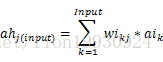社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
写在前面:
我一直是一个非常懒散的人,没有计划,得过且过,所以导致学很多东西都非常浅显,当然我本来也不是一个很深刻的人。说来惭愧,title是算法工程师却一直不懂深度学习,这一直是我心中的痛,想最近抽空学习深度学习。作为最近的大热,深度学习的入门门槛非常低,因为现在的框架已经做得非常完整了,而且很多开源代码下下来跑跑数据就可以说我跑过模型了,但是我一直对深度学习的内部机理感到迷茫,所以这个领域对我来说像是一个刚炖熟没有切开的猪脚,无从下手。也跟着视频看了几集,总是觉得没有参透,但又不知道是哪里的问题。所以我有个大胆的想法,我希望用一些非常基础的库去实现一些深度学习中常见的算法和网络,这可能是一个系列,也可能只有这一篇。
正文:
本文主要针对前后向传播算法,实现了一个3层的全连接网络,代码我放在了github上。
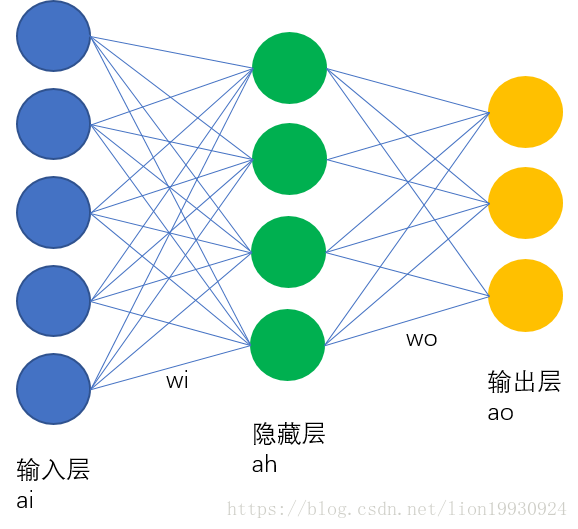
本文的神经网络结构如下图所示:
网络共有3层,输入层,隐藏层和输出层,每两层之间的节点是全连接的,输入层和隐藏层之间的各个连接的权重由矩阵wi表示,隐藏层和输出层之间的权重关系由wo表示,激活函数采用sigmoid函数。那么对于隐藏层第j个节点可以表示为
输出层表示相同。通过这样的方式我们可以根据输入,一层一层的计算,将结果传导给输出层,这就是前向传播。
实现代码如下:
def feed_propagation(self, inputs):
"""
Feed forward nerual network
Args:
inputs: input matrix
"""
if len(inputs) != self._input - 1:
raise ValueError("Input matrix does not fit the network!")
for i in xrange(len(inputs)):
self._ai[i] = inputs[i]
for j in xrange(self._hidden):
sum = 0.0
for i in xrange(self._input):
sum += self._wi[i][j] * self._ai[i]
self._ah[j] = self._sigmoid(sum)
for j in xrange(self._output):
sum = 0.0
for i in xrange(self._hidden):
sum += self._wo[i][j] * self._ah[i]
self._ao[j] = self._sigmoid(sum)
return self._ao[:]
得到输出结果之后我们需要将输出结果和目标结果进行对比,所以我们需要定一个损失函数,来降低损失函数,为简化问题,我们使用MSE作为损失函数。
那么我们如何将偏导数传递到输入层呢,和前向反馈的机制一样,首先我们对输出层求导,那么输出层的输入部分的偏导为:
据此我们可以再讲隐藏层的偏导传递到输入层。这就是后向传播算法,代码如下:
def back_propagation(self, targets, N):
"""
Back propagation algorithm.
Args:
targets: target number, lists
"""
if len(targets) != self._output:
raise ValueError("Target does not match the output matrix!")
# Caluculate the derivative of each layer's input
out_delta = [0.0] * self._output
print out_delta
for i in xrange(self._output):
out_delta[i] = -(targets[i] - self._ao[i]) * self._dsigmoid(self._ao[i])
hidden_delta = [0.0] * self._hidden
for i in xrange(self._hidden):
error = 0.0
for j in xrange(self._output):
error += out_delta[j] * self._wo[i][j]
hidden_delta[i] = self._dsigmoid(self._ah[i]) * error
# Update the parameter of each layer's weight
for j in range(self._hidden):
for k in range(self._output):
change = out_delta[k] * self._ah[j]
self._wo[j][k] -= N * change
for i in range(self._input):
for j in range(self._hidden):
change = hidden_delta[j] * self._ai[i]
self._wi[i][j] -= N * change
# loss function is MSE
error = 0.0
for k in range(len(targets)):
error += 0.5 * (targets[k] - self._ao[k]) ** 2
return error
此处我们的优化方法采用梯度下降。未来的工作是采用其他方法对参数进行优化。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!