社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
上一篇博文中对100张验证码的识别率为43%,那么该如何提高识别率呢?也是就是如何让计算机可以准确识别图片里的文字内容?其实识别的过程,与我们识别图片的过程是类似的,一张无码高清图,并且教会你识别里面的内容,那么你一定可以一眼就识别出图片里的文字。
所以可以通过以下两种方式,提高图片文字的识别率:
1,提高图片清晰度,也就是祛除图片上无关的干扰点,高级词汇总结:去噪点,图像处理。
2,教会计算机识别文字,告诉它,字母A,B的形状是怎么样的,以后再看到这样形状的你就要认出来。高级词汇总结:训练,机器学习,深度学习。
从这两种方式深入研究,就进入了另外一个领域,机器视觉。然后就进入了人工智能领域了。但是我的目标目前不在这些领域,还是继续我爬虫研究吧,我使用的是些很简单粗暴直接的方法,
一,去噪点
对于孤立噪点可以使用八邻域算法降噪,算法一个像素点为中心,与周围八个像素点形成一个九宫格,如果是一个孤立黑色噪点,那么其周围八个相邻点全是白色。
def del_noise(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w, h = img.size
for y in range(1, h - 1):
for x in range(1, w - 1):
count = 0
if pixdata[x, y - 1] > 245:
count = count + 1
if pixdata[x, y + 1] > 245:
count = count + 1
if pixdata[x - 1, y] > 245:
count = count + 1
if pixdata[x + 1, y] > 245:
count = count + 1
if pixdata[x - 1, y - 1] > 245:
count = count + 1
if pixdata[x - 1, y + 1] > 245:
count = count + 1
if pixdata[x + 1, y - 1] > 245:
count = count + 1
if pixdata[x + 1, y + 1] > 245:
count = count + 1
if count > 7: # 控制领域判定大小
pixdata[x, y] = 255
return img
但是用了这个算法之后,识别正确率还是0.41。没有提高。说明二值化后的图片已经存在很少可以干扰识别的孤立噪点。
对于更复杂的噪点甚至干扰线和色块,有比较成熟的算法: 洪水填充法 Flood Fill ,或者泛水填充法。这个算法其实是图片颜色填充算法,类似是油漆桶功能。opencv提供了实现了这个算法的API。
floodFill(image, mask, seedPoint, newVal, loDiff=None, upDiff=None, flags=None)
找到一篇洪水填充法 Flood Fill去噪点的博客,思路是每扫描到一个黑色(灰度值为0)的点,就将与该点连通的所有点的灰度值都改为1,因此这一个连通域的点都不会再次重复计算了。下一个灰度值为0的点所有连通点的颜色都改为2,这样依次递加,直到所有的点都扫描完。接下来再次扫描所有的点,统计每一个灰度值对应的点的个数,每一个灰度值的点的个数对应该连通域的大小,并且不同连通域由于灰度值不同,因此每个点只计算一次,不会重复。这样一来就统计到了每个连通域的大小,再根据预设的阀值,如果该连通域大小小于阀值,则其就为噪点。该博客用C++实现,自己用Python实现了一波,这里要注意,在用OpenCV时,图片的矩阵点是反的,就是长和宽是颠倒的。
def del_noise(img):
color = 1
ColorCount = [0 for x in range(0, 256)]
h, w = img.shape[:2]
mask = np.zeros([h + 2, w + 2], np.uint8) # 新建图像矩阵 +2是官方函数要求
for y in range(0, w):
for x in range(0, h):
if img[x,y] == 0:
cv2.floodFill(img,mask,(y,x),(color))
color+=1
for y in range(0, w):
for x in range(0, h):
if img[x,y] != 255:
ColorCount[img[x,y]] +=1
for y in range(0, w):
for x in range(0, h):
if ColorCount[img[x,y]] <=1: #将阀值设置为1
img[x,y] = 255
else:
img[x,y] = 0
return img
用了这个算法之后,识别正确率还是0.39,觉得还是与预设的阀值,还有二值化时使用的阈值有关。使用不同值,得到的正确率也不同。
二,Tesseract-OCR样本训练
使用tesserocr识别处理后图片中的文字的,但是它依赖于Tesseract,通过Tesseract的tessdata来做识别,所以可以通过样本训练,得到专门的tessdata,以提高识别率。Tesseract的安装可以自行百度,并且需要安装jTessBoxEditor;
具体的步骤可以参考这篇博客很详细。
https://blog.csdn.net/sylsjane/article/details/83751297
使用训练后的tessdata:zhiwang,进行识别,正确率提高了不少,至少过50%,
text = tesserocr.image_to_text(img,lang = 'zhiwang')

在重新下载100张验证码进行识别,正确率也过了50%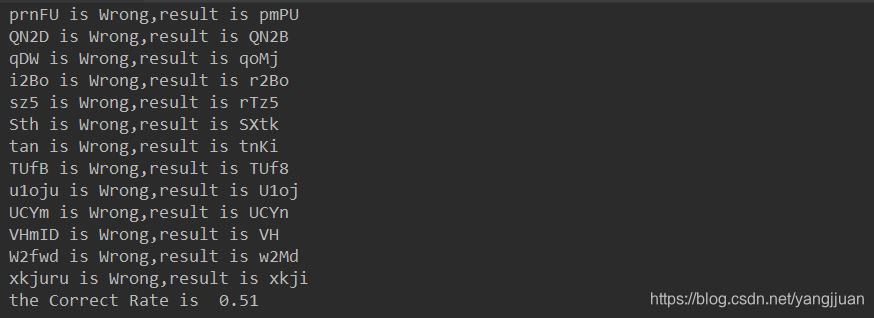
三,总结
验证码识别是网站的反爬虫手段之一,想做一套通吃的识别程序还是比较难的,现在也有好多文字识别的API可以调用,比如百度和阿里云的识别API,但是还是有几个问题可以思考的:
1,对图片进行二值化时的阈值,这个阈值要怎么得到才更加准确?
2,去噪点时,使用洪水填充法,这里用到阀值要怎么得到才更加准确?或者说使用更好的去噪点算法?
3,样本的训练的方法可以改进,使用特征向量,卷积网路,深度学习之类的
4,有没通吃的识别程序,识别正确率有没办法达到100%?
参考博客
https://blog.csdn.net/poem_qianmo/article/details/28261997
https://www.cnblogs.com/the-wolf-sky/articles/10106788.html
https://blog.csdn.net/jiaowozidaren/article/details/78452226
https://www.cnblogs.com/beer/p/5672678.html
https://www.jianshu.com/p/ec78a1419bae
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
