社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
目标网页路径:https://findicons.com/search/nature

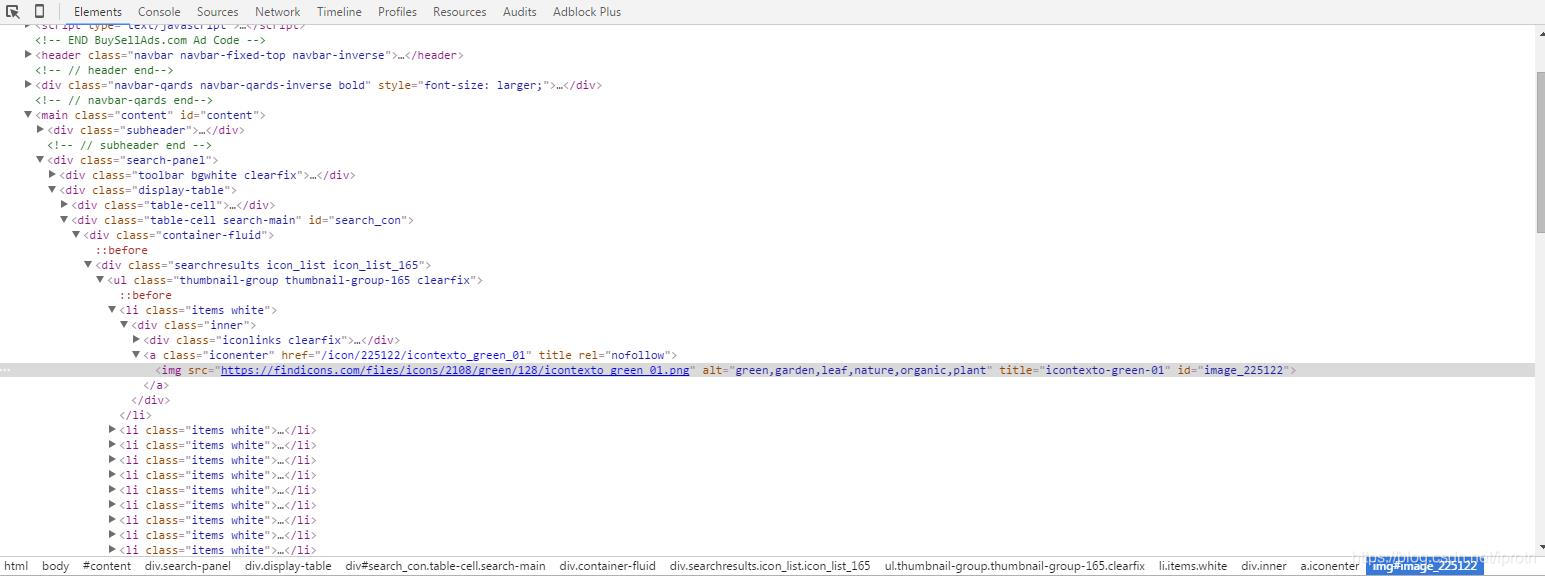
先分析查找要爬取图片的路径 在浏览器F12 审查元素
整体实现代码
# -- coding:UTF-8 --
import requests
from bs4 import BeautifulSoup
import os
'''
思路:获取网址
获取图片地址
爬取图片并保存
'''
# 获取网址
def getUrl(url):
try:
read = requests.get(url) #获取url
read.raise_for_status() #状态响应 返回200连接成功
read.encoding = read.apparent_encoding #从内容中分析出响应内容编码方式
return read.text #Http响应内容的字符串,即url对应的页面内容
except:
return "连接失败!"
# 获取图片地址并保存下载
def getPic(html):
soup = BeautifulSoup(html, "html.parser")
#通过分析网页内容,查找img的统一父类及属性
all_img = soup.find('ul', class_='thumbnail-group thumbnail-group-165 clearfix').find_all('img') #img为图片的标签
for img in all_img:
src = img['src'] #获取img标签里的src内容
img_url = src
print(img_url)
root = "F:/Pic/" #保存的路径
path = root + img_url.split('/')[-1] #获取img的文件名
print(path)
try:
if not os.path.exists(root): #判断是否存在文件并下载img
os.mkdir(root)
if not os.path.exists(path):
read = requests.get(img_url)
with open(path, "wb")as f:
f.write(read.content)
f.close()
print("文件保存成功!")
else:
print("文件已存在!")
except:
print("文件爬取失败!")
# 主函数
if __name__ == '__main__':
html_url=getUrl("https://findicons.com/search/nature")
getPic(html_url)
运行结果

爬取结果

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
