attrValue, int index = 1);
//查找html中的第一个div(不写index参数,默认是第一个),并且含有class属性,属性值为“children_1”
tree<HTML::Node>::iterator firstDivIt = HtmlCxxUtils::selectTag(it, end, "div", "class", "children_1");
if (firstDivIt != NULL) {
cout << "第一个含有属性class="children_1"的div:" + firstDivIt->text() << endl;
}
//查找html中的第二个div(不写index参数,默认是第一个),并且含有class属性,属性值为“parent”
tree<HTML::Node>::iterator secondDivIt = HtmlCxxUtils::selectTag(it, end, "div", "class", "parent", 2);
if (firstDivIt != NULL) {
secondDivIt++;
cout << "第二个含有属性class="parent"的div:" + secondDivIt->text() << endl;
}
}
控制台输出: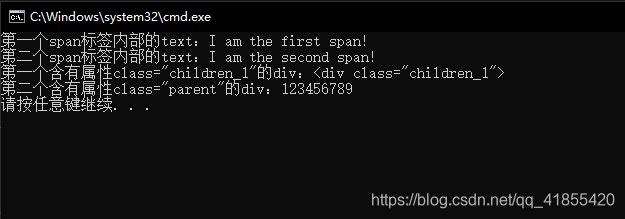
以上就是我自己封装的htmlcxx工具类以及使用方法,希望可以帮助到给为道友。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
