社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
回归分析的作用是:
①从一组数据出发确定某些变量之间的定量关系式
②对变量间这些关系式进行统计检验。并从影响某一个变量的多个变量中找出影响显著的变量
③利用所求出的关系式,根据一个变量或多个变量取值估计或预测另一个特定变量的取值。
网络模型包括其输入输出模型、作用函数模型、误差计算模型和自学习模型
输入层:输入神经元定义数据挖掘模型所有的输入属性值以及概率。一个感知器可以接收多个输入(x_1,?_2 ……?_?),每个输入上有一个权值?_?,此外还有一个偏置项b,就是上图中的?_0。
隐含层:隐藏神经元接受来自输入神经元的输入,并向输出神经元提供输出。隐藏层是向各种输入概率分配权重的位置。
输出层:输出神经元代表数据挖掘模型的可预测属性值。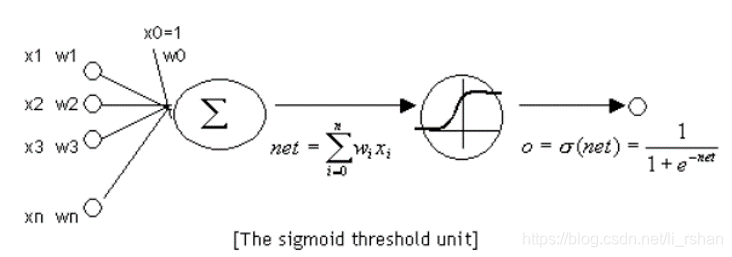
激活函数:所谓激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端,如sigmod函数、tanh函数等。
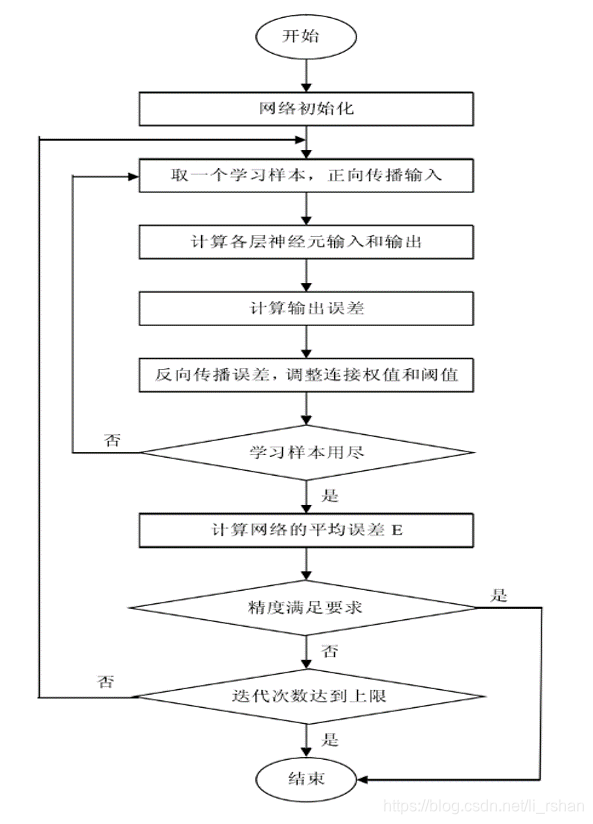
1、网络初始化(给各连接权值分别赋一个(-1,1)内的随机数。给定计算精度和最大学习次数。
2、将训练样本通过神经网络进行前向传播计算。
3、计算输出误差,通常用均方差。网络误差通过随机梯度下降法来最小化,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
4、判断网络误差是否满足要求,当误差达到预设精度或学习次数大于所设定的最大次数,则结束算法。否则进行下一轮学习,直至结束。
机器学习有一类学习方法叫做监督学习,它是说为了训练一个模型,我们要提供这样一堆训练样本:每个训练样本既包括输入特征x,也包括对应的输出y(y也叫做标记,label)。也就是说,我们要找到很多人,我们既知道他们的特征(工作年限,行业…),也知道他们的收入。我们用这样的样本去训练模型,让模型既看到我们提出的每个问题(输入特征x),也看到对应问题的答案(标记y)。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
另外一类学习方法叫做无监督学习,这种方法的训练样本中只有x而没有y。模型可以总结出特征的一些规律,但是无法知道其对应的答案y。
神经元——感知器
多层感知器的优点:
可以学习得到非线性模型。
可以学习得到实时模型(在线学习)
多层感知器(MLP)的缺点:
具有隐藏层的 MLP 具有非凸的损失函数,它有不止一个的局部最小值。 因此不同的随机权重初始化会导致不同的验证集准确率。
MLP 需要调试一些超参数,例如隐藏层神经元的数量、层数和迭代轮数。
MLP 对特征归一化很敏感.
我们需要知道一个神经网络的每个连接上的权值是如何得到的。我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
(隐藏节点数,学习步长,迭代次数等)
误差的反向传播(“BP”)
误差反向传播:输出误差(某种形式)->隐层(逐层)->输入层 其主要目的是通过将输出误差反传,将误差分摊给各层所有单元,从而获得各层单元的误差信号进而修正各单元的权值(其过程,是一个权值调整的过程)。注:权值调整的过程,也就是网络的学习训练过程(学习也就是这么的由来,权值调整)。
标准BP算法的缺陷:
1)易形成局部极小(属贪婪算法,局部最优)而得不到全局最优;
2)训练次数多使得学习效率低下,收敛速度慢(需做大量运算);
3)隐节点的选取缺乏理论支持;
4)训练时学习新样本有遗忘旧样本趋势。
注:改进算法—增加动量项、自适应调整学习速率及引入陡度因子
引用文本
简单的MLP
第一种
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
import pandas as pd
input = pd.read_excel("C:/Users/Lenovo/Desktop/数据集/in.xlsx")
output = pd.read_excel("C:/Users/Lenovo/Desktop/数据集/out.xlsx")
x_train, x_test, y_train, y_test = train_test_split(input,output,test_size=0.2, random_state=0)
X = x_train
y = y_train
scaler = StandardScaler() # 标准化转换
scaler.fit(X) # 训练标准化对象
X = scaler.transform(X) # 转换数据集
#(多层感知器对特征的缩放是敏感的,所以需要归一化你的数据。 例如,将输入向量 X 的每个属性放缩到到 [0, 1] 或 [-1,+1] ,或者将其标准化使它具有 0 均值和方差 1。
为了得到有意义的结果,必须对测试集也应用 相同的尺度缩放。 可以使用 StandardScaler 进行标准化。)
# solver=‘sgd', MLP的求解方法:L-BFGS 在小数据上表现较好,Adam 较为鲁棒,SGD在参数调整较优时会有最佳表现(分类效果与迭代次数);SGD标识随机梯度下降。
# alpha:L2的参数:MLP是可以支持正则化的,默认为L2,具体参数需要调整
# hidden_layer_sizes=(2, 1) hidden层2层,第一层2个神经元,第二层1个神经元),2层隐藏层,也就有3层神经网络
clf = MLPRegressor(solver=‘sgd', alpha=1e-5,hidden_layer_sizes=(2, 1), random_state=1)
clf.fit(X, y)
print('预测结果:', clf.predict([[5,1]])) # 预测某个输入对象
cengindex = 0
for wi in clf.coefs_:
cengindex += 1 # 表示底第几层神经网络。
print('第%d层网络层:' % cengindex)
print('权重矩阵维度:',wi.shape)
print('系数矩阵:n',wi)

随机梯度下降(SGD)
Adam 类似于 SGD,因为它是 stochastic optimizer (随机优化器),但它可以根据低阶矩的自适应估计自动调整参数更新的量。
使用 SGD 或 Adam ,训练过程支持在线模式和小批量学习模式。
L-BFGS 是利用 Hessian 矩阵来近似函数的二阶偏导数的求解器,它使用 Hessian 的逆矩阵来近似进行参数更新。
如果所选择的方法是 ‘L-BFGS’,训练过程不支持在线学习模式和小批量学习模式。
第二种
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neural_network import MLPRegressor
data = pd.read_excel('C:\Users\Lenovo\Desktop\数据集\AirQualityUCI.xlsx')
array = data.values
X = array[:, :3]
Y = array[:, 4:5]
validation_size = 0.1
seed = 8
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y,test_size=validation_size, random_state=seed)
knn = MLPRegressor()
knn.fit(X_train,Y_train)
K_pred = knn.predict(X_validation)
score = r2_score(Y_validation, K_pred)
#需要用测试数据检验这个模型好不好
sklearn.metric提供了一些函数,用来计算真实值与预测值之间的预测误差:
以_score结尾的函数,返回一个最大值,越高越好
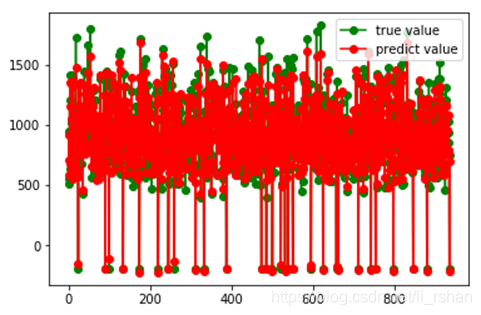
plt.plot(np.arange(len(K_pred)),Y_validation,'go-',label = 'true value')
plt.plot(np.arange(len(K_pred)),K_pred,'ro-',label = 'predict value')
plt.legend()
plt.show()
MLPRegressor
通过输出层没有激活函数的反向传播算法,或者也可看做恒等函数作为激活函数,实现了多层感知器。因此,其使用方差作为损失函数,输出是利系列连续的值。
MLPRegressor 也支持多输出的回归,即一个样本可能有不止一个目标值。
(MLPClassifier利用神经网络做分类)
import pandas as pd
import math
import random
from sklearn.model_selection import train_test_split
input =pd.read_excel("C:/Users/Lenovo/Desktop/数据集/in.xlsx")
output= pd.read_excel("C:/Users/Lenovo/Desktop/数据集/out.xlsx")
x_train, x_test, y_train, y_test = train_test_split(input,output,test_size=0.2, random_state=0)#导入数据
random.seed(0)
#在数区间 a ~ b 中,随机生成一个float数
def rand(a, b):
return (b - a) * random.random() + a# random.random() 生成一个0~1的浮点数
#创建一个指定大小的 矩阵,并用fill 去填充
def make_matrix(m, n, fill = 0.0 ):
mat = []
for i in range(m):# 对行进行循环
mat.append([fill] * n)#创建每行的列元素
return mat
#定义sigmoid 函数,及它的导数
def sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
def sigmoid_derivate(x):
return x * (1 - x)
#定义BPNeuralNetwork类,使用三个列表维护输入层,隐含层,输出层神经元
class BPNeuralNetwork:
def __init__(self):
self.input_n = 0
self.hidden_n = 0
self.output_n = 0
self.input_cells = []
self.hidden_cells = []
self.output_cells = []
self.input_weights = []
self.output_weights = []
self.input_correction = []
self.output_correction = []
#定义setup 的方法初始化神经网络
# ni ,nh ,no ->各层神经元的个数
def setup(self, ni, nh, no):
self.input_n = ni + 1 #输入层额外加一个偏置神经元,提供一个可控的输入修正;(或者为每个隐含层神经元设置一个偏置参数)
self.hidden_n = nh #隐藏层神经元个数
self.output_n = no #输出层神经元个数
#init cells
#初始化神经元的输出值
self.input_cells = [1.0] * self.input_n #输入层各神经元的值初始化为1
self.hidden_cells = [1.0] * self.hidden_n#隐藏层神经元的值初始化为1
self.output_cells = [1.0] * self.output_n#输出层神经元的值初始化为1
# init weights
#初始化神经网络各层权重的值 各层的权重已矩阵的形式存储
self.input_weights = make_matrix(self.input_n, self.hidden_n) #初始化输入层与隐藏层间的权重
self.output_weights = make_matrix(self.hidden_n,self.output_n)#初始化隐藏层与输出层间的权重
#random activate
#给权重矩阵 随机赋初值
for i in range(self.input_n):#给输入层及隐藏层间的权重矩阵赋初值
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2, 0.2)
for h in range(self.hidden_n):#给隐藏层及输出层间的权重赋初值
for o in range(self.output_n):
self.output_weights[h][o] = rand(-2.0, 2.0)
#init correction matrix
#创建矫正矩阵 此处应该是指各层权重矩阵的矫正矩阵
self.input_correction = make_matrix(self.input_n, self.hidden_n) #输入矫正矩阵
self.output_correction = make_matrix(self.hidden_n, self.output_n)#输出矫正矩阵
#定义predict方法进行一次前馈,并返回输出
def predict(self,inputs):
#activate input layer
#激活输入层
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i] #对输入层神经元赋值 (此处不含输入层神经元的偏置)
#activate hidden layer
#激活隐藏层
for j in range(self.hidden_n):#对隐含层神经元进行计算求值
total = 0.0
for i in range(self.input_n):#前一层神经元的输出 * 相应权重值 后求和
total += self.input_cells[i] * self.input_weights[i][j] #
self.hidden_cells[j] = sigmoid(total)#对每个神经元经过前一层的求和后 计算经过所选激励函数映射后的输出。
#activate output layer
#激活输出层
for k in range(self.output_n):#对输出层各神经元的值进行计算
total = 0.0
for j in range(self.hidden_n):#隐藏层的输出经过神经元的加权后求和
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)#所得和经过激励函数的映射后的输出
return self.output_cells[:]
#定义一次反向传播 和更新权值的过程,并返回最终预测误差
def back_propagate(self, case, label, learn, correct):
#feed forward ->前馈
self.predict(case) #对实例case进行前馈预测
#get output layer error ->获取输出层误差
output_deltas = [0.0] * self.output_n #初始化输出层更新差值列表
#计算实际的标签与预测标签的差值进行计算
for o in range(self.output_n):
error = label[o] -self.output_cells[o]
output_deltas[o] = sigmoid_derivate(self.output_cells[o]) * error#???
#get hidden layer error ->获取隐藏层的误差列表
hidden_deltas = [0.0] * self.hidden_n #初始化隐藏层更新差值列表
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o]
hidden_deltas[h] = sigmoid_derivate(self.hidden_cells[h]) * error
# update output weights 更新输出层权重
for h in range(self.hidden_n):
for o in range(self.output_n):
change = output_deltas[o] * self.hidden_cells[h]
self.output_weights[h][o] += learn * change + correct + self.output_correction[h][o]
self.output_correction[h][o] = change
#update input weights 更新输入层权重
for i in range(self.input_n):
for h in range(self.hidden_n):
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct *self.input_correction[i][h] #correct 为矫正矩阵的矫正率
self.input_correction[i][h] = change #更新矫正矩阵
#get global error 获取全局误差
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o]) ** 2
return error
#定义train方法控制迭代,该方法可以修改最大迭代次数,学习率 矫正率 三个参数
def train(self, cases, labels, limit = 10000,learn = 0.05 , correct = 0.1):
for i in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn, correct)
#test 方法演示如何使用神经网络学习异或逻辑
def test(self):
cases = [
[0, 0],
[0, 1],
[1, 0],
[1, 1],
]
labels = [[0], [1], [1], [0]]
self.setup(2, 5, 1) #初始化神经网络
self.train(cases, labels, 10000, 0.05, 0.1)#神经网络的学习
for case in cases: #对输入进行分类预测
print(self.predict(case))
if __name__ == '__main__':
nn = BPNeuralNetwork()
nn.test()
数据标准化:
x_train, x_test, y_train, y_test = train_test_split(Input,output,test_size=0.2, random_state=0)
#数据标准化——匿名函数max[x]-x/max[x]-min[x]
x_train=x_train.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
y_train=y_train.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
问题:
还没有考虑预测结果反归一
结果: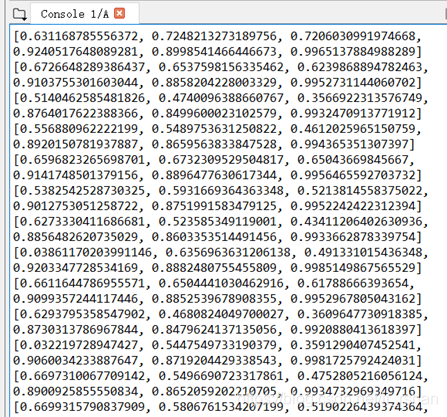
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
