社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
近来想用C++写一些爬虫小工具,爬虫爬取网页时,需要对html格式数据进行解析,拿到其中需要的数据,比如某个标签下的文本、图片的url等等。下面我将演示一下htmlcxx解析器的环境搭建、基本使用。
htmlcxx是什么?HtmlCxx是一款简洁的,非验证式的,用C++编写的css和html解析器。使用由KasperPeeters编写的强大的tree.h库文件,可以实现类似STL的DOM树遍历和导航。可以通过解析后生成的树,逐字节地重新生成原始文档。
htmlcxx下载地址:https://sourceforge.net/projects/htmlcxx/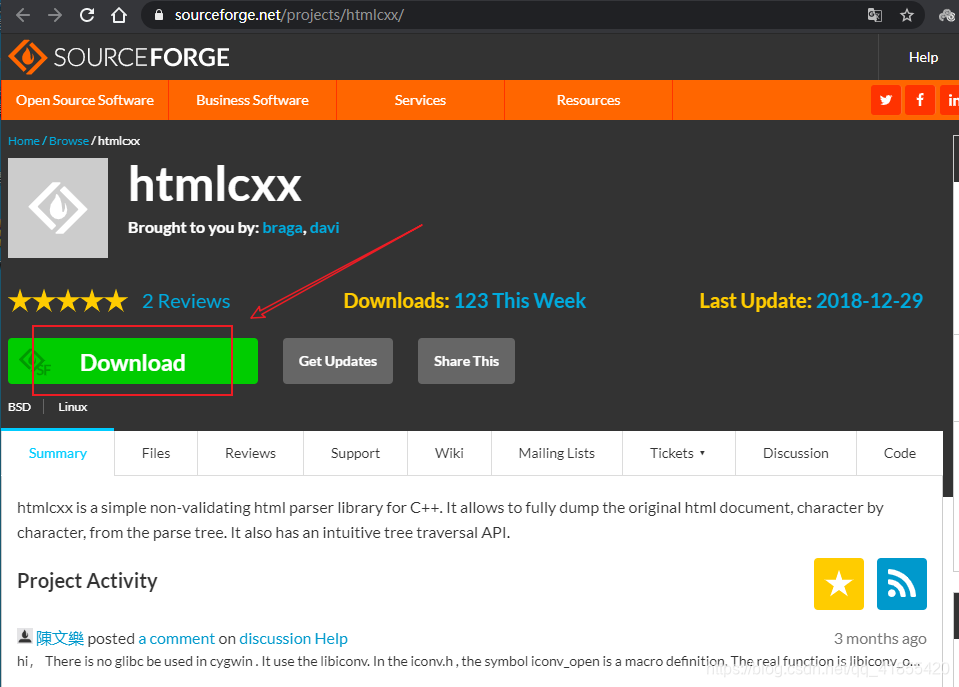
下载玩后是一个压缩包。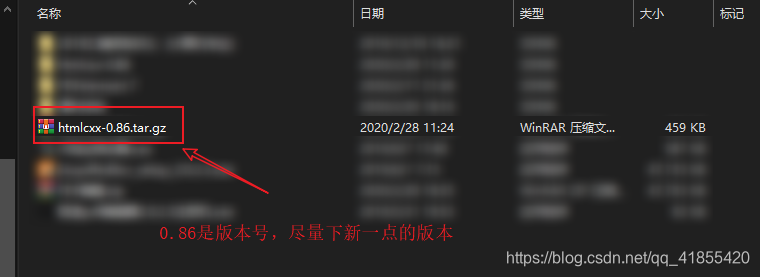
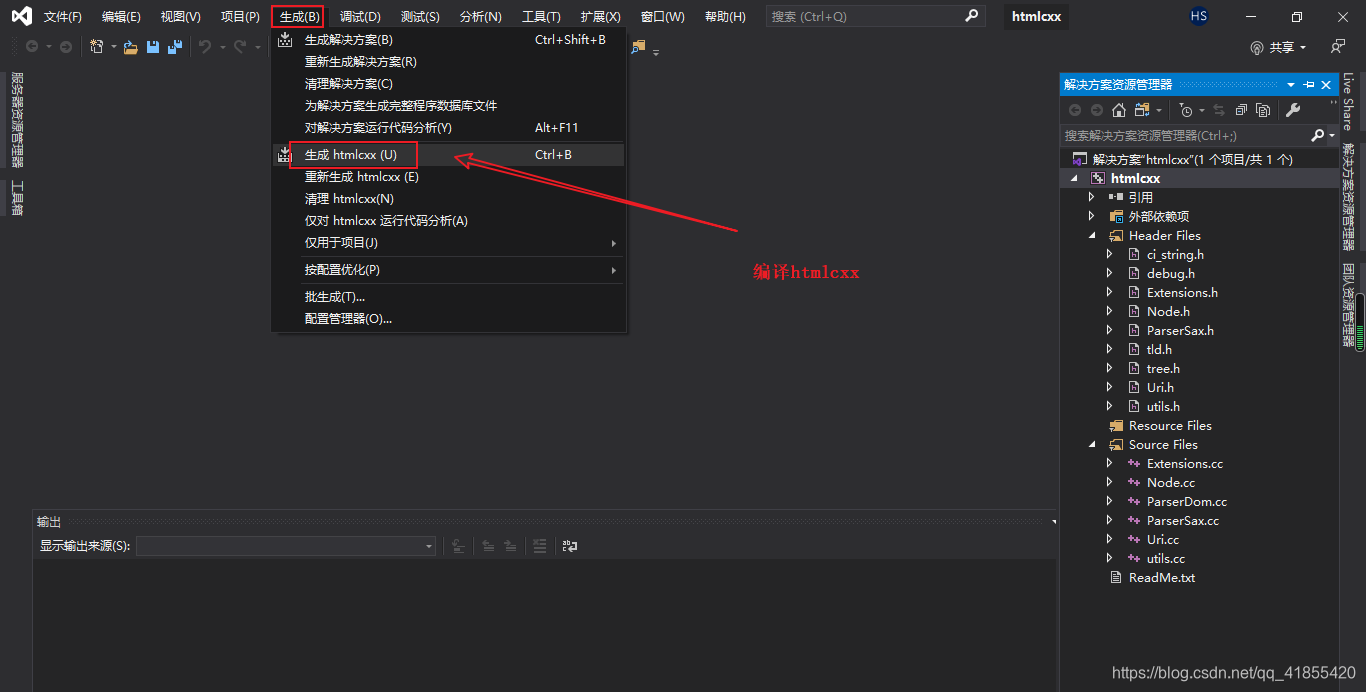
htmlcxx项目上面下载的是源码,需要手动对其进行编译!
htmlcxx-0.86.tar.gzhtmlcxx.vcproj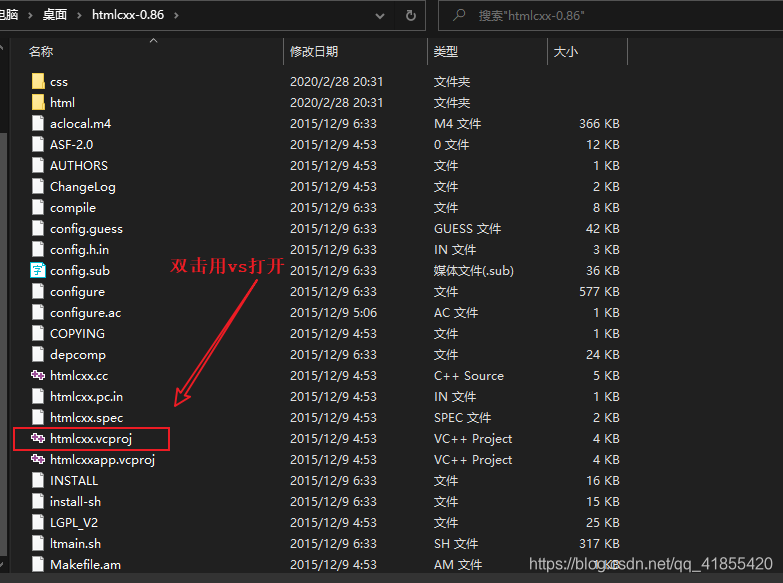
如果提示vs版本过高,直接点击确定即可。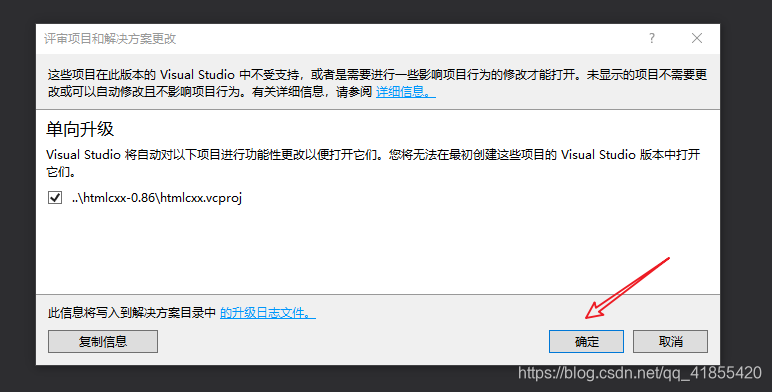
vs中打开后可以看到文件资源列表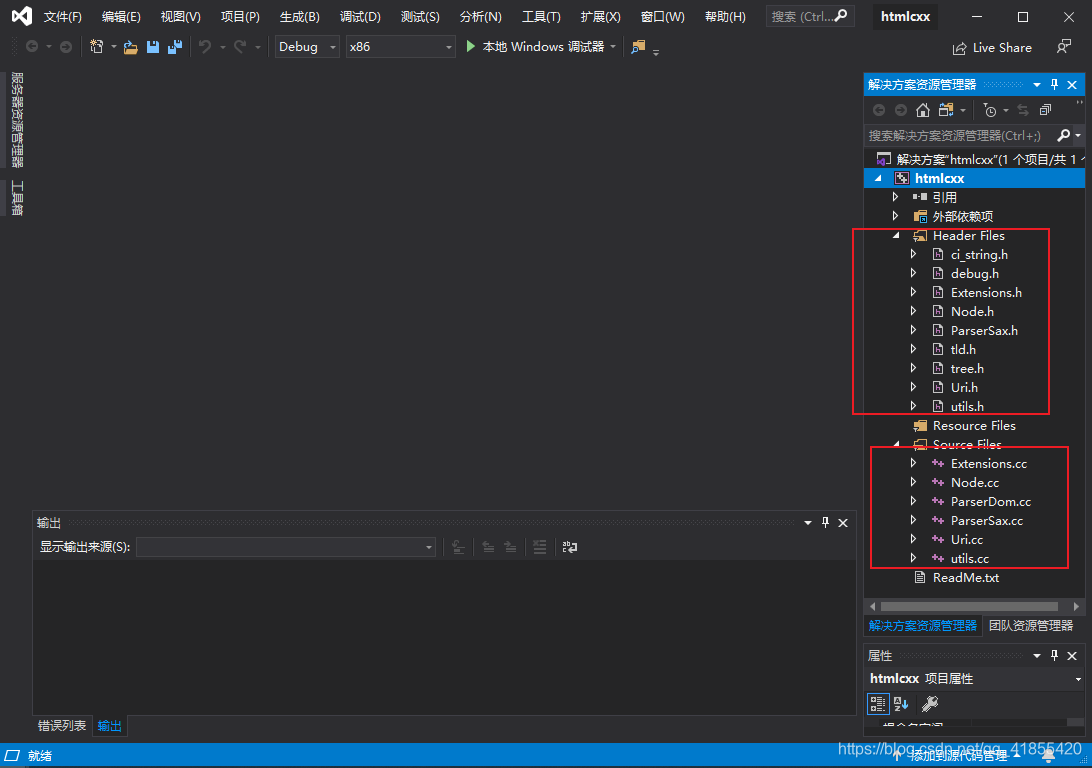
多线程调试 DLL (/MDd)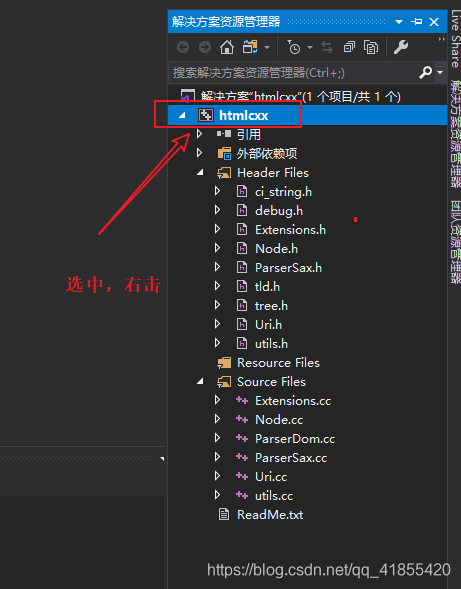
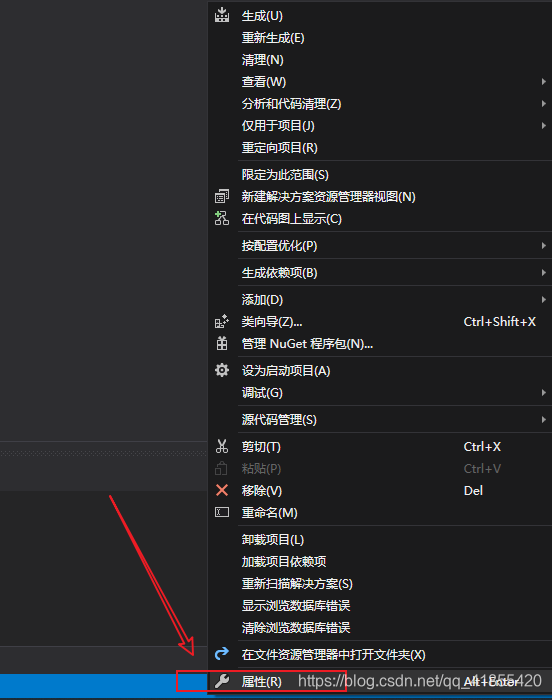
修改 项目属性->配置属性->C/C+±>代码生成->运行库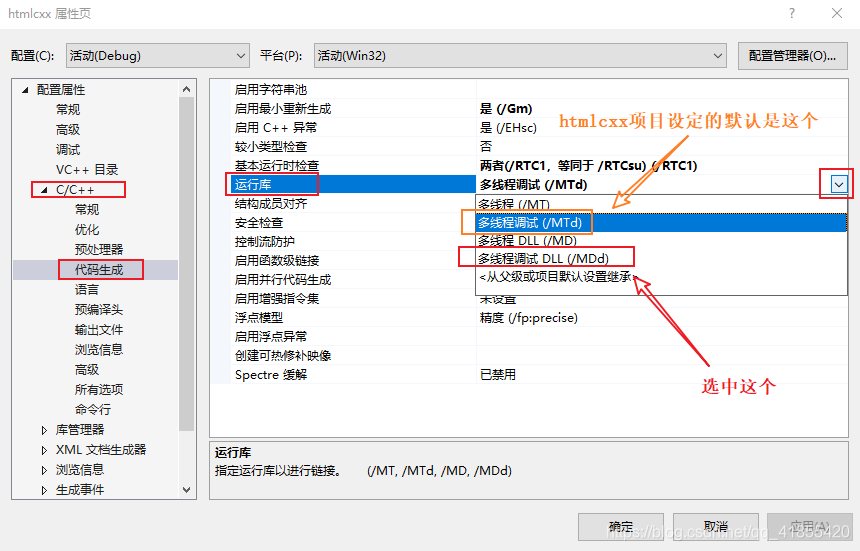
保存修改并退出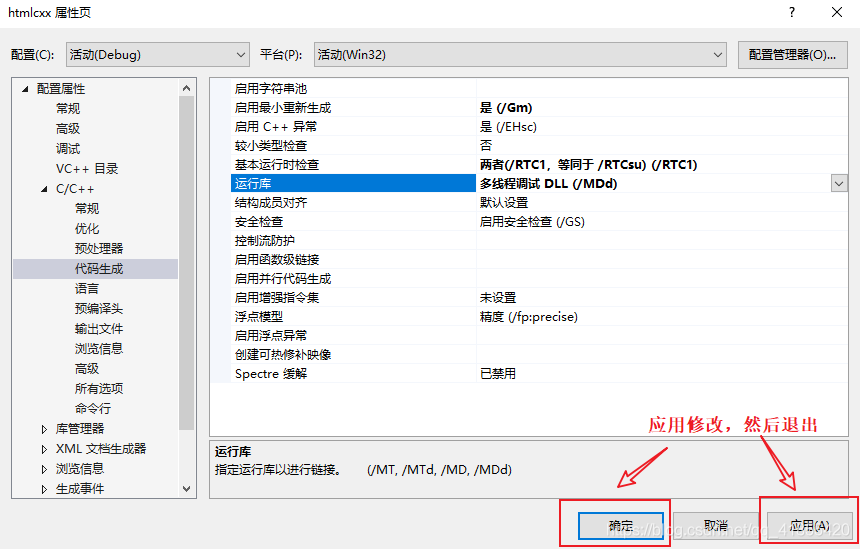
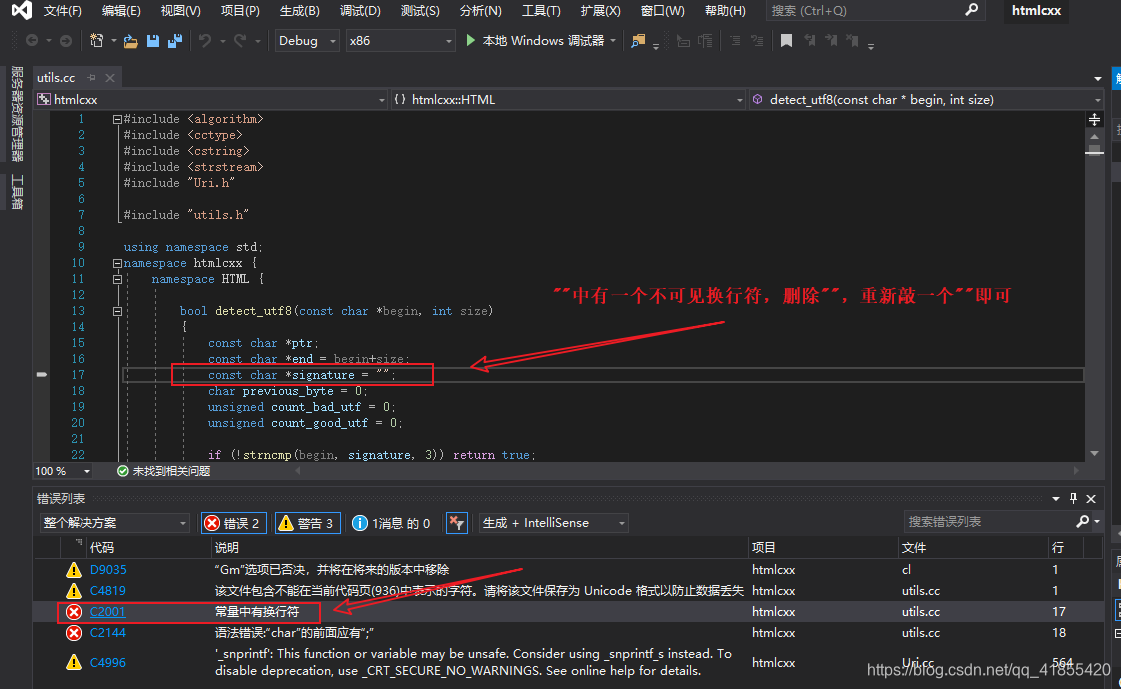
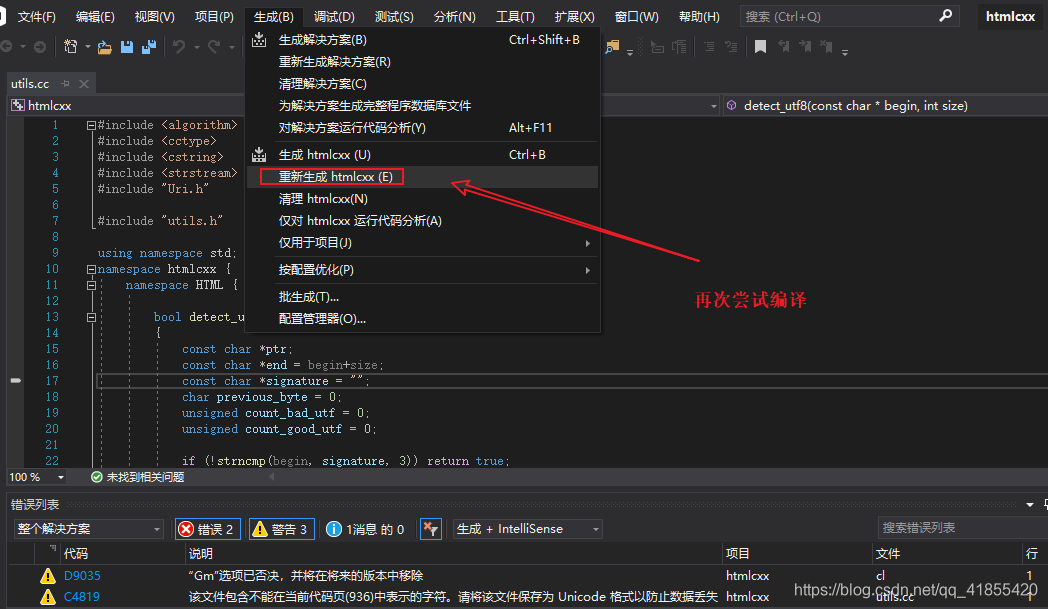
0.86的版本解决这些bug即可编译成功,其他版本可能还有其他Bug。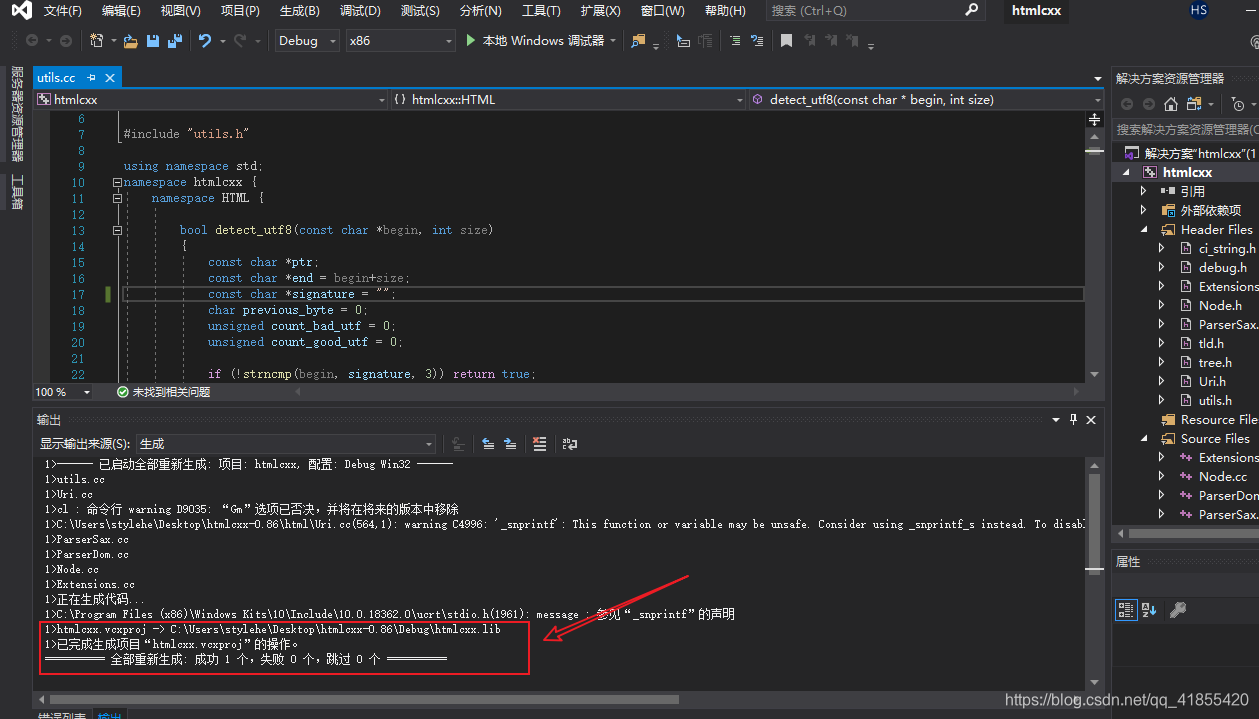
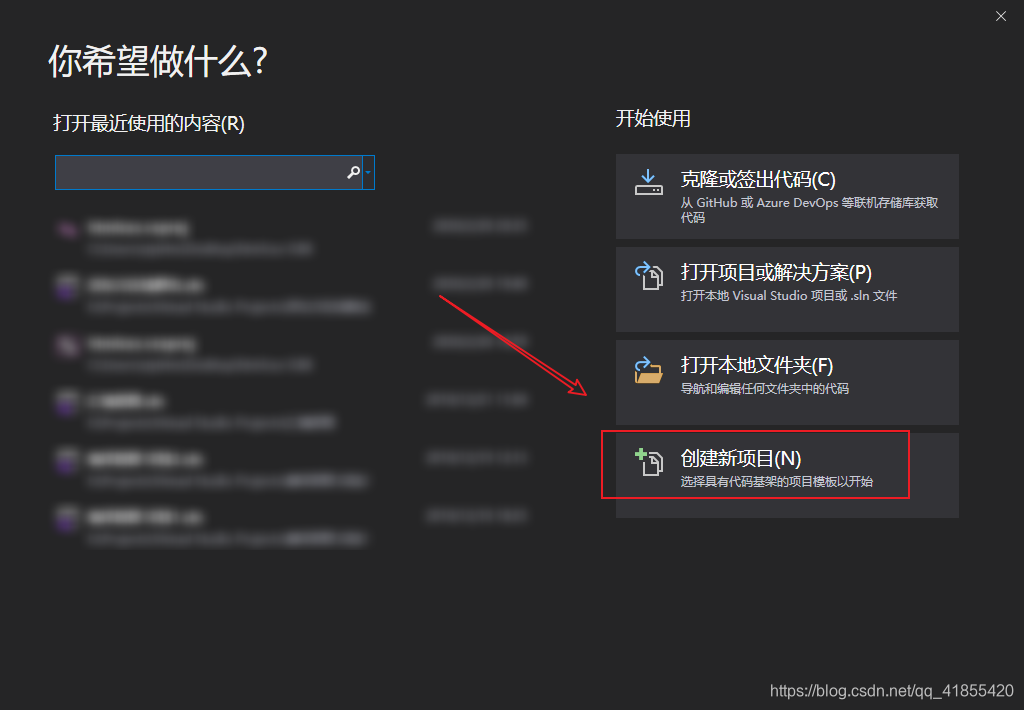
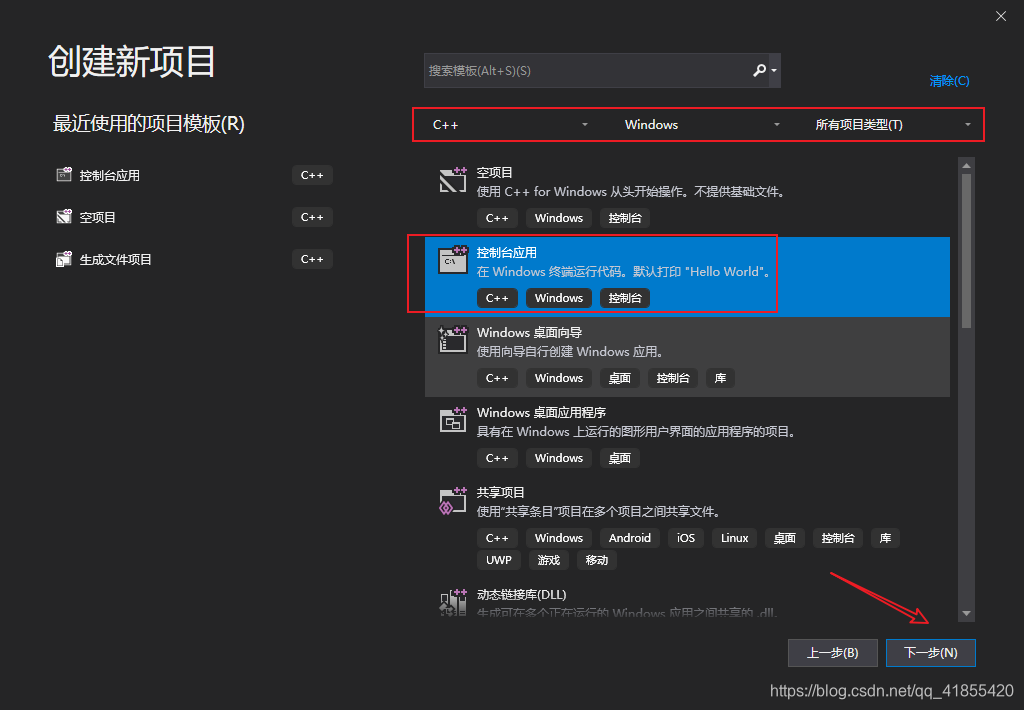
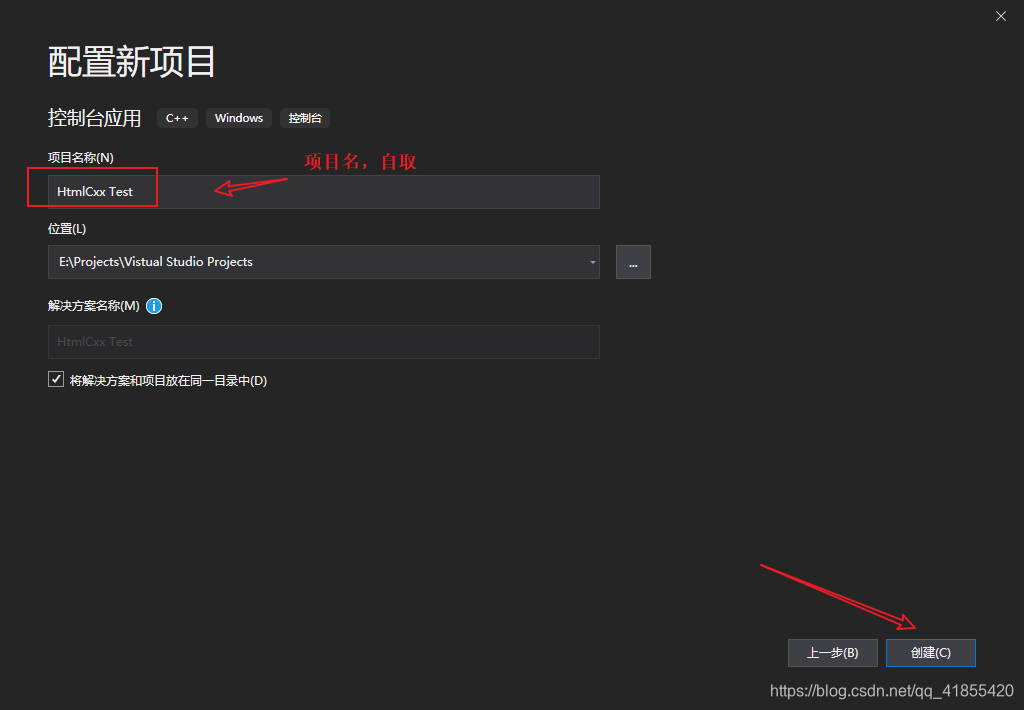
这里演示的是搭建过程,建议你先新建一个空白项目, 摸索请过程,再去应用到你实际的项目中!
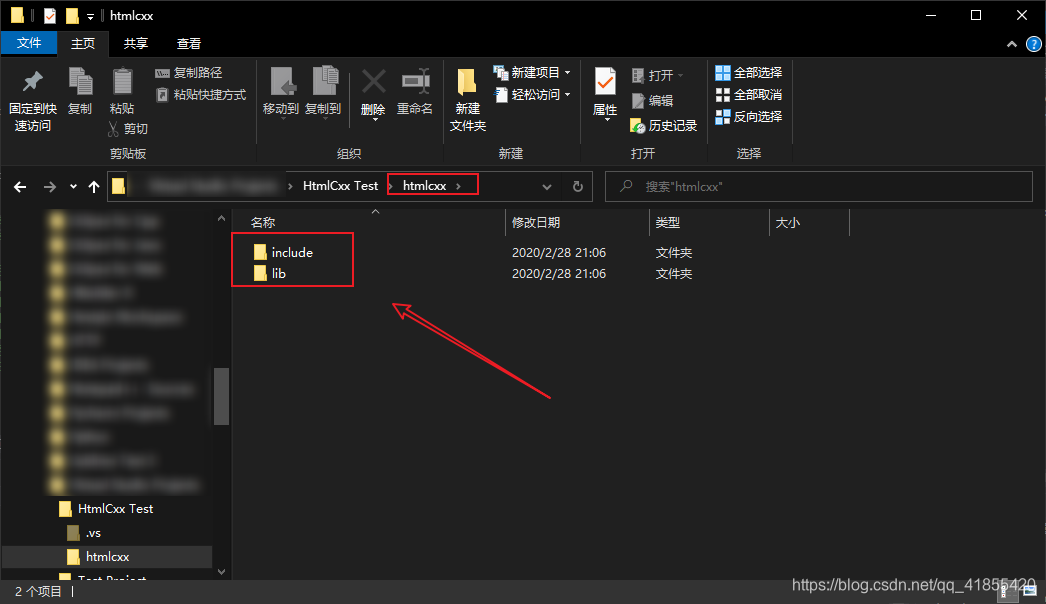

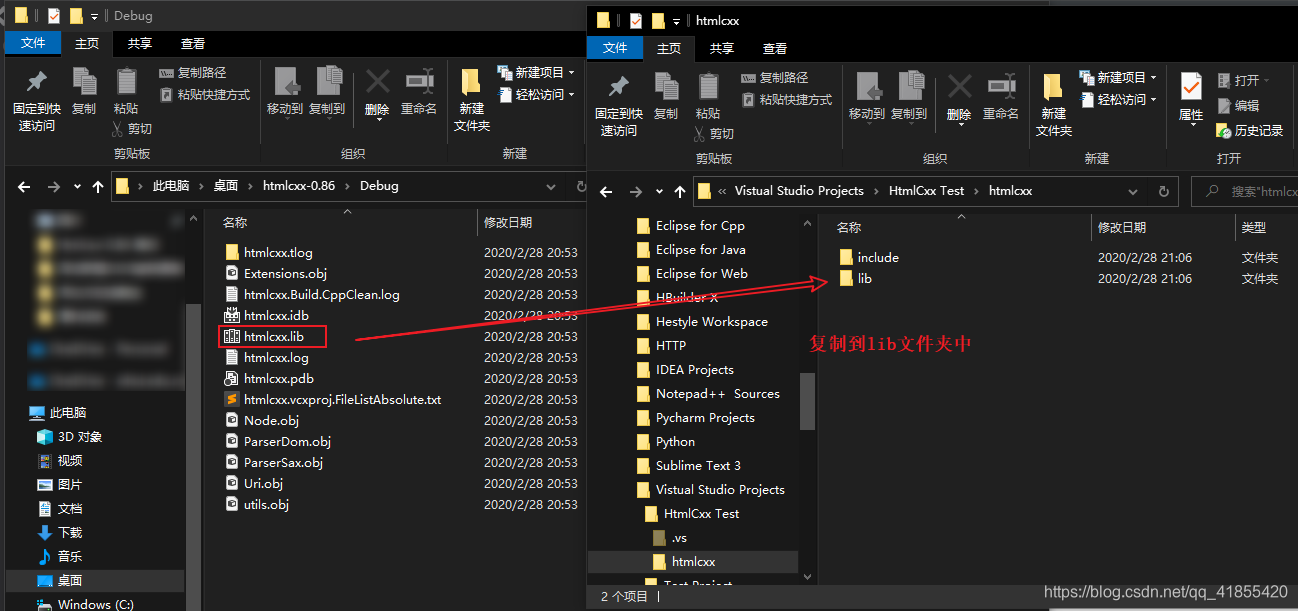
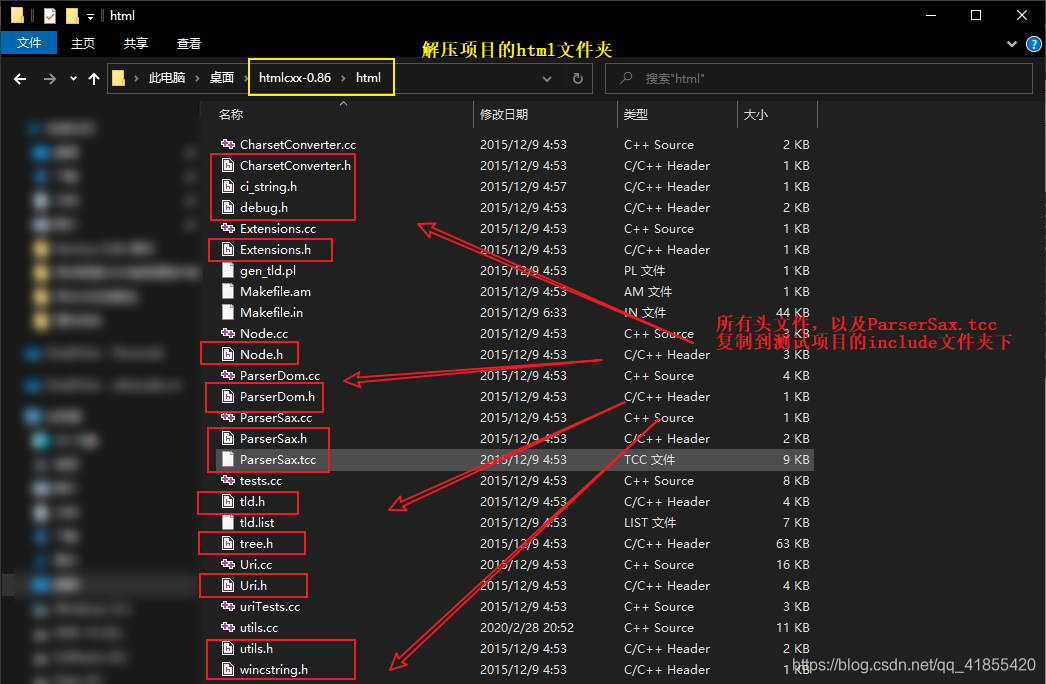
#include<string>
#include <iostream>
#include "htmlcxx/include/ParserDom.h"
using namespace std;
using namespace htmlcxx;
//加载htmlcxx.lib库
#pragma comment(lib,"htmlcxx/lib/htmlcxx.lib")
int main() {
//待解析的html数据
string html = "<div><span>hestyle</span><a href="https://hestyle.blog.csdn.net/">访问主页</a></div>";
//有些含有中文的html解析可能报错,需要添加这句
setlocale(LC_ALL, ".OCP");
HTML::ParserDom parser;
tree<HTML::Node> dom = parser.parseTree(html);
//遍历文档的迭代器
tree<HTML::Node>::iterator it = dom.begin();
tree<HTML::Node>::iterator end = dom.end();
//遍历整个dom
for (; it != end; ++it) {
//it->isTag()判断it指向的节点是否是标签
if (it->isTag()) {
//加载标签的属性
it->parseAttributes();
//it->tagName()获取标签的名字
//it->attribute("href")返回的是pair<bool,object>,first表示的该标签是否含有该属性,second是属性值
if (it->tagName() == "a" && it->attribute("href").first) {
cout << "hestyle的主页:" << it->attribute("href").second << endl;
}
}
}
return 0;
}
控制台输出结果: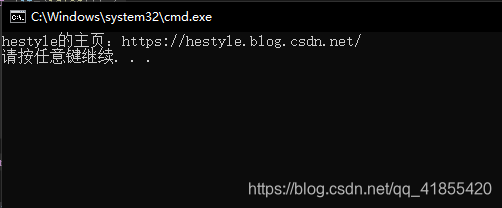
以上就是htmlcxx本地编译、vs环境搭建的主要过程,也演示了html解析的基本API,比如it->isTag()、it->tagName()、it->attribute("href"),其实只要知道这几个就足够了。这也真是htmlcxx的便捷、轻量特性。
更新了博客 C++ html解析库htmlcxx常见使用报错解决方法,如果你在配置过程遇到问题,可以参考一下。
更新了博客 C++ html解析库htmlcxx自封装的工具类(搜索标签),方便在解析html时搜索标签。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
