社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
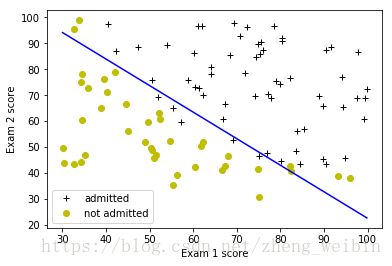
神经网络主要是处理分类问题,比如垃圾邮件识别:现在有一封电子邮件,把其中的所有词汇提取出来,放到机器里,机器判断这封邮件是否垃圾邮件。这种能自动对输入的东西进行分类的机器,就叫做分类器(classifier)。
分类器的输入是一个数值向量,叫做特征向量。比如在垃圾邮件识别例子中,用0,1分别代表字典中的单词在邮件中是否出现,这样把邮件转化为以0和1组成的向量。分类器的输出是一个数值,比如判断为垃圾邮件输出1、整除邮件输出0。
分类器的目标就是让正确分类的比例尽可能高。在垃圾邮件识别的例子中,我们需要先收集一批邮件,并人工标注每一封邮件是否垃圾邮件,根据分类器的判断结果与人工标注结果之间的差异调整分类器参数,训练好的分类器就可以判断新邮件是否垃圾邮件了。
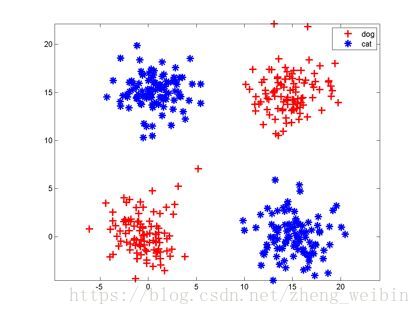
如下图,假设现在有两类数据分别代表猫、狗,区分这两类数据最简单的方法就是在中间画一条直线把数据分成两类,新的向量只要在直线下方的就是猫,直线上方的是狗,神经元就是把特征空间一切两半,认为两半分别属两个类。
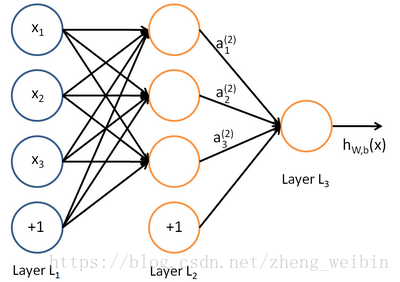
在上一篇文章里已经讲过,这个就是逻辑回归,,一个神经元其实就是逻辑回归分类器,如下图。
神经元(逻辑回归)虽然简单好用,但是有个缺点,就是只能切一刀,如果遇到复杂的情况就处理不了了。如下图就无法用一条直线把两类分开。
这时候你会想,如果能过多切几刀就好了,没错!这种复杂情况的分类方法就是通过多层神经网络,每切一刀其实就是使用一个神经元,只要你切足够多刀,理论上你可以表示很复杂的函数分布。下面就是神经网络的表示图,每一个神经元的输出作为下一层神经元的输入。
由于篇幅所限,此处不展开介绍反向传播算法及其数学推导、正则化、梯度检测,后续将单独写一篇文章来介绍。
我们继续选择手写数字识别问题作为例子建立神经网络,并检验其预测的准确率。每一条数据是长度为400的向量。
因为输入的是长度400的向量,输出是0-9的数字分类结果,因此输入层神经元数量是400,输出层神经元数量是10,隐藏层神经元的数量我们选择40个,Hidden Layer与Input Layer之间的联系定义为权重。Θ1(包含了bias unit),Output Layer与Hidden Layer定义为Θ2(包含了bias unit),则Θ1是形状为(25,401)的矩阵,Θ2是形状为(10,62)的矩阵。在训练之前,我们给Θ1,Θ2分别初始化一个很小的初始值。
#神经网络框架为400*25*10
input_layer_size = 400
hidden_layer_size = 25
output_layer_size = 10
n_training_samples = X_train.shape[0]
#随机初始化Thetas
def genRandThetas():
epsilon_init = 0.12
theta1_shape = (hidden_layer_size, input_layer_size+1)
theta2_shape = (output_layer_size, hidden_layer_size+1)
rand_thetas = [np.random.rand( *theta1_shape ) * 2 * epsilon_init - epsilon_init,
np.random.rand( *theta2_shape ) * 2 * epsilon_init - epsilon_init]
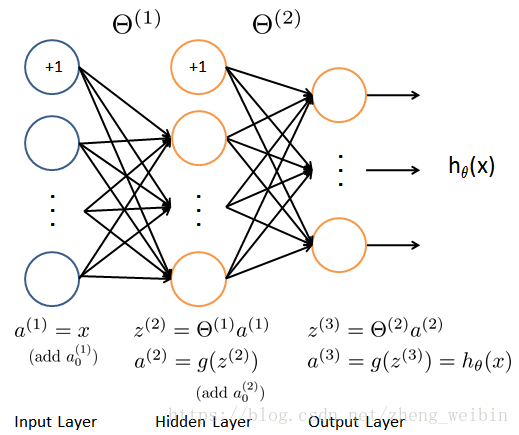
return rand_thetas第一步我们已经建立了如下的三层神经网络如下图:
如上图,代表第l层第i个神经元指向第l+1层第j个神经元的权重,x是特征值,是第l层的输出。下面我们来从第一层开始计算神经元的输出值(忽略bias unit),知道计算出h(x)。
第一层各神经元的输出就是各特征值,即:
第二层各个神经元的输出如下,p为第一层神经元的个数400,q为第二层神经元的个数40:
…
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!