社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
初学爬虫的学习流程
python 3.6
使用 urlib库进行爬取内容
首先对百度进行爬取
# -*- coding: utf-8 -*-
import urllib.request
url = 'http://www.baidu.com'
resp = urllib.request.urlopen(url)
print(resp.read())使用urllib.request的urlopen()方法访问一个url。
输入服务器返回的内容。
b'<!DOCTYPE html>n<!--STATUS OK--><title>xe7x99xbexe5xbaxa6xe4xb8x80xe4xb8x8bxefxbcx8cxe4xbdxa0xe5xb0xb1xe7x9fxa5xe9x81x93</title>n rnrn<style id="css_index" index="index" type="text/css">html,body{height:100%}nhtml{overflow-y:auto}nbody{font:12px arial;text-align:;background:#fff}nbody,p,form,ul,li{margin:0;padding:0;list-style:none}nbody,form,#fm{position:relative}ntd{text-align:left}nimg{border:0}na{color:#00c}na:active{color:#f60}ninput{border:0;padding:0}n#wrapper{position:relative;_position:;min-height:100%}n#head{padding-bottom:100px;text-align:center;*z-index:1}n#ftCon{height:50px;position:absolute;bottom:47px;text-align:left;width:100%;margin:0 auto;z-index:0;overflow:hidden}n.ftCon-Wrapper{overflow:hidden;margin:0 auto;text-align:center;*width:640px}n.qrcodeCon{text-align:center;position:absolute;bottom:140px;height:60px;width:100%}n#qrcode{display:inline-block;*float:left;*margin-top:4px}n#qrcode .qrcode-item{float:left}n#qrcode .qrcode-item-2{margin-left:33px}n#qrcode .qrcode-img{width:60px;height:60px}n#qrcode .qrcode-item-1 .qrcode-img{background:url(http://s1.bdstatic.com/r/www/cache/static/home/img/qrcode/zbios_efde696.png) 0 0 no-repeat}n#qrcode .qrcode-item-2 .qrcode-img{background:url(http://s1.bdstatic.com/r/www/cache/static/home/img/qrcode/nuomi_365eabd.png) 0 0 no-repeat}n@media only screen and (-webkit-min-device-pixel-ratio:2){#qrcode .qrcode-item-1 .qrcode-img{background-image:url(http://s1.bdstatic.com/r/www/cache/static/home/img/qrcode/zbios_x2_9d645d9.png);background-size:60px 60px}n#qrcode .qrcode-item-2 .qrcode-img{background-image:url(http://s1.bdstatic.com/r/www/cache/static/home/img/qrcode/nuomi_x2_55dc5b7.png);background-size:60px 60px}}n#qrcode .qrcode-text{color:#999;line-height:23px;margin:3px 0 0}n#qrcode .qrcode-text a{color:#999;text-decoration:none}n#qrcode .qrcode-text p{text-align:center}n#qrcode .qrcode-text b{color:#666;font-weight:700}n#qrcode .qrcode-text span{letter-spacing:1px}n#ftConw{display:inline-block;text-align:left;margin-left:33px;line-height:22px;position:relative;top:-2px;*float:right;*margin-left:0;*position:static}n#ftConw,#ftConw a{color:#999}n#ftConw{text-align:center;margin-left:0}n.bg{background-image:url(http://s1.bdstatic.com/r/www/cache/static/global/img/icons_5859e57.png);background-repeat:no-repeat;_background-image:url(http://s1.bdstatic.com/r/www/cache/static/global/img/icons_d5b04cc.gif)}只贴出部分代码,可以看到爬取的内容是乱码的。
# -*- coding: utf-8 -*-
import urllib.request
url = 'http://www.baidu.com'
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))对输出进行utf-8的转码即可正常显示。
为了使我们的爬虫看起来更像是浏览器访问的我们一般对请求添加请求头信息。
不然可能会得到 403 Forbidden的网页信息
req = urllib.request.Request(target_url)
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36")这里添加了键为”User-Agent”的浏览器信息。
获取虎嗅首页html
import urllib
import urllib.request
url = 'https://www.huxiu.com'
def get_html(target_url):
req = urllib.request.Request(target_url)
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36")
response = urllib.request.urlopen(req)
return response.read().decode('utf-8')
html = get_html(url)
print(html)获得首页的html,在浏览器中打开爬取的html。
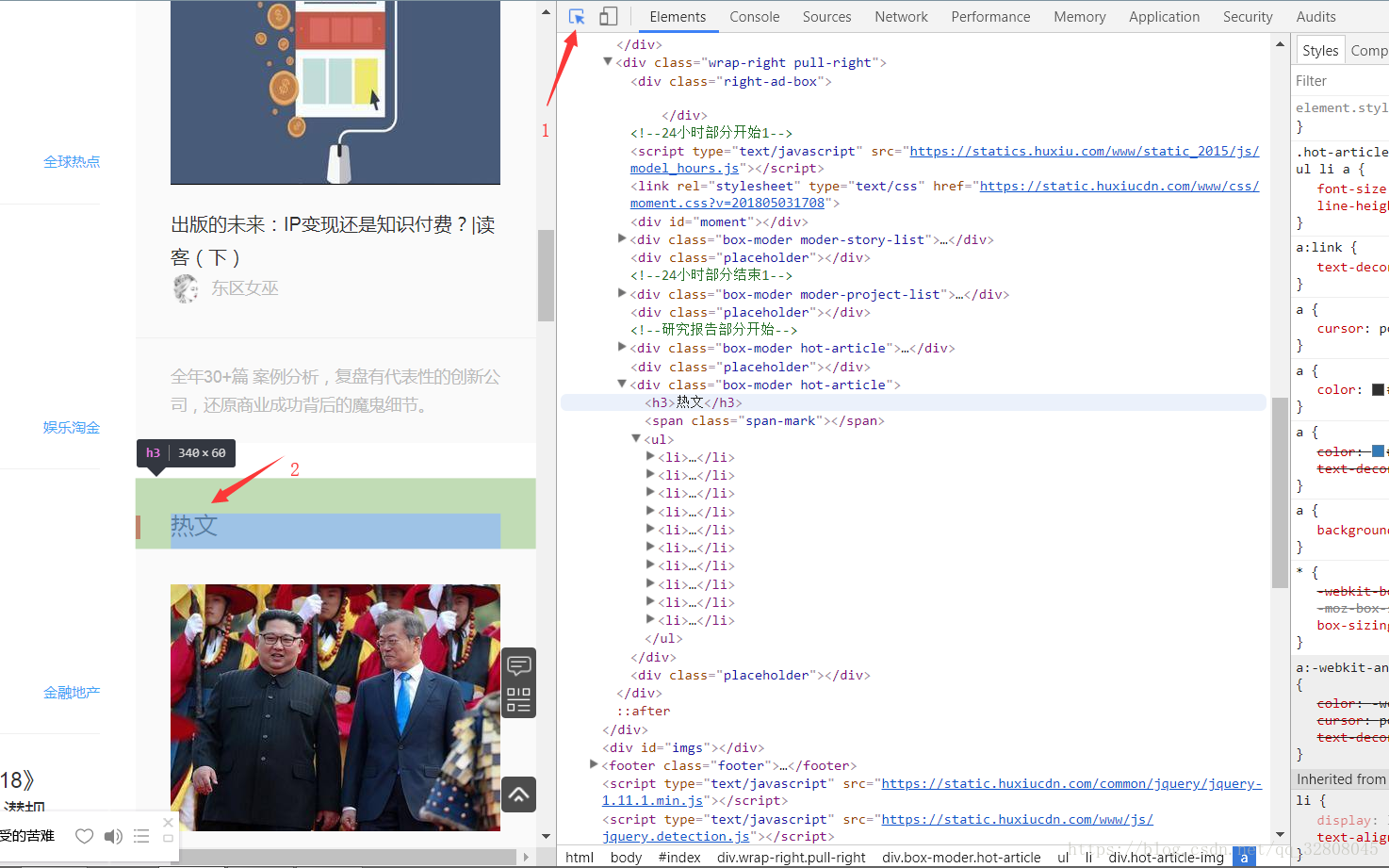
按下F12键进入开发者模式。
点击 1 处,然后点击网页中的任何地方就能跳到该元素所在的代码处,我们可以清楚的看见有一些 li 标签整齐的排列在其中。
可以发现每个 li 里面div块的css都是hot-article-img
利用BeautifulSoup库来对爬取到的html页面进行解析
def use_bs_get_list(html):
soup = BeautifulSoup(html, "html.parser") # use html.parser dissection
all_list = soup.select('.hot-article-img')
return all_list
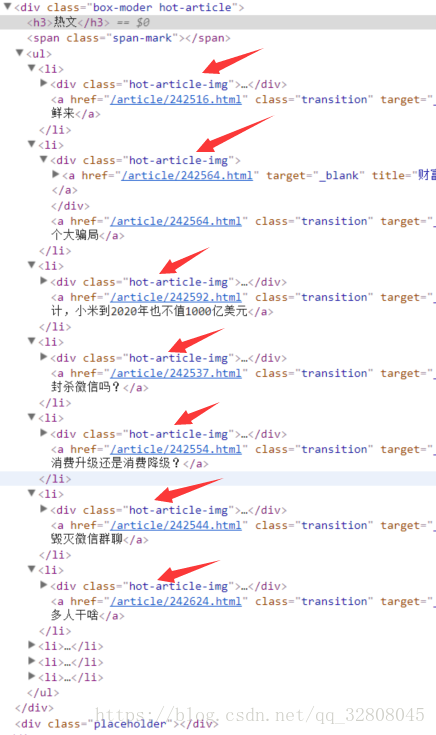
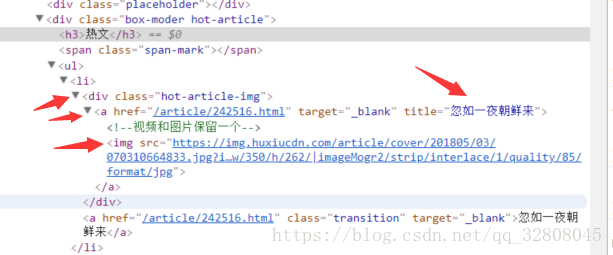
hot_article_list = use_bs_get_list(html)<div class="hot-article-img">
<a href="/article/242516.html" target="_blank" title="忽如一夜朝鲜来">
<!--视频和图片保留一个-->
<img src="https://img.huxiucdn.com/article/cover/201805/03/070310664833.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg"/>
</a>
</div>可以看到每一个class=”hot-article-img”的div块以list的元素输出。
解析list的每个item得到文章的img title url三个信息
def get_hot_article_img_title(all_list):
hot_article = []
for news in all_list:
# get <a ....>....</a>
a_tag = news.select('a')
# a[0]['title'] is none
if len(a_tag) > 0:
# article href
try:
href = url + a_tag[0]['href']
except Exception:
href = ''
# article img url
try:
# get img tag(inside a tag) img tag's src
img_url = a_tag[0].select('img')[0]['src']
except Exception:
img_url = ''
try:
title = a_tag[0]['title']
except Exception:
title = 'none'
hot_article.append("href:" + href + 'n' + "title:" + title + 'n' + "img_url:" + img_url + 'n')
return hot_article利用BeautifulSoup处理的list每一个项都是tag对象仍旧可以对其中的标签元素进行选择解析。
首先是得到div里的a标签应为有两个a标签所以我们选第一个也就是a_tag[0]。再利用a_tag[0][属性名]去选择a标签内某个属性的内容。
文章url在a标签的href内,当然还要和虎嗅的官网url拼接,文章名在title内,而文章图片的url是在a标签内部的img标签的src里。
href:https://www.huxiu.com/article/242516.html
title:忽如一夜朝鲜来
img_url:https://img.huxiucdn.com/article/cover/201805/03/070310664833.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg最后储存的项是这样的。
对网页html规律分析是十分重要的。
要练习爬取的网站是https://www.meitulu.com(-_-)
爬取热门美女这个列表
url = "https://www.meitulu.com"
def get_html(target_url):
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko)",
"Accept - Encoding": "gzip, deflate, br",
"Referer": "https://www.meitulu.com/"
}
req = urllib.request.Request(target_url, headers=headers)
response = urllib.request.urlopen(req)
content = response.read()
# b'<!' b=31
if content[0] == 31:
buff = BytesIO(content)
f = gzip.GzipFile(fileobj=buff)
res = f.read().decode('utf-8')
return res
# picture details is not gzip
return content.decode('utf-8')应为有网页是用gzip压缩的,所以这边有个判断。
def get_xiaojiejie_list(html, parsing_rules):
xiaojiejie_list = []
soup = BeautifulSoup(html, "html.parser")
tat_list = soup.select(parsing_rules)
tat_list = tat_list[0].select('li')
for var in tat_list:
url = var.select('a')[0]['href']
name = var.select('img')[0]['alt']
xiaojiejie_list.append({'name': name, 'url': url})
return xiaojiejie_list
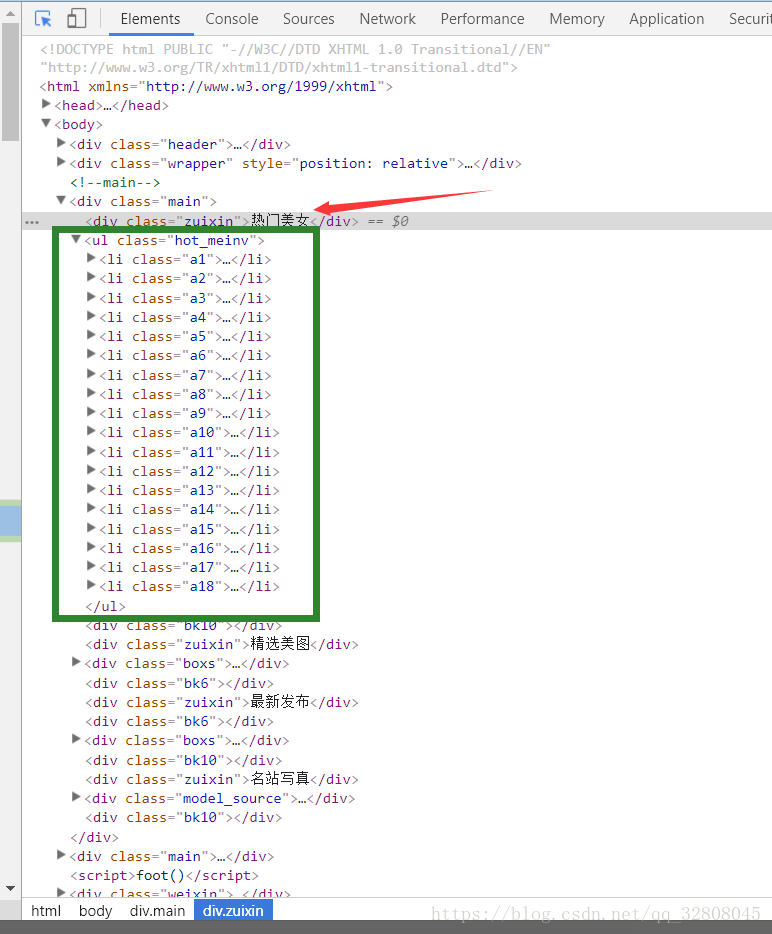
hot_gril_list = get_xiaojiejie_list(html, 'ul[class="hot_meinv"]')在html内容里获取class为hot_meinv的ul标签
构建元素项为字典类型(包含名字 和 对应的url)的list
{'name': '森下悠里', 'url': 'https://www.meitulu.com/t/yuuri-morishita/'},
{'name': '铃木爱理', 'url': 'https://www.meitulu.com/t/airi-suzuki/'},
{'name': '柏木由纪', 'url': 'https://www.meitulu.com/t/kashiwagi-yuki/'}获得了首页每个小姐姐url之后循环进入
这里只贴出一个的爬取方法。
可以看到每一个相册的url都安安静静的放在这里。
def go_to_photo_list(hot_girl_list):
for var in hot_girl_list:
path = 'picture/' + var['name']
if os.path.exists(path) is False:
os.mkdir(path, 777)
else:
continue
second_level_html = get_html(var['url'])
url_list = get_item_girl_img_list(second_level_html, 'ul[class="img"]')根据每个小姐姐的名字创建文件夹,有过的就不爬了。
然后获取小姐姐相册页的html。
这里导入一个os库,用来对文件夹进行操作。
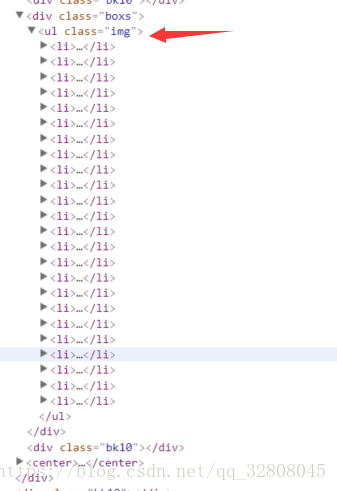
获得class=img的ul标签内所有的li并对其进行解析。
def get_item_girl_img_list(html, parsing_rules):
item_list = []
soup = BeautifulSoup(html, "html.parser")
tat_list = soup.select(parsing_rules)
tat_list = tat_list[0].select('li')
for var in tat_list:
url = var.select('a')[0]['href']
name = var.select('img')[0]['alt']
count = var.select('p')[0].text.split(' ')[1]
# count = var.select()
item_list.append({'name': name, 'url': url, 'count': count})
return item_list经过BeautifulSoup的筛选tat_list中只有一个内容就是ul标签及其里面的内容所以我们取tat_list[0]中的所有li
再对每个li进行解析 得到图片的url 相册名 以及相册中图片的数量
最终tat_list中的内容
[<li>
<a href="https://www.meitulu.com/item/6991.html" target="_blank"><img alt="[VYJ] No.114 柏木由紀 四刊全集套图[237]" height="300" src="https://mtl.ttsqgs.com/images/img/6991/0.jpg" width="220"/></a>
<p><span>16</span>图片: 237 张(1280X960)</p>
<p>机构: <a class="tags" href="https://www.meitulu.com/t/vyj/" target="_blank">VYJ</a></p>
<p>模特: <a class="tags" href="https://www.meitulu.com/t/kashiwagi-yuki/" target="_blank">柏木由纪</a></p>
<p>标签: <a class="tags" href="https://www.meitulu.com/t/ribenmeinv/" target="_blank">日本美女</a> <a class="tags" href="https://www.meitulu.com/t/qingchun/" target="_blank">清纯</a> <a class="tags" href="https://www.meitulu.com/t/tianmei/" target="_blank">甜美</a> <a class="tags" href="https://www.meitulu.com/t/meishaonv/" target="_blank">美少女</a> <a class="tags" href="https://www.meitulu.com/t/mengmeizi/" target="_blank">萌妹子</a></p>
<p class="p_title"><a href="https://www.meitulu.com/item/6991.html" target="_blank">[VYJ] No.114 柏木由紀 四刊全集套图</a></p>
</li>, <li>
<a href="https://www.meitulu.com/item/6980.html" target="_blank"><img alt="[VYJ] No.111 柏木由紀 Yuki Kashiwagi [22]" height="300" src="https://mtl.ttsqgs.com/images/img/6980/0.jpg" width="220"/></a>
<p><span>11</span>图片: 22 张(1280X960)</p>
<p>机构: <a class="tags" href="https://www.meitulu.com/t/vyj/" target="_blank">VYJ</a></p>
<p>模特: <a class="tags" href="https://www.meitulu.com/t/kashiwagi-yuki/" target="_blank">柏木由纪</a></p>
<p>标签: <a class="tags" href="https://www.meitulu.com/t/qingchun/" target="_blank">清纯</a> <a class="tags" href="https://www.meitulu.com/t/tianmei/" target="_blank">甜美</a> <a class="tags" href="https://www.meitulu.com/t/ribenmeinv/" target="_blank">日本美女</a> <a class="tags" href="https://www.meitulu.com/t/mengmeizi/" target="_blank">萌妹子</a></p>
<p class="p_title"><a href="https://www.meitulu.com/item/6980.html" target="_blank">[VYJ] No.111 柏木由紀 Yuki Kashiwagi </a></p>
</li>, ......li标签为list每个元素项
接下去是对list中每个item标签的解析
for item in url_list:
img_html = get_html(item['url'])
print('now we go to url:' + item['url'])
get_img(img_html, count, item['url'], var['name'], item['count'])
print('above name is:' + item['name'])
count = count + 1进如相册爬取图片。
第二页第三页等等,相册内之后的页数只要利用首页的url+”_页数”就好了。
def get_img(img_html, count, img_url, girl_name, img_count):
img_count = int(img_count)
img_list = []
i = 0
page = 2
path = 'picture/' + girl_name + '/' + str(count)
if os.path.exists(path) is False:
os.mkdir(path, 777)
target_url = img_url
target_url = target_url[:-5] + '_' + str(page) + '.html'
while i < img_count:
soup = BeautifulSoup(img_html, "html.parser")
img_url_list = soup.select('center')[0].select('img')
for var in img_url_list:
a = var['src']
i = i + 1
img_list.append(a)
if i < img_count:
# print(target_url)
# i = 38 but img_count = 40 but img only 38 so break
try:
img_html = get_html(target_url)
except urllib.error.HTTPError:
break
page = page + 1
target_url = target_url.split("_")[0] + "_" + str(page) + ".html"
save_img(img_list, path)
def save_img(img_list, path):
count = 0
for item in img_list:
if os.path.exists(path + '/' + str(count) + ".jpg") is False:
f = open(path + '/' + str(count) + ".jpg", 'wb')
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko)",
"Accept - Encoding": "gzip, deflate, br",
"Referer": "https://www.meitulu.com/"
}
req = urllib.request.Request(item, headers=headers)
try:
response = urllib.request.urlopen(req)
except urllib.error.HTTPError:
print('error again')
f.close()
save_img(img_list, path)
else:
if (response.status > 199 and response.status < 300):
try:
f.write(response.read())
except Exception:
print('save file error')
f.close()
count = count + 1
print('success')得到每张图片的url 爬下来保存到本地对应的文件夹中就好了。
文章从简到繁,虽然讲解不是特别细致,但主要是体现一下学习流程,关键还是自己的体会。代码
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!