社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
翻阅Netty的源码会发现Netty4.1(Netty5已废弃)中加入了对Http报头的预处理Handler,可见Netty团队对使用Netty作为web服务器的通信框架持鼓励态度。
的确,主流的Tomcat由于其诞生远早于Netty(那时连Java.nio都没有推出),已经不太可能将底层的架构改为Netty。而Netty作为Java.nio最受瞩目的开源框架,早晚会有基于其的web服务器发行。
那么Netty官方提供的HttpHandler是如何工作的呢?在官方的Example中可以看到这样一段代码:
package io.netty.example.http.file;
public class HttpStaticFileServerInitializer extends ChannelInitializer<SocketChannel> {
......
public void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
if (sslCtx != null) {
pipeline.addLast(sslCtx.newHandler(ch.alloc()));
}
pipeline.addLast(new HttpServerCodec());
pipeline.addLast(new HttpObjectAggregator(65536));
pipeline.addLast(new ChunkedWriteHandler());
pipeline.addLast(new HttpStaticFileServerHandler());
}
}这段代码负责初始化Tcp链接,对每个Tcp链接都会按以上的顺序往ChannelPipeline中添加Handler,并将这一Pipeline与Channel相绑定。
看一下除去SSLHandler外,其他公共的Handler是如何实现的。
首先加入ChannelPipeline的是HttpServerCodec(),从类的声明可见其继承了 CombinedChannelDuplexHandler<HttpRequestDecoder,HttpResponseEncode>
这个双向的Handler可以在msg的Inbound和Outbound时都起到处理数据的作用。数据Inbound时的业务逻辑由HttpRequestDecoder处理,
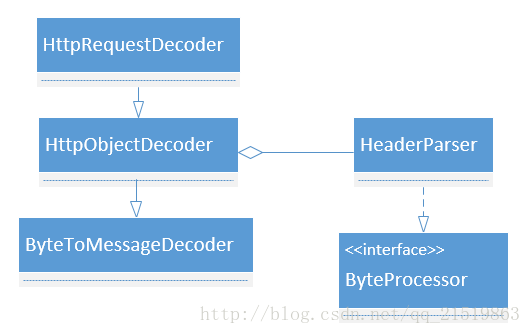
HttpObjectDecoder中负责header的具体解析,从UML图上可以看出,HttpObjectDecoder继承了ByteToMessageDecoder,在官网上ByteToessageDecoder有这样一段解释:If a custom frame decoder is required , then one needs to be careful when implementing one with ByteToMessageDecoder.
LinearParser是HttpObjectDecoder的内部类负责字符串的解析,看到其继承了HeaderParser,循着HeaderParser看到其实现了ByteProcessor接口,这里的实现其实还是比较复杂,贴上HeaderParser的代码
private static class HeaderParser implements ByteProcessor {
.....
public AppendableCharSequence parse(ByteBuf buffer) {
final int oldSize = size;
seq.reset();
int i = buffer.forEachByte(this);
if (i == -1) {
size = oldSize;
return null;
}
buffer.readerIndex(i + 1);
return seq;
}
public void reset() {
size = 0;
}
@Override
public boolean process(byte value) throws Exception {
char nextByte = (char) (value & 0xFF);
if (nextByte == HttpConstants.CR) {
return true;
}
if (nextByte == HttpConstants.LF) {
return false;
}
if (++ size > maxLength) {
throw newException(maxLength);
}
seq.append(nextByte);
return true;
}
}这里buffer.forEachBytes(this)是核心的代码,forEachBytes(this)可以接受实现了ByteProcessor的类。每次用bytebuf中取出一个byte传入process方法,这里就是通过this传入的HeaderParser类中的process方法。反复迭代直到process方法返回false为止,这里可以看到,遇到CR时虽然返回true但是不将其加入最后传出的字符串(seq),直到遇到LF表示迭代结束,将seq返回。
至此可以得到结论,每次headerparser以CR LF为关键字从header中提取出一行。
接下来是解析Http请求报文的具体流程,来到HttpObjectDecoder的decode部分,
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
if (resetRequested) {
resetNow();
}
switch (currentState) {
case SKIP_CONTROL_CHARS: {}
case READ_INITIAL: {}
case READ_HEADER: {}
case READ_VARIABLE_LENGTH_CONTENT: {}
case READ_FIXED_LENGTH_CONTENT: {}
case READ_CHUNK_SIZE: {}
case READ_CHUNKED_CONTENT:{}
case READ_CHUNK_DELIMITER: {}
case READ_CHUNK_FOOTER: {}
case BAD_MESSAGE: {}
case UPGRADED: {}
}
}由于篇幅的限制每个case中的具体逻辑都省略了,但是从case的名称还是可以看出每一部分具体负责什么。在这个类被初始化时,currentState会被初始化为SKIP_CONTROL_CHARS。每次decode函数都会接受由Lineparse传来的一行字符串,看到在解析头部时会有readinitial和readHeader为
部分这是因为Http的请求第一行通常为GET /sample.jsp HTTP/1.1之后的header格式为Accept-Language:zh-cn。可以看到两者格式不同,因此需要优不同的解析逻辑。之后对header中的contentlength与chunk部分进行解析。需要注意的是每一句case的最后都会有out.add(message),这句命令将解析完的message加入传到下个ChannelPipeline的数据结构中。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!