社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
该模块主要用来控制索引数据的读写方式,Lucene所有在磁盘上的操作都是通过store模块来处理的。
hybrid mmap / nio fs:默认类型,这种方式使用以上两种方式,为了减少对系统的影响,目前Lucene只在term directory和doc values文件映射到内存中。其他的情况都是用Lucene的NIOFSDirectory.
memory:对应Lucene中的RamIndexStore。将索引存放在Jvm堆空间之外内存中。
在索引期新文档会写入索引段。索引段是独立的Lucene索引,这意味着查询是可以与索引并行的,只是不时会有新增的索引段被添加到可被搜索的索引段集合之中。
一次提交并不足以保证新索引的数据能被搜索到,这是因为Lucene使用了一个叫作Searcher的抽象类来执行索引的读取。如果索引更新提交了,但Searcher实例并没有重新打开,那么它觉察不到新索引段的加入。Searcher重新打开的过程叫作刷新(refresh)。出于性能考虑,Lucene推迟了耗时的刷新,因此它不会在每次新增一个文档(或批量增加文档)的时候刷新,但Searcher会每秒刷新一次。这种刷新已经非常频繁了,然而有很多应用却需要更快的刷新频率。如果碰到这种状况,要么使用其他技术,要么审视需求是否合理。
ElasticSearch提供了两种机制来控制刷新的频率
临时强制刷新:
curl -XGET localhost:9200/test/refresh
配置文件配置:配置elasticsearch.xml 中的index.refresh_inverval
刷新操作是很耗资源的,因此刷新间隔时间越长,索引速度越快。如果需要长时间高速建索引,并且在建索引结束之前暂不执行查询,那么可以考虑将index.refresh_interval参数值设置为-1,然后在建索引结束以后再将该参数恢复为初始值。
事务日志中的信息与存储介质之间的同步(同时清空事务日志)称为事务日志刷新(flushing)。
请注意事务日志刷新与Searcher刷新的区别。
- Searcher刷新:为了搜索到最新的文档
- 事务日志刷新:用来确保数据正确写入了索引并清空了事务日志。
事务日志的刷新行为是可以自定义的。以下参数既可以通过修改elasticsearch.yml文件来配置,也可以通过索引配置更新API来更改。
频繁的文档更改操作会导致大量的小索引段,索引段数量过多会带来如下问题:
段合并可以带来以下好处:
默认提供了三种策略,可以通过index.merge.policy.type参数配置。
默认的策略。它合并大小相似的索引段。并考虑每层允许的索引段的最大个数。在索引期,该合并策略会计算索引中允许出现的索引段个数,该数值称为阈值(budget)。如果正在构建的索引中的段数超过了阈值,该策略将先对索引段按容量降序排序(这里考虑了被标记为已删除的文档),然后再选择一个成本最低的合并。合并成本的计算方法倾向于回收更多删除文档和产生更小的索引段。
如果某次合并产生的索引段的大小大于index.merge.policy.max_merged_segment参数值,则会选择更少的索引段参与合并,当多个分片时,默认的index.merge.policy.max_merged_segment则显得过小,从而降低了查询效率,需要进行调整。
该合并策略将会不断的以字节数的对数为计算单位,选择多个索引合并创建新索引。该合并策略能够保持较小的索引段数量并且极小化段索引合并代价。
该策略与log_byte_size合并策略类似,不同的是前者基于索引的字节数计算,后者基于索引段的文档数计算。当文档集中文档大小类似,或者期望参与合并的索引段在文档数方面相似时,表现较好。
这里只写tiered合并策略配置:
发合并调度器(ConcurrentMergeScheduler):该调度器使用多线程执行索引合并操作,其具体过程是:每次开启一个新线程直到线程数达到上限,当达到线程数上限时,必须开启新线程(因为需要进行新的段合并),那么所有索引操作将被挂起,直到至少一个索引合并操作完成。
为了控制最大线程数,可以通过修改index.merge.scheduler.max_thread_count属性来实现。一般来说,可以按如下公式来计算允许的最大线程数:
Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2))
(原则上,如果使用机械硬盘,该值最好设置为1)
段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O。合并在后台定期操作,因为他们可能要很长时间才能完成,尤其是比较大的段。这个通常来说都没问题,因为大规模段合并的概率是很小的。
不过有时候合并会拖累写入速率。如果这个真的发生了,Elasticsearch 会自动限制索引请求到单个线程里。这个可以防止出现 段爆炸 问题,即数以百计的段在被合并之前就生成出来。如果 Elasticsearch 发现合并拖累索引了,它会会记录一个声明有 now throttling indexing 的 INFO 级别信息。
默认值是 20 MB/s,对机械磁盘应该是个不错的设置。如果你用的是 SSD,可以考虑提高到 100–200 MB/s。测试验证对你的系统哪个值合适:
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
Elasticsearch中可以配置节点级别或是索引级别的throttle,可以配置的类型包括none(不做限制),merge(限制merge),all(限制所有操作),配置的策略包括max_bytes_per_sec.
如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。这样让你的索引速度跑到你磁盘允许的极限:
PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
过滤器缓存负责缓存查询中使用的过滤器的执行结果的。
过滤器缓存可以分为两类:
由于无法预知内存会被分配到哪里,这里不建议用索引级缓存。
节点级过滤器是默认的缓存类型,它应用于分配到给定节点上的所有分片(设置index.cache.filter.type属性为node,或者不设置属性),
通过indices.cache.filter.size属性可以配置缓存大小,默认为10%。
节点级过滤器缓存是LRU缓存,在删除缓存时,使用次数最少的那些会被删除。
倒排索引在搜索包含指定term的doc时非常高效,但是在相反的操作时表现很差:查询一个文档中包含哪些term。具体来说,倒排索引在搜索时最为高效,但在排序、聚合等与指定filed相关的操作时效率低下,需要用doc_values。
Doc values通过逆置term和doc间的关系来前面提到的数据聚合的问题。倒排索引将term映射到包含它们的doc,doc values将doc映射到它们包含的所有词项,下面是一个示例:

当数据被逆置之后,想要收集到 Doc_1 和 Doc_2 的唯一 token 会非常容易。获得每个文档行,获取所有的词项,然后求两个集合的并集。
其实,Doc Values本质上是一个序列化了的列式存储结构,非常适合排序、聚合以及字段相关的脚本操作。而且这种存储方式便于压缩,尤其是数字类型。压缩后能够大大减少磁盘空间,提升访问速度。
Doc Values是在字段索引时与倒排索引同时生成。Doc Values与倒排索引一样基于Segement生成并且是不可变的。Doc Values从操作系统页缓存中加载或弹出,从而避免发生内存溢出的异常。Doc Values默认对除了analyzed String外的所有字段启用(因为分词后会生成很多token使得Doc Values效率降低)。但是当你知道某些字段永远不会进行排序、聚合以及脚本操作的时候可以禁用Doc Values以节约磁盘空间提升索引速度。总结:
Doc Values的特点就是快速、高效、内存友好,使用由linux kernel管理的文件系统缓存弹性存储。doc values在排序、聚合或与字段相关的脚本计算得到了高效的运用,任何需要查找某个文档包含的值的操作都必须使用它。如果你确定某个filed不会做字段相关操作,可以直接关掉doc_values,节约内存,加快访问速度。
注意,已经设定了分词的String field不支持Doc Values,而是使用FieldData。
Doc values 是不支持 analyzed 字符串字段的,想象一下,如果一个字段是analyzed,如the first,则在分析阶段则会docvalues则会存储为两条docvalue(the和first),计算时候则会得到

而不是

那想要怎么达到我们想要的结果呢?fielddata。
doc values 不生成分析的字符串,然而,这些字段仍然可以使用聚合,是因为使用了fielddata 的数据结构。与 doc values 不同,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆。fielddata 是 所有 字段的默认设置。
FieldData缓存主要应用场景是在对某一个field排序或者计算类的聚合运算时。它会把这个field列的所有值加载到内存,这样做的目的是提供对这些值的快速文档访问。为field构建FieldData缓存可能会很昂贵,因此建议有足够的内存来分配它,并保持其处于已加载状态。
FieldData是在第一次将该filed用于聚合,排序或在脚本中访问时按需构建。FieldData是通过从磁盘读取每个段来读取整个反向索引,然后逆置term↔︎doc的关系,并将结果存储在JVM堆中构建的。
所以,加载FieldData是开销很大的操作,一旦它被加载后,就会在整个段的生命周期中保留在内存中。
ieldData.format可以配置FieldData是否开启,它默认是开启的。可以接受的参数是disabled和paged_bytes(就是启用)。加载fielddata默认是延迟加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
对于小索引段来说,这个过程的需要的时间可以忽略。但如果索引很大几个GB,这个过程可能会要数秒。对于 已经习惯亚秒响应的用户很难会接受停顿数秒卡顿。
有三种方式可以解决这个延时高峰:
FieldDataFieldData.loading参数可以控制FieldData加载到内存中的时机,有以下几个可选值:
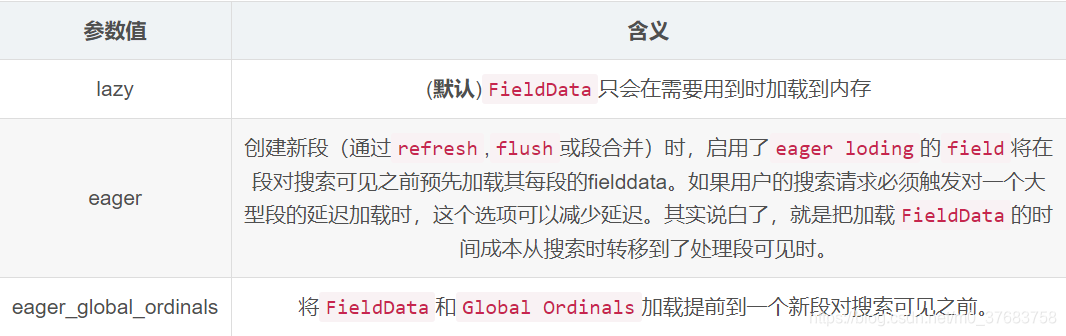
FieldData过滤器可以用来减少加载到内存的term数,因此就能减少内存使用。Terms可以被frequency(频率)和正则表达式或是他们的组合过滤。
frequency过滤:
有些无意义的数据都加载到内存中。所以,我们可以使用FildData的Frequency过滤器来避免这种情况。下面的示例筛选了至少包含500个doc的段,且只加载那些frequency大于1%且小于50%(过滤如停用词之类的常用词)的term到内存来生成FieldData:
PUT /music/_mapping/song
{
"properties": {
"tag": {
"type": "string",
"fielddata": {
"filter": {
"frequency": {
"min": 0.01,
"max": 0.5,
"min_segment_size": 500
}
}
}
}
}
}
使用正则表达式过滤:
这种方式可以只加载满足正则表达式的term。
注意:正则表达式只会对该field的所有term生效,而不是所有的field。
下面这个例子展示了只加载tweetfiled中hashtags(#号标签)开头的标签:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"tweet": {
"type": "string",
"analyzer": "whitespace",
"fielddata": {
"filter": {
"regex": {
"pattern": "^#.*"
}
}
}
}
}
}
}
}
JVM堆内存资源是非常宝贵的,能用好它对系统的高效稳定运行至关重要。FieldData是直接放在堆内的,所以必须合理设定用于存放它的堆内存资源数。ES中控制FieldData内存使用的参数是:
# 在ES_HOME/config/elasticsearch.yml中加入
# 控制最大fileldData缓存,可以用x%表示占该节点堆内存百分比,也可以用如12GB这样的数值
indices.fielddata.cache.size: 20%
默认状况下,这个设置是无限制的,ES不会从FieldData中驱逐数据。
如果生成的fielddata大小超过指定的size,则将驱逐其他值以腾出空间。使用时一定要注意,这个设置只是一个安全策略而并非内存不足的解决方案。因为通过此配置触发数据驱逐,ES会立刻开始从磁盘加载数据,并把其他数据驱逐以保证有足够空间,导致很高的IO以及大量的需要被垃圾回收的内存垃圾。
一般来说你最对最近几天数据感兴趣,很少查询老数据。但是,按默认设置FieldData中的老索引数据是不会被驱逐的。这样的话,FieldData就会一直持续增长直到触发熔断机制,这个机制会让你再也不能加载更多的FieldData到内存。这样的场景下,你只能对老的索引访问FieldData,但不能加载更多新数据。所以,这个时候就可以通过以上配置来把最近最少使用的FieldData驱逐以够新进来的数据腾空间。
注意,有一个类似的配置
indices.fielddata.cache.expire
请不要使用该配置,这个是仅凭过期否来判断是否驱逐,开销大,收益低,未来版本会删除掉。
当ES执行一个查询,查询会被发送给所有相关的分片,然后在每个分片上执行查询,然后查询结果会被发送至接收查询的节点进行合并。分片缓存时分片级的局部查询结果。
注意:分片缓存默认是关闭的,可以通过配置或调接口的方式改变:index.cache.query.enable: true
缓存持续增长会给ES资源带来很大的压力,ES会估算内存使用量,必要得到时候会拒绝执行查询。可以使用以下几种熔断器。
可以通过调用接口清除缓存。可以清除所有缓存,也可以清除指定索引的缓存,可以设置的缓存类型包括:field缓存,fielddata缓存,parent-child关系的缓存(为了清除缓存中代表parent-child关系的ID,可设置id_cache参数为true),查询分片缓存,实例如下所示:
##清除所有缓存
curl -XPOST 'localhost:9200/_cache/clear'
##清除指定索引缓存
curl -XPOST 'localhost:9200/mastering,book/_cache/clear'
##希望清除mastering索引的字段数据缓存,但是保留过滤器缓存和分片查询缓存
curl -XPOST 'localhost:9200/mastering/_cache/clear?field_data=true&filter=false&query_cache=false'
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
