社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
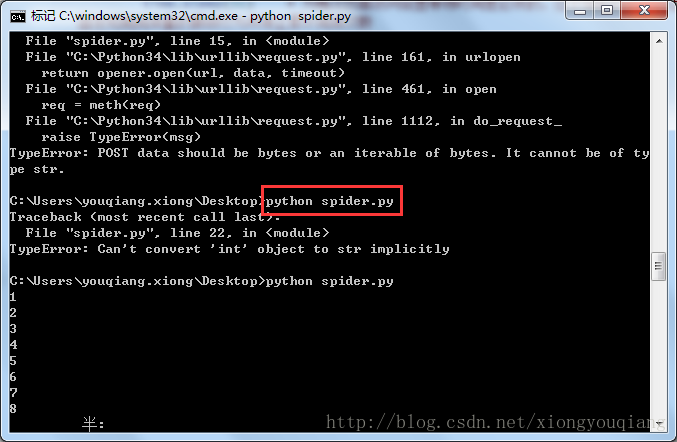
最近我开始写博客,后来发现博客文章的阅读量实际上是文章对应网页的被打开次数。于是我有了个想法:有没有什么办法,写一个for循环请求一直请求博客页面,这样微薄访问量不就上去了么,于是乎csnd上各种找资料,找到一篇关于用Python 写脚本实现的方式,觉得还不错,我完全按照博主的方法进行,下载Python3解释器,然后拷贝脚本代码,执行脚本,脚本会提示报各种各样的错误,后来发现博主的Python的脚本代码是基于Python2写的,而我下载的是Python3,所以执行脚本会报各种语法错误,基于此,我把之前2.0的代码升级改造了3.0的代码,成功执行。
因为Python官网下载速度特别慢,我放弃从官网下载,于是乎从csdn直接下载人家共享的文件 。
下载页面: http://download.csdn.net/download/fengge6715/6560269
下载后,随便放到一个根目录下面,然后解压,点击安装文件,一步一步直到安装完成。
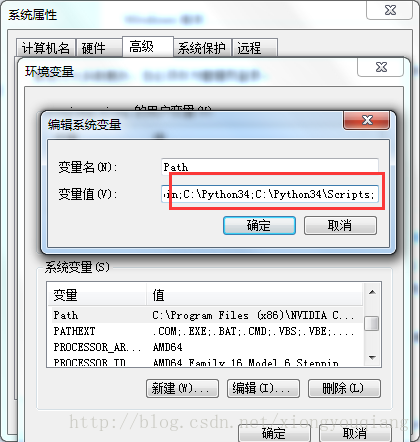
安装完成后,需要配置环境变量
1、安装根目录加入path路径下 (C:Python34)
2、Scripts目录加入path路径下(C:Python34Scripts)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib # Python中的cURL库
import urllib.request
from urllib import request,parse
import time # 时间函数库,包含休眠函数sleep()
url = 'http://blog.csdn.net/xiongyouqiang/article/details/77896435' # 希望刷阅读量的文章的URL
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' # 伪装成Chrome浏览器
refererData = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=csdn%20%E6%80%9D%E6%83%B3%E7%9A%84%E9%AB%98%E5%BA%A6%20csdnzouqi&oq=csdn%20%E6%80%9D%E6%83%B3%E7%9A%84%E9%AB%98%E5%BA%A6&rsv_pq=fe7241c2000121eb&rsv_t=0dfaTIzsy%2BB%2Bh4tkKd6GtRbwj3Cp5KVva8QYLdRbzIz1CCeC1tOLcNDWcO8&rqlang=cn&rsv_enter=1&rsv_sug3=11&rsv_sug2=0&inputT=3473&rsv_sug4=3753' #伪装成是从baidu.com搜索到的文章
dict ={
'name':'Germey'
}
data=bytes(parse.urlencode(dict),encoding='utf-8') # 将GET方法中待发送的数据设置为空
headers = {'User-Agent' : user_agent, 'Referer' : refererData} # 构造GET方法中的Header
count = 0 # 初始化计数器
req = urllib.request.Request(url, data, headers,method='POST') # 组装GET方法的请求
while 1: # 一旦开刷就停不下来
rec = urllib.request.urlopen(req) # 发送GET请求,获取博客文章页面资源
page = rec.read() # 读取页面内容到内存中的变量,这句代码可以不要
count += 1 # 计数器加1
print (count) # 打印当前循环次数
if count % 6: # 每6次访问为1个循环,其中5次访问等待时间为31秒,另1次为61秒
time.sleep(31) # 为每次页面访问设置等待时间是必须的,过于频繁的访问会让服务器发现刷阅读量的猥琐行为并停止累计阅读次数
else:
time.sleep(61)
print (page) # 打印页面信息,这句代码永远不会执行
将上面的代码复制保存到 spider.py文件中
执行命令:Python spider.py
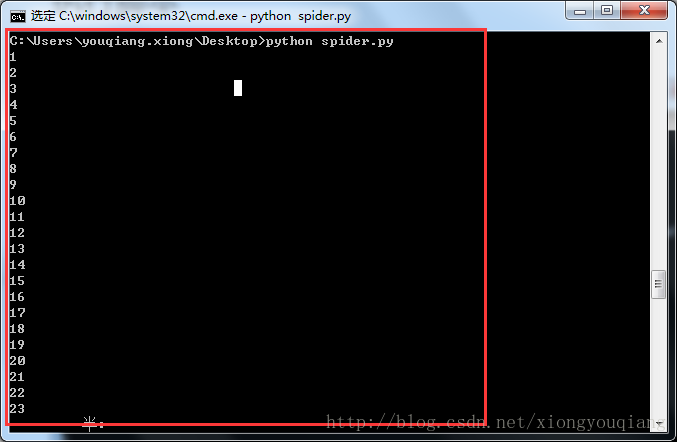
这样脚本命令就会一直在后台运行,并且会打印出请求的次数。
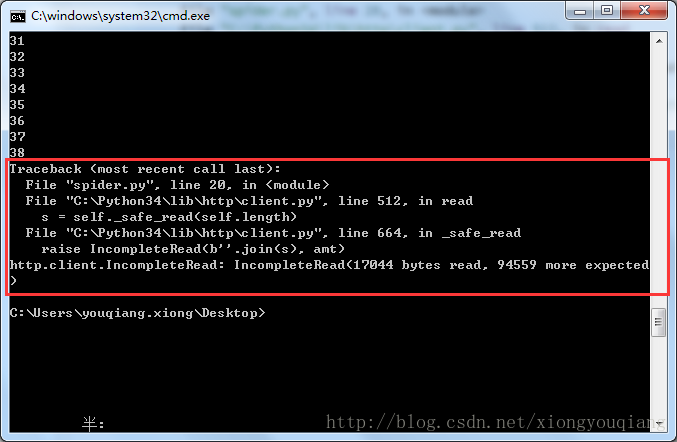
博客一直累计刷新中,博客次数从330 刷到了364 貌似速度特别慢,刷了38次,打印报错信息如下:
Traceback (most recent call last):
File "spider.py", line 20, in <module>
File "C:Python34libhttpclient.py", line 512, in read
s = self._safe_read(self.length)
File "C:Python34libhttpclient.py", line 664, in _safe_read
raise IncompleteRead(b''.join(s), amt)
http.client.IncompleteRead: IncompleteRead(17044 bytes read, 94559 more expected
)从上面的异常信息可以大概知道,请求超时,这应该是csdn服务器监控到,我这个ip地址持续请求同一篇博客,把我的ip地址加入到不合法的ip地址。其实这个问题也有解决方法,就是模拟生成一系列的ip地址,去发送请求,这样服务器就无法监控了。
动态生成ip去访问这个技术有待于后续研究。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!