社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
“温故而知新!”
在实验室师兄的要求下,我在去年花了很长一段时间学习并实现了实验室师兄的一篇毕业论文(胡剑青. 基于深度学习的方面级别评论情感分析[D]. 浙江大学, 2014.),因此才接触到了神经网络与深度学习这个领域。
由于遗留下的部分代码是用matlab写的,因此我在实现这篇论文的时候,深度学习的这块代码也是用matlab来写的,由于对matlab不甚了解,用起来也不大习惯,因此遇到了不少坑,但照着UFLDL TUTORIAL, 也总算完成了任务,只是大部分是在照猫画虎,对后向传播算法中的一些公式理解的还不够透彻。
最近在学习循环神经网络的过程中搜到了一篇文章,IMPLEMENTING A NEURAL NETWORK FROM SCRATCH IN PYTHON – AN INTRODUCTION,讲解的也非常详细,于是用python实现了下,其中同样遇到了些问题,通过查找这些问题的答案,我之前对后向传播算法的一些疑问也得到了解答。
本文的目标读者是对神经网络以及后向传播算法有一定了解,但理解的不太透彻的同学,如果你还没有接触过这些知识,请依次参考以下两个入门教程,本文的主要工作与讨论也是基于这两个教程展开的。
本文用python分别基于UFLDL TUTORIAL以及IMPLEMENTING A NEURAL NETWORK FROM SCRATCH IN PYTHON – AN INTRODUCTION实现了两个神经网络来完成同一个任务,这两个算法都是后向传播网络,但是略有不同。通过对比这两个算法,希望你能够对神经网络有更加深刻的了解。
__author__ = 'http://clayandgithub.github.io/'
import numpy as np
from sklearn import datasets, linear_model
import matplotlib.pyplot as plt
class NNModel:
Ws = [] # params W of the whole network
bs = [] # params b of the whole network
layers = [] # number of nodes in each layer
epsilon = 0.01 # default learning rate for gradient descent
reg_lambda = 0.01 # default regularization strength
def __init__(self, layers, epsilon = 0.01, reg_lambda = 0.01):
self.layers = layers
self.epsilon = epsilon
self.reg_lambda = reg_lambda
self.init_params()
# Initialize the parameters (W and b) to random values. We need to learn these.
def init_params(self):
np.random.seed(0)
layers = self.layers
hidden_layer_num = len(layers) - 1
Ws = [1] * hidden_layer_num
bs = [1] * hidden_layer_num
for i in range(0, hidden_layer_num):
Ws[i] = np.random.randn(layers[i], layers[i + 1]) / np.sqrt(layers[i])
bs[i] = np.zeros((1, layers[i + 1]))
self.Ws = Ws
self.bs = bs
# This function learns parameters for the neural network from training dataset
# - num_passes: Number of passes through the training data for gradient descent
# - print_loss: If True, print the loss every 1000 iterations
def train(self, X, y, num_passes=20000, print_loss=False):
num_examples = len(X)
expected_output = self.transform_output_dimension(y)
# Gradient descent. For each batch...
for i in range(0, num_passes):
# Forward propagation
a_output = self.forward(X)
# Backpropagation
dWs, dbs = self.backward(X, expected_output, a_output)
# Update parameters of the model
self.update_model_params(dWs, dbs, num_examples)
# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don't want to do it too often.
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" % (i, self.calculate_loss(X, expected_output)))
# Helper function to evaluate the total loss on the dataset
def calculate_loss(self, X, expected_output):
output_shape = expected_output.shape
num_output = output_shape[0]#training set size
dimension_output = output_shape[1]# output dimension
# Forward propagation to calculate our predictions
a_output = self.forward(X)
current_output = a_output[-1]
# Calculating the loss
data_loss = np.sum(np.square(current_output - expected_output) / 2)
# Add regulatization term to loss (optional)
for W in self.Ws:
data_loss += self.reg_lambda / 2 * np.sum(np.square(W))
return 1. / num_output * data_loss
# Forward propagation
def forward(self, X):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
a_output = [1] * hidden_layer_num
current_input = X
for i in range(0, hidden_layer_num - 1):
w_current = Ws[i]
b_current = bs[i]
z_current = current_input.dot(w_current) + b_current
a_current = sigmoid(z_current)
a_output[i] = a_current
current_input = a_current
#output layer(logistic)
z_current = current_input.dot(Ws[hidden_layer_num - 1]) + bs[hidden_layer_num - 1]
a_current = sigmoid(z_current)
a_output[hidden_layer_num - 1] = a_current
return a_output
# Predict the result of classification of input x
def predict(self, x):
a_output = self.forward(x)
return np.argmax(a_output[-1], axis=1)
# Backpropagation
def backward(self, X, expected_output, a_output):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
num_examples = len(X)
ds = [1] * hidden_layer_num
# output layer
a_current = a_output[-1]
d_current = -(expected_output - a_current) * a_current * (1 - a_current)
ds[hidden_layer_num - 1] = d_current
#other hidden layer
for l in range(hidden_layer_num - 2, -1, -1):
w_current = Ws[l + 1]
a_current = a_output[l]
d_current = np.dot(d_current, w_current.T) * a_current * (1 - a_current)
ds[l] = d_current
#calc dW && db
dWs = [1] * hidden_layer_num
dbs = [1] * hidden_layer_num
a_last = X
num_output = len(X)
for l in range(0, hidden_layer_num):
d_current = ds[l]
dWs[l] = np.dot(a_last.T, d_current)
dbs[l] = np.sum(d_current, axis=0, keepdims=True)
a_last = a_output[l]
return dWs, dbs
# Update the params (Ws and bs) of the netword during Backpropagation
def update_model_params(self, dWs, dbs, num_examples):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
for l in range(0, hidden_layer_num):
Ws[l] = Ws[l] - self.epsilon * (dWs[l] + self.reg_lambda * Ws[l])
bs[l] = bs[l] - self.epsilon * (dbs[l])
#Ws[l] = Ws[l] - self.epsilon * (dWs[l] / num_examples + model.reg_lambda * Ws[l])
#bs[l] = bs[l] - self.epsilon * (dbs[l] / num_examples)
self.Ws = Ws
self.bs = bs
# tranform the label matrix to output matrix (i.e. [0, 1, 1]->[[1, 0], [0, 1], [0, 1]])
def transform_output_dimension(self, y):
class_num = np.max(y) + 1 # start with 0
examples_num = len(y)
output = np.zeros((examples_num, class_num))
output[range(examples_num), y] += 1
return output
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def generate_data(random_seed, n_samples):
np.random.seed(random_seed)
X, y = datasets.make_moons(n_samples, noise=0.20)
return X, y
def visualize(X, y, model):
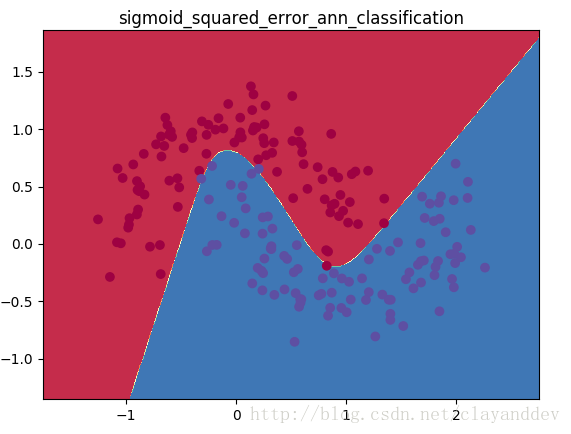
plt.title("sigmoid_squared_error_ann_classification")
plot_decision_boundary(lambda x:model.predict(x), X, y)
def plot_decision_boundary(pred_func, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.show()
class Config:
# Gradient descent parameters
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strength
layers = [2, 4, 2] # number of nodes in each layer
def main():
X, y = generate_data(6, 200)
model = NNModel(Config.layers, Config.epsilon, Config.reg_lambda)
model.train(X, y, print_loss=True)
visualize(X, y, model)
if __name__ == "__main__":
main()__author__ = 'm.bashari'
import numpy as np
from sklearn import datasets, linear_model
import matplotlib.pyplot as plt
class NNModel:
Ws = [] # params W of the whole network
bs = [] # params b of the whole network
layers = [] # number of nodes in each layer
epsilon = 0.01 # default learning rate for gradient descent
reg_lambda = 0.01 # default regularization strength
def __init__(self, layers, epsilon, reg_lambda):
self.layers = layers
self.epsilon = epsilon
self.reg_lambda = reg_lambda
self.init_params()
# Initialize the parameters (W and b) to random values. We need to learn these.
def init_params(self):
np.random.seed(0)
layers = self.layers
hidden_layer_num = len(layers) - 1
Ws = [1] * hidden_layer_num
bs = [1] * hidden_layer_num
for i in range(0, hidden_layer_num):
Ws[i] = np.random.randn(layers[i], layers[i + 1]) / np.sqrt(layers[i])
bs[i] = np.zeros((1, layers[i + 1]))
self.Ws = Ws
self.bs = bs
# This function learns parameters for the neural network from training dataset
# - num_passes: Number of passes through the training data for gradient descent
# - print_loss: If True, print the loss every 1000 iterations
def train(self, X, y, num_passes=20000, print_loss=False):
num_examples = len(X)
expected_output = y
# Gradient descent. For each batch...
for i in range(0, num_passes):
# Forward propagation
a_output = self.forward(X)
# Backpropagation
dWs, dbs = self.backward(X, expected_output, a_output)
# Update parameters of the model
self.update_model_params(dWs, dbs, num_examples)
# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don't want to do it too often.
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" % (i, self.calculate_loss(X, expected_output)))
# Helper function to evaluate the total loss on the dataset
def calculate_loss(self, X, expected_output):
num_examples = len(X) # training set size
# Forward propagation to calculate our predictions
a_output = self.forward(X)
probs = a_output[-1]
# Calculating the loss
corect_logprobs = -np.log(probs[range(num_examples), expected_output])
data_loss = np.sum(corect_logprobs)
# Add regulatization term to loss (optional)
for W in self.Ws:
data_loss += self.reg_lambda / 2 * np.sum(np.square(W))
return 1. / num_examples * data_loss
# Forward propagation
def forward(self, X):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
a_output = [1] * hidden_layer_num
current_input = X
for i in range(0, hidden_layer_num - 1):
w_current = Ws[i]
b_current = bs[i]
z_current = current_input.dot(w_current) + b_current
a_current = np.tanh(z_current)
a_output[i] = a_current
current_input = a_current
#output layer(softmax)
z_current = current_input.dot(Ws[hidden_layer_num - 1]) + bs[hidden_layer_num - 1]
a_current = softmax(z_current)
a_output[hidden_layer_num - 1] = a_current
return a_output
# Predict the result of classification of input x
def predict(self, x):
a_output = self.forward(x)
return np.argmax(a_output[-1], axis=1)
# Backpropagation
def backward(self, X, expected_output, a_output):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
num_examples = len(X)
ds = [1] * hidden_layer_num
# output layer
d_current = a_output[hidden_layer_num - 1]
d_current[range(num_examples), expected_output] -= 1
ds[hidden_layer_num - 1] = d_current
#other hidden layer
for l in range(hidden_layer_num - 2, -1, -1):
w_current = Ws[l + 1]
a_current = a_output[l]
d_current = np.dot(d_current, w_current.T) * (1 - np.power(a_current, 2))
ds[l] = d_current
#calc dW && db
dWs = [1] * hidden_layer_num
dbs = [1] * hidden_layer_num
a_last = X
num_output = len(X)
for l in range(0, hidden_layer_num):
d_current = ds[l]
dWs[l] = np.dot(a_last.T, d_current)
dbs[l] = np.sum(d_current, axis=0, keepdims=True)
a_last = a_output[l]
return dWs, dbs
# Update the params (Ws and bs) of the netword during Backpropagation
def update_model_params(self, dWs, dbs, num_examples):
Ws = self.Ws
bs = self.bs
hidden_layer_num = len(Ws)
for l in range(0, hidden_layer_num):
Ws[l] = Ws[l] - self.epsilon * (dWs[l] + self.reg_lambda * Ws[l])
bs[l] = bs[l] - self.epsilon * (dbs[l])
#Ws[l] = Ws[l] - self.epsilon * (dWs[l] / num_examples + model.reg_lambda * Ws[l])
#bs[l] = bs[l] - self.epsilon * (dbs[l] / num_examples)
self.Ws = Ws
self.bs = bs
def softmax(x):
exp_scores = np.exp(x)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return probs
def generate_data(random_seed, n_samples):
np.random.seed(random_seed)
X, y = datasets.make_moons(n_samples, noise=0.20)
return X, y
def visualize(X, y, model):
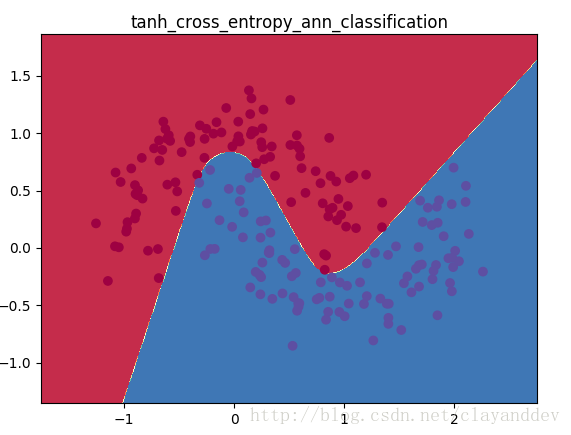
plt.title("tanh_cross_entropy_ann_classification")
plot_decision_boundary(lambda x:model.predict(x), X, y)
def plot_decision_boundary(pred_func, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.show()
class Config:
# Gradient descent parameters (I picked these by hand)
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strength
layers = [2, 4, 2] # number of nodes in each layer
def main():
X, y = generate_data(6, 200)
model = NNModel(Config.layers, Config.epsilon, Config.reg_lambda)
model.train(X, y, print_loss=True)
visualize(X, y, model)
if __name__ == "__main__":
main()更多代码参考github
算法1:
算法2:
结果大体上差不多,但是从细节上看,还是算法2效果更好一些。主要的原因应该是cross-entropy比square-error更适合用作分类任务的损失函数。
疑问:
#Ws[l] = Ws[l] - self.epsilon * (dWs[l] / num_examples + model.reg_lambda * Ws[l])
#bs[l] = bs[l] - self.epsilon * (dbs[l] / num_examples)在更新W和b时,因为,dW和db是所有测试数据累计的误差,按理说应该要除以num_xamples,可是结果却无法收敛。如果不除,倒是可以收敛,不知道是因为迭代次数不够还是其他什么原因导致的。
感悟:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!