社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
# 写在前面:
本文章限于交流讨论,请不要使用文章的代码去攻击别人的服务器
如侵权联系作者删除
文中的错误已经修改过来了,谢谢各位爬友指出错误
在你复制本文章代码去运行的时候,请设置延迟,给自己留一条后路
转载请注明来源,谢谢
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import json
import csv
# 设置谷歌驱动器的环境
options = webdriver.ChromeOptions()
# 设置chrome不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(options=options)
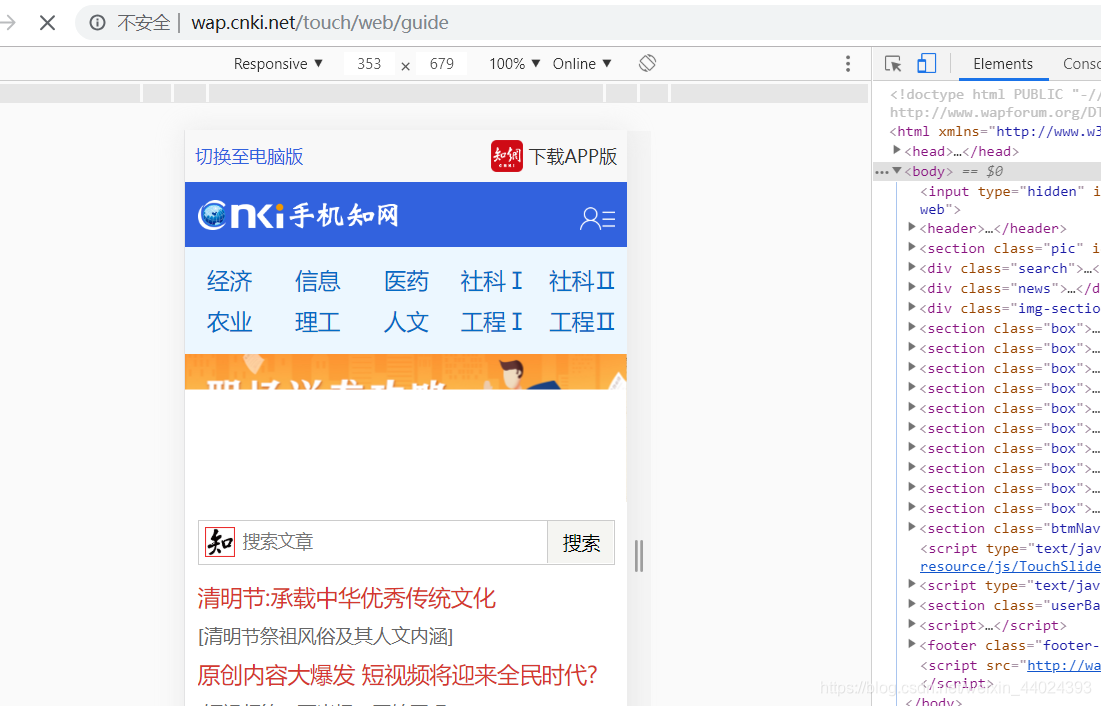
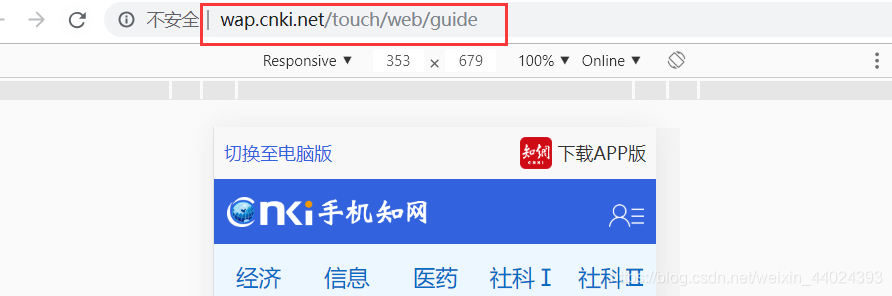
url = 'http://wap.cnki.net/touch/web/guide'

# 请求url
browser.get(url)
# 显示等待输入框是否加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, 'keyword')
)
)
# 找到输入框的id,并输入python关键字
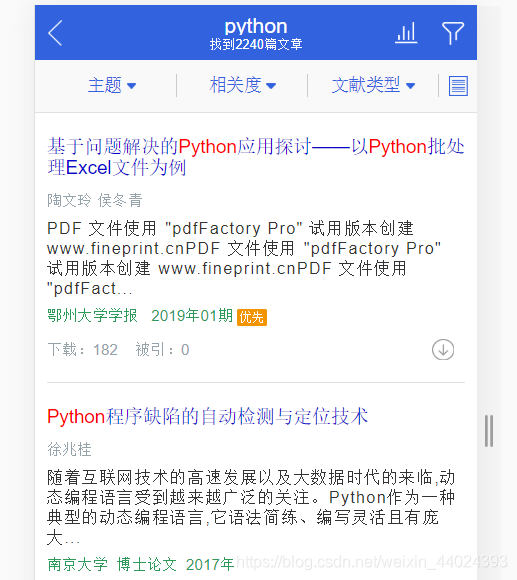
browser.find_element_by_id('keyword').send_keys('python')
# 输入关键字之后点击搜索
browser.find_element_by_id('btnSearch ').click()
# 显示等待文献是否加载完成
WebDriverWait(browser, 1000).until(
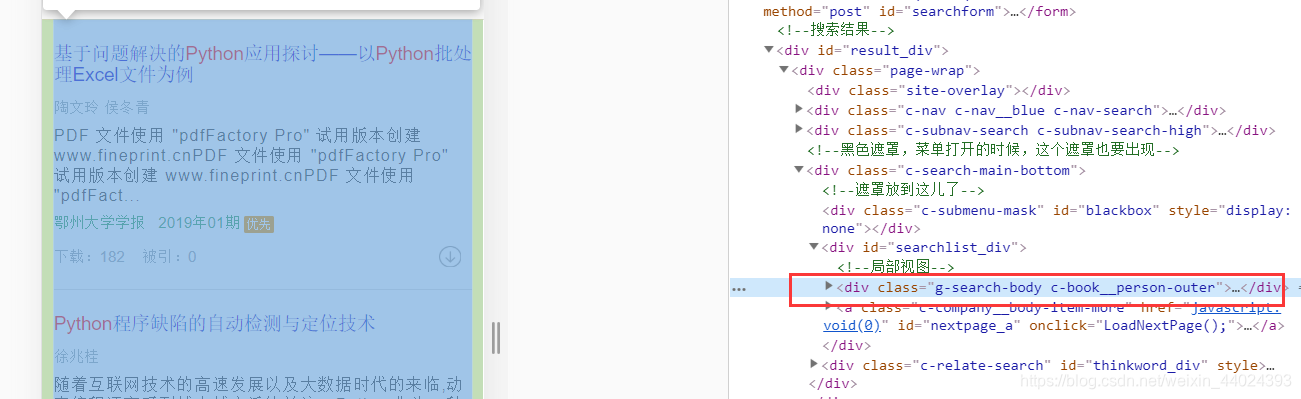
EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'g-search-body')
)
)
# 显示等待加载更多按钮加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
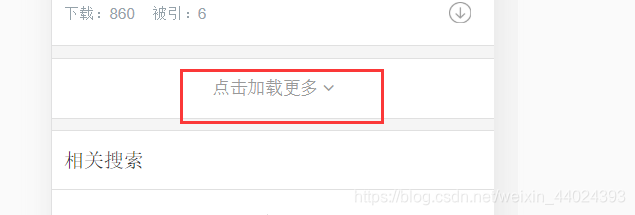
(By.CLASS_NAME, 'c-company__body-item-more')
)
)
# 获取加载更多按钮
Btn = browser.find_element_by_class_name('c-company__body-item-more')


from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from urllib.parse import urljoin
import time
import random
import json
import csv
# 设置谷歌驱动器的环境
options = webdriver.ChromeOptions()
# 设置chrome不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个谷歌驱动器
browser = webdriver.Chrome(options=options)
url = 'http://wap.cnki.net/touch/web/guide'
# 声明一个全局列表,用来存储字典
data_list = []
def start_spider(page):
# 请求url
browser.get(url)
# 显示等待输入框是否加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, 'keyword')
)
)
# 找到输入框的id,并输入python关键字
browser.find_element_by_id('keyword').click()
browser.find_element_by_id('keyword_ordinary').send_keys('python')
# 输入关键字之后点击搜索
browser.find_element_by_class_name('btn-search ').click()
# print(browser.page_source)
# 显示等待文献是否加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'g-search-body')
)
)
# 声明一个标记,用来标记翻页几页
count = 1
while True:
# 显示等待加载更多按钮加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.CLASS_NAME, 'c-company__body-item-more')
)
)
# 获取加载更多按钮
Btn = browser.find_element_by_class_name('c-company__body-item-more')
# 显示等待该信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.XPATH, '//div[@id="searchlist_div"]/div[{}]/div[@class="c-company__body-item"]'.format(2*count-1))
)
)
# 获取在div标签的信息,其中format(2*count-1)是因为加载的时候有显示多少条
# 简单的说就是这些div的信息都是奇数
divs = browser.find_elements_by_xpath('//div[@id="searchlist_div"]/div[{}]/div[@class="c-company__body-item"]'.format(2*count-1))
# 遍历循环
for div in divs:
# 获取文献的题目
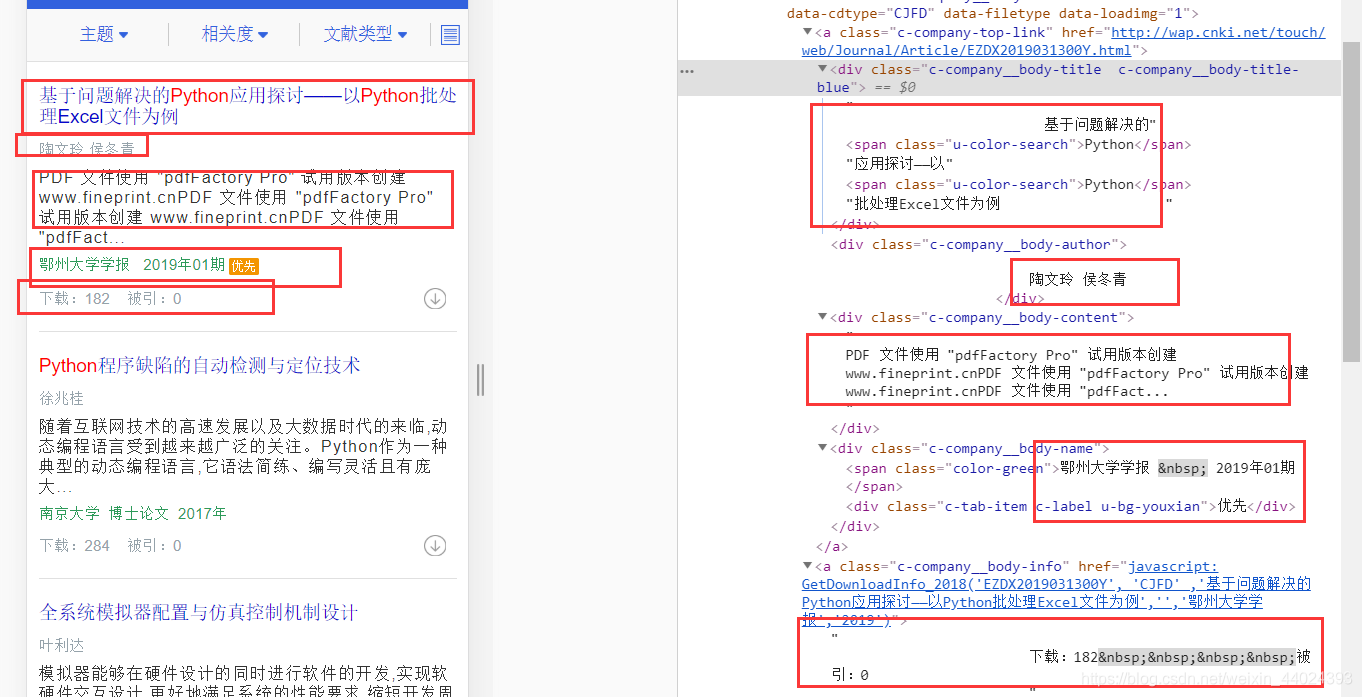
name = div.find_element_by_class_name('c-company__body-title').text
# 获取文献的作者
author = div.find_element_by_class_name('c-company__body-author').text
# # 获取文献的摘要
# content = div.find_element_by_class_name('c-company__body-content').text
# 获取文献的来源和日期、文献类型等
text = div.find_element_by_class_name('c-company__body-name').text.split()
if (len(text) == 3 and text[-1] == '优先') or len(text) == 2:
# 来源
source = text[0]
# 日期
datetime = text[1]
# 文献类型
literature_type = None
else:
source = text[0]
datetime = text[2]
literature_type = text[1]
# 获取下载数和被引数
temp = div.find_element_by_class_name('c-company__body-info').text.split()
# 下载数
download = temp[0].split(':')[-1]
# 被引数
cite = temp[1].split(':')[-1]
# ----------2020-3-18修改----------#
# 文献链接
link = div.find_element_by_class_name('c-company-top-link').get_attribute('href')
# 拼接
link = urljoin(browser.current_url, link)
# 获取关键字(需要访问该文献,url就是上面获取到的link)
# browser.get(link) # 这行和下面那行不推荐使用,因为句柄的问题,会报错
# browser.back()
# 打印查看下未访问新窗口时的句柄
# print(browser.current_window_handle)
js = 'window.open("%s");' % link
# 每次访问链接的时候适当延迟
time.sleep(random.uniform(1, 2))
browser.execute_script(js)
# 打印查看窗口的句柄,对比看下当前的句柄是哪个
# 结果是原先窗口的句柄,而不是新打开窗口的句柄,因为和上面打印的句柄一样
# print(browser.current_window_handle)
# 切换句柄到新打开的窗口,browser.window_handles是查看全部的句柄
# browser.switch_to_window是切换句柄
browser.switch_to_window(browser.window_handles[1])
# 获取关键字(使用xpath)
key_worlds = browser.find_elements_by_xpath('//div[@class="c-card__paper-name"][contains(text(), "关键词")]/following-sibling::div[1]/a')
key_worlds = ','.join(map(lambda x: x.text, key_worlds))
# ----------2020-3-19修改----------#
# 获取文献的摘要
content = browser.find_element_by_class_name('c-card__aritcle').text
# ----------2020-3-19修改----------#
# 获取信息完之后先关闭当前窗口再切换句柄到原先的窗口
browser.close()
browser.switch_to_window(browser.window_handles[0])
# 注:切换句柄参考该文章,感谢该博主:https://blog.csdn.net/DongGeGe214/article/details/52169761
# ----------2020-3-18修改----------#
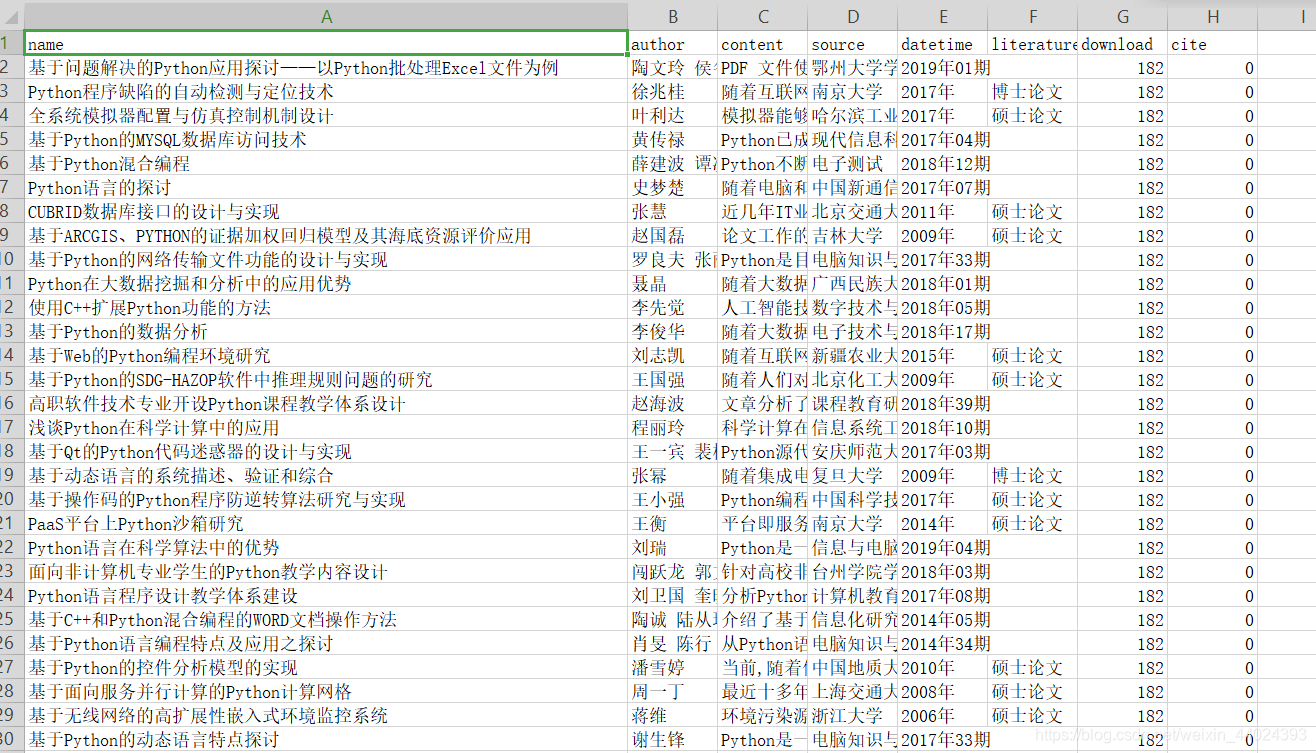
# 声明一个字典存储数据
data_dict = {}
data_dict['name'] = name
data_dict['author'] = author
data_dict['content'] = content
data_dict['source'] = source
data_dict['datetime'] = datetime
data_dict['literature_type'] = literature_type
data_dict['download'] = download
data_dict['cite'] = cite
data_dict['link'] = link
data_dict['key_worlds'] = key_worlds
data_list.append(data_dict)
print(data_dict)
# 如果Btn按钮(就是加载更多这个按钮)没有找到(就是已经到底了),就退出
if not Btn:
break
else:
Btn.click()
# 如果到了爬取的页数就退出
if count == page:
break
count += 1
# 延迟两秒,我们不是在攻击服务器
time.sleep(2)
# 全部爬取结束后退出浏览器
browser.quit()
def main():
start_spider(eval(input('请输入要爬取的页数(如果需要全部爬取请输入0):')))
# 将数据写入json文件中
with open('data_json.json', 'a+', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer对象
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ == '__main__':
main()
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
