社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
(一)安装selenium库
使用国内镜像安装,cmd窗口安装
pip3 install selenium -i -i https://pypi.douban.com/simple
(二)安装ChromeDriver
首先,先确定Chrome的版本,右上角三个点–》帮助–》关于Google Chrome,
然后,在 http://npm.taobao.org/mirrors/chromedriver/ 找到与版本对应的ChromeDriver
最后,将解压得到的chromedriver.exe 放到 Python安装目录的Script文件夹下
from selenium import webdriver
brower = webdriver.Chrome()
brower.get('https://www.baidu.com/')
运行代码,弹出谷歌浏览器,表示成功。
(一)声明浏览器对象
from selenium import webdriver
brower = webdriver.Chrome()
brower.get('https://www.baidu.com/')
(二)定位网页节点
通过属性id,name,class等,以及Xpath,css选择器进行定位
## 单个节点
find_element_by_id
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_tex
find_element_by_name(
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
这些方法都是调用通用方法
def find_element(self, by=By.ID, value=None):
## 两个参数:查找方式,值
多个节点
查找多个节点时,需要使用find_elements_by_xxxx方法,同样也有对应的通用调用方法
def find_elements(self, by=By.ID, value=None):
(三)节点交互
#输入文字
send_keys()
#清空文字
clear()
#点击按钮
click()
(四)执行JS
execute_script('js脚本')
(五)获取节点信息
通过定位节点的方法,可以得到一个WebElement对象,获取该对象包含属性的值
get_attribute(attr_name)
获取文本,直接调用text属性获取节点的文本值,除此之外,还有其他属性,id获取节点id;location获取节点在页面的相对位置;tag_name获取节点标签名称;size获取节点的宽高。
(六)延时等待
有时需要等待到某个节点加载完成,或者整个页面完成加载。这是需要延时等待一段时间,确保加载完成。等待的方式有两种,显式等待,隐式等待
显式等待
指定要等待的节点,等待的时间。如果在规定时间加载出节点,则返回改节点,若未加载出节点,则抛出异常。
wait = WebDriverWait(browser,10) #设置加载时间10s
#设置等待条件
wait.until(EC.presence_of_all_elements_located((By.XPATH,'//*[@id="Quater_bar"]/div/div[1]/h2/a/img')))
其他等待条件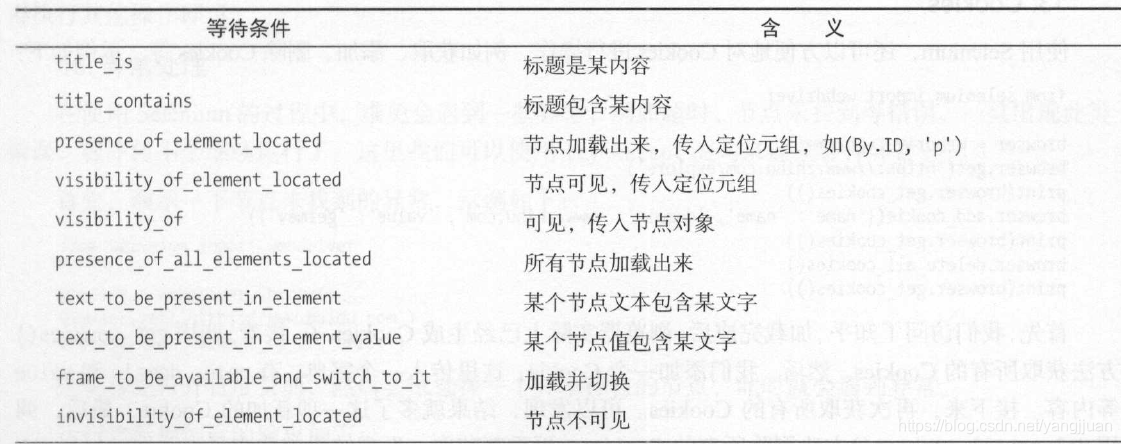

隐式等待
implictitly_wait(时长)
(七)页面选择
当brower打开多个页面可以
通过back()后退,选取当前页面的后一个页面
通过forward()前进,选取当前页面的前一个页面
(八)无界面模式
1,Chrome Headless模式无界面模式
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
2,PhantomJS()
下载地址:http://phantomjs.org/download.html
下载后解压,phantomjs.exe移到你所用python安装目录下的Script中就可以使用了。
from selenium import webdriver
from lxml import etree
browser = webdriver.PhantomJS()
browser.get("https://www.baidu.com/")
html = browser.page_source
doc = etree.HTML(html)
items = doc.xpath('//*[@id="u1"]/a')
for item in items:
print(item.text)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
