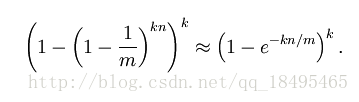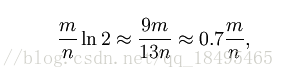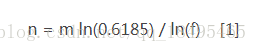社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
之前在重构一套文章爬虫系统时,其中有块逻辑是根据文章标题去重,原先去重的方式是,插入文章之前检查待插入文章的标题是否在ElasticSearch中存在,这无疑加重了ElasticSearch的负担也势必会影响程序的性能!
位数组和k个散列函数

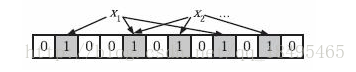
判断元素是否存在
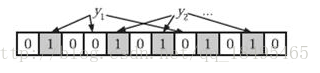
判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。
图中y1不是集合中的元素,y2属于这个集合或者是一个false positive。
BloomFilter有以下参数:
问题:如何根据输入元素个数n,确定位数组的大小m和哈希函数的个数k?
BloomFilter的f满足下列公式:
在给定m和n时,能够使f最小化的k值为:
此时给出的f为:
根据以上公式,对于任意给定的f,我们有:
同时,我们需要k个hash来达成这个目标:
由于k必须取整数,我们在Bloom Filter的程序实现中,还应该使用上面的公式来求得实际的f:
以上3个公式是程序实现Bloom Filter的关键公式。
故可以通过调节参数,使用Hash函数的个数,位数组的大小来降低失误率。
k和m的取法:
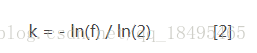

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!