社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Python实现:https://github.com/chfguo/bloomfilter
在进行布隆过滤器的介绍前,先说一下位数组(bit array)。所谓的位数组,主要是为了有效地利用内存空间而设计的一种存储数据的方式。在这种结构中一个整数在内存中用一位(1 bit)表示。这里所谓的表示就是如果整数存在,相应的二进制位就为 1,否则为 0。
布隆过滤器便利用了位数组的特性,它通过 hash 函数(为了降低 hash 函数的冲突效应,一般会选择多个随机的 hash 函数)将一个元素映射成一个位数组(Bit array)中的某些点上。在检索的时候,通过判断这些点是不是 1 来判读集合中有没有某个特定的元素。这就是布隆过滤器的基本思想。
举个例子,假设我们有 4 个元素 ‘cat’,‘dog’,‘pig’,‘bee’,选择 3 个 hash 函数,位数组长度为 10。为了方便说明,我们依次修改位数组的值。当插入第一个元素时 ‘cat’ 后,位数组变为: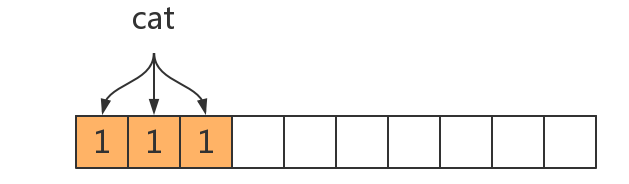
当插入 ‘dog’ 和 ‘pig’ 后,位数组变为: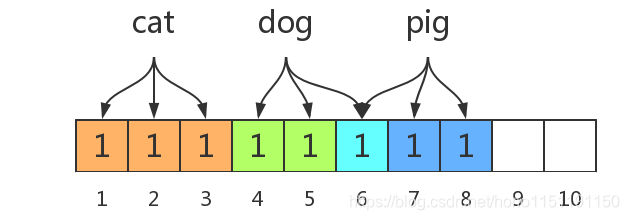
当我们查询 ‘bee’ 的时候,如果,‘bee’ 有一位或两位映射在 9,10 位上,则可以正确判断出元素 ‘bee’ 不在集合中,但是如果 ‘bee’ 被映射在 1-8 位上则会出现误判,并且随着元素增加,误判率会逐渐增加。
布隆过滤器的判断有以下特点:
上面的例子说明了布隆过滤器的插入过程和误判率的问题,在这个例子中涉及三个重要数值:
通过一定的计算(参考这里),可以计算出最优的 和 :
我们可以利用 char 数组实现位数组 char *bit_arr,对于一个数字,比如 26,它应该存放在这个 char 数组的第 4 个 char 中,即 bit_arr[3] 中, 如果按照高位在前,低位在后的顺序,它应该在 (26 & 0x7 + 1) 的位置, & 0x7 可以取得一个数字的二进制的最后三位,相当于取除 8 的余数,最后利用 1<< 将该位设置为 1。这样的获得的位数组是:7 6 5 4 3 2 1 0 – 15 14 13 12 11 10 9 8 – 23 22 21 20 19 18 17 16 – 31 30 29 28 27 26 25 24–…,如果要改正这个顺序,将 26 & 0x7 改为 7 - (26 & 0x7)
具体实现:
//插入函数
void add_to_bitarray(char *bitarr, uint64_t num){ /* num代表要插进数组中的数 */
// SHIFT = 3, num >> SHIFT 相当于 num/8
// MASK = 0x7, num & MASK 相当于取余数
bitarr[num >> SHIFT] |= (1 << (num & MASK));
}
//查询函数
int is_in_bitarray(char *bitarr, int num){
return bitarr[num >> SHIFT] & (1 << (num & MASK));
}
Hash 函数选用 MurmurHash。MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。已经被应用到很多开源项目如Redis,Memcached,Cassandra,HBase,Lucene等。与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。
具体实现:
uint64_t MurmurHash64A (const void * key, uint32_t len, uint64_t seed ){
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const unsigned char * data2 = (const unsigned char*)data;
switch(len & 7){
case 7: h ^= (uint64_t)(data2[6]) << 48;
case 6: h ^= (uint64_t)(data2[5]) << 40;
case 5: h ^= (uint64_t)(data2[4]) << 32;
case 4: h ^= (uint64_t)(data2[3]) << 24;
case 3: h ^= (uint64_t)(data2[2]) << 16;
case 2: h ^= (uint64_t)(data2[1]) << 8;
case 1: h ^= (uint64_t)(data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
包装下 MurmurHash64A,使获得的散列值在指定的长度内:
uint64_t hash(const char* data, uint32_t len, uint64_t seed, uint64_t bits) {
return MurmurHash64A(data, len, seed) % bits;
}
利用一个结构体存放布隆过滤器的一些设置参数:
typedef struct {
uint32_t capacity; //需要存放的元素个数
uint32_t hashes; //hash 函数的个数
uint64_t bits; //位数组的长度
float error; //误报率
uint64_t *seeds; //hash 函数的seed
} bloomfilterctxt;
bloomfilterctxt 的初始化和释放内存:
void init_bloomfilter(bloomfilterctxt * ctxt, uint32_t capacity, float error, int prime_length) { //prime_length是否将 bits 设置为素数长度
uint32_t i;
ctxt->capacity = capacity;
ctxt->bits = (uint64_t)(-(log(error) * capacity) / (log(2) * log(2)));
if (prime_length)
ctxt->bits = next_prime_number(ctxt->bits);
ctxt->hashes = (uint32_t)(ceil(log(2) * ctxt->bits / capacity));
ctxt->error = error;
ctxt->seeds = (uint64_t *)(malloc(ctxt->hashes * sizeof(uint64_t)));
uint32_t a = 1664525;
uint32_t c = 1013904223;
uint32_t x = 314159265;
for (i = 0; i < ctxt->hashes; ++i) {
ctxt->seeds[i] = x;
x = a * x + c;
}
}
void free_bloomfilter(bloomfilterctxt * ctxt) {
if (ctxt->seeds) {
free(ctxt->seeds);
}
}
int is_prime_number(uint64_t num){
if (num == 2) return 1;
if (num%2 == 0) return 0;
uint32_t i;
uint32_t len = (uint32_t)(sqrt((double)num)) + 1;
for (i = 3; i < len ; i+=2)
if (num%i == 0)
return 0;
return 1;
}
uint64_t next_prime_number(uint64_t num){
uint64_t i;
for (i = num; i < 2*num; i++)
if (is_prime_number(i))
return i;
return num;
}
实现插入和查询函数:
void add(char *bitmap, const char *data, uint32_t len, uint64_t *seeds, uint32_t hashes, uint64_t bits){
uint32_t i;
uint64_t position;
for(i=0; i<hashes; i++){
position = hash(data,len,seeds[i],bits);
bitmap[position >> SHIFT] |= (1 << (position & MASK));
}
}
int is_contain(char *bitmap, const char *data, uint32_t len, uint64_t *seeds, uint32_t hashes, uint64_t bits){
uint32_t i;
uint64_t position = hash(data,len,seeds[0],bits);
int result = bitmap[position >> SHIFT] & (1 << (position & MASK));
for(i=1; i<hashes; i++){
position = hash(data,len,seeds[i],bits);
result = result && (bitmap[position >> SHIFT] & (1 << (position & MASK)));
if(result == 0)
break;
}
return result;
}
//包装一下方便调用
void bf_add(bloomfilterctxt* ctxt, char *bitmap, const char *data, uint32_t len){
add(bitmap,data, len, ctxt->seeds, ctxt->hashes, ctxt->bits);
}
int bf_is_contain(bloomfilterctxt* ctxt,char *bitmap, const char *data, uint32_t len){
return is_contain(bitmap,data,len,ctxt->seeds, ctxt->hashes, ctxt->bits);
}
main.c函数
bloomfilterctxt ctxt;
int i;
//假设每个人推送1000个
uint32_t capacity = 1000;
float error = 0.05;
init_bloomfilter(&ctxt,capacity,error,1);
char *bitmap = (char*)calloc(ctxt.bits/8+1,sizeof(char));
char *data1 = "apple";
bf_add(&ctxt,bitmap,data1,5);
if(bf_is_contain(&ctxt,bitmap,data1,5))
printf("%s in bitmapn",data1);
else
printf("%s not in bitmapn",data1);
char *data2 = "banana";
bf_add(&ctxt,bitmap,data1,6);
if(bf_is_contain(&ctxt,bitmap,data2,6))
printf("%s in bitmapn",data2);
else
printf("%s not in bitmapn",data2);
结果:
apple in bitmap
banana not in bitmap
首先编辑一个 bloom.pyx 文件, 该文件中有个BloomFilter类,该类实现对相关C函数的调用。bitmap数组由 bytes 函数获的。
cdef extern from "bloomfilter.h":
ctypedef unsigned long int uint64_t
ctypedef unsigned int uint32_t
ctypedef struct bloomfilterctxt:
uint32_t capacity;
uint32_t hashes;
uint64_t bits;
float error;
uint64_t *seeds;
void clean_bitmap(char *bitmap, uint32_t len)
void free_bloomfilter(bloomfilterctxt * ctxt)
void init_bloomfilter(bloomfilterctxt * ctxt, uint32_t capacity, float error,bint prime_length)
void bf_add(bloomfilterctxt* ctxt,char *bitmap, const char *data, uint32_t len);
bint bf_is_contain(bloomfilterctxt* ctxt,char *bitmap, const char *data, uint32_t len);
uint64_t hash(const char* data, uint32_t len, uint64_t seed, uint64_t bits);
cdef class BloomFilter(object):
cdef bloomfilterctxt context
property bits:
def __get__(self):
return self.context.bits
property hashes:
def __get__(self):
return self.context.hashes
def __cinit__(self, capacity, error, prime_length = True):
init_bloomfilter(&self.context,capacity,error,prime_length)
def __dealloc__(self):
free_bloomfilter(&self.context)
def add(self,bitmap,data):
key = data.encode()
bf_add(&self.context, bitmap,key,len(key))
def is_contain(self,bitmap,data):
key = data.encode()
return bf_is_contain(&self.context, bitmap,key,len(key))
def clean_bitmap(self,bitmap):
clean_bitmap(bitmap, len(bitmap))
def hash(self,data):
key = data.encode()
offset = []
for i in range(self.hashes):
seed = self.context.seeds[i]
offset.append(hash(key,len(key),seed,self.context.bits))
return offset
包装一个 bloomfilter.py 文件,方便调用。
from BloomFilter import BloomFilter
class LocalBloomFilter():
def __init__(self,capacity,error,prime_length = True):
self.bf = BloomFilter(capacity,error,prime_length)
self.bitmap = bytes(int(self.bf.bits/8)+1)
def add(self,data):
if isinstance(data,(list,tuple)):
for v in data:
assert isinstance(v,str),'add() arg must be a str or list/tuple of strings'
self.bf.add(self.bitmap, v)
else:
assert isinstance(data, str), 'add() arg must be a str or list/tuple of strings'
self.bf.add(self.bitmap,data)
def is_contain(self,data):
if isinstance(data,(list,tuple)):
for v in data:
assert isinstance(v,str),'is_contain() arg must be a str or list/tuple of strings'
return [self.bf.is_contain(self.bitmap, v) for v in data]
else:
assert isinstance(data, str), 'is_contain() arg must be a str or list/tuple of strings'
return self.bf.is_contain(self.bitmap, data)
def clean(self):
self.bf.clean_bitmap(self.bitmap)
class RedisBloomFilter():
def __init__(self, capacity, error, redis_conn, prime_length=True):
self.bf = BloomFilter(capacity, error, prime_length)
self.redis_conn = redis_conn
def add(self, key, data):
if isinstance(data, (list, tuple)):
offset = []
for v in data:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
