社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1. KETTLE是什么?
首先普及一点知识:
Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。Kettle包括三大块:
Spoon——转换/工作(transform/job)设计工具 (GUI方式)
Kitchen——工作(job)执行器 (命令行方式)
Span——转换(trasform)执行器 (命令行方式)
Kettle是一款国外开源的etl工具,纯java编写,可以在Window、Linux、Unix上运行吗,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2. 为什么使用KETTLE?
这里简单概括一下几种具体的应用场景,按网络环境划分主要包括:
表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来;
综上3种模式如果我们都用传统的模式无疑工作量是巨大的,那么怎么做才能更高效更节省时间又不容易出错呢?答案是我们可以使用Kettle!
3. 使用KETTLE需要了解的知识?
Kettle提供了资源库方式的方式来整合所有的工作,但是因为资源库移植不方便,所以我们选择没有资源库;
a) Kettle的使用
i. 创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation文件保存后后缀名为ktr;
ii. 创建一个新的job,点击 保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb;
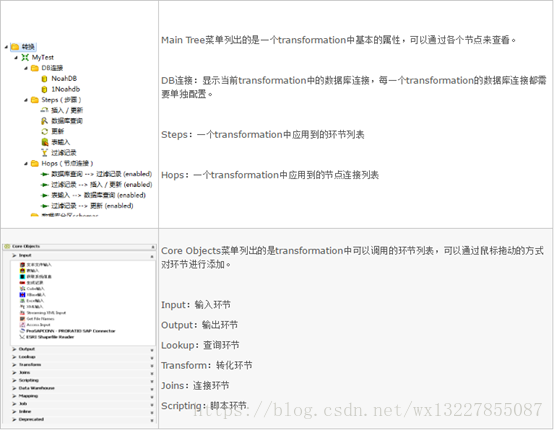
b) 组件树介绍
c) Transformation转换介绍
i. 每一个环节可以通过鼠标拖动来将环节添加到主窗口中。并可通过shift+鼠标拖动,实现环节之间的连接。
ii. 转换常用步骤介绍
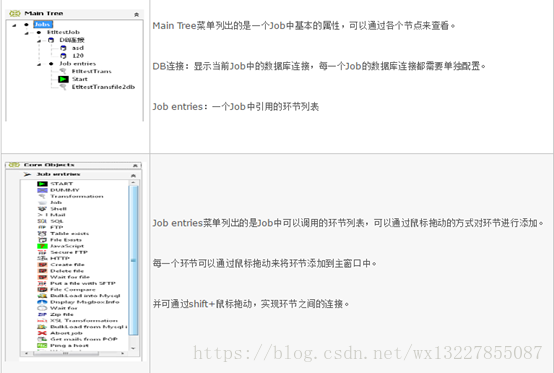
d) Job作业介绍
i. 作结
ii. 作业常用步骤
4. 下载
a) 下载地址:https://community.hitachivantara.com/docs/DOC-1009855
b) 网址打开后显示如下:
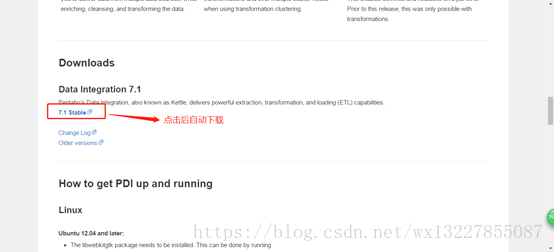
c) 往下翻找到如图所示,点击后下载
5. 如何配置?
a) 环境变量配置
i. 安装 JDK
1. 首先到官网上下载对应JDK包,JDK1.5或以上版本就行;
2. 安装JDK;
3. 配置环境变量(安装完成后,还要对它进行相关的配置才可以使用,先来设置一些环境变量,对于Java来说,最需要设置的环境变量是系统路径变量path。)
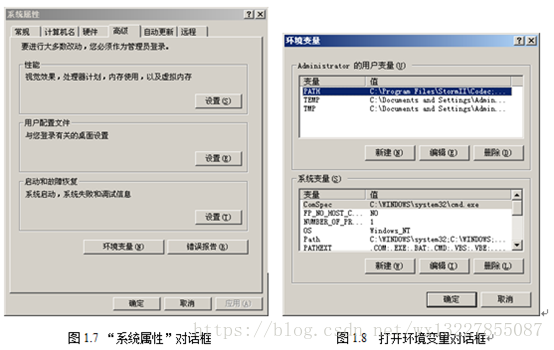
a) 要打开环境变量的设置窗口。右击“我的电脑”,在弹出的快捷菜单中选择“属性”选项,进入“系统属性”对话框,如图所示。选择“高级”标签,进入“高级”选项卡,再单击“环境变量”按钮,进入“环境变量”对话框,如图1.7所示:
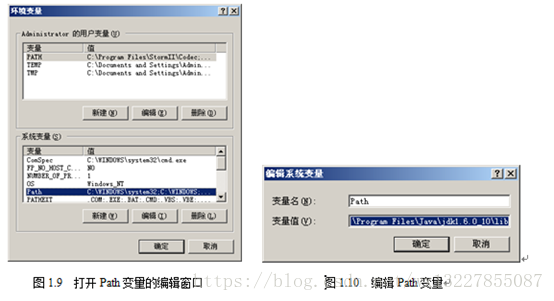
b) 在“Administrator的用户变量”列表框中,选择变量PATH,待其所在行变高亮后,单击“编辑”按钮,如图1.8所示。
c) 在弹出的“编辑系统变量”对话框中,将JDK安装路径下的bin目录路径设置到Path变量中,如图1.10所示。
编辑完后,单击“确定”按钮,进行保存,环境变量Path的设置就正式完成。注意:设置Path变量的路径,必须是JDK安装目录中的bin目录,有时候在JDK安装目录的同一层会有JRE的安装目录,因此请谨慎选取相关路径,避免将路径设置成JRE目录下的bin目录。
b) 测试JDK配置是否成功
设置好环境变量后,就可以对刚设置好的变量进行测试,并检测Java是否可以运行。
i. Win键+R打开运行对话框,输入cmd命令。
ii. 点击确定打开命令行窗口。
iii. 在光标处输入:javac命令,按下Enter键执行,即可看到测试结果如图所示:
c) 解压pdi-ce-7.1.0.0-12.zip,将mysql-connector-java-5.1.21-bin.jar驱动手动放入data-integration/lib文件夹。
6. 如何使用
a) KETTLE 的几个子程序的功能和启动方式
i. Spoon.bat 图形界面方式启动作业和转换设计器。
ii. Pan.bat命令方式执行转换。
iii. Kitchen.bat命令方式执行作业。
b) 转换和作业
Kettle的Spoon设计器用来设计转换(Transformation)和作业(Job)。
i. 转换主要是对数据的各种处理,一个转换可以包含多个步骤(Step)。
ii. 作业是比转换更高一级的处理流程,一个作业里包含多个作业项(Job Entry),一个作业项代表一项工作,转换也是一个作业项。
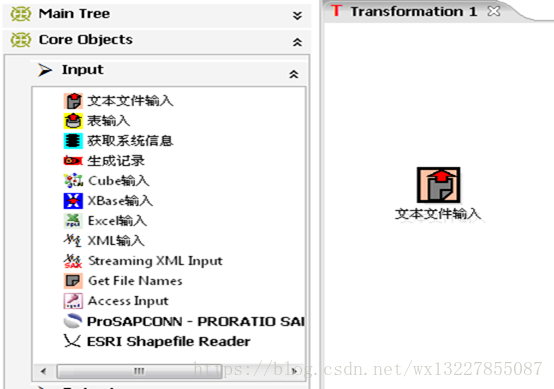
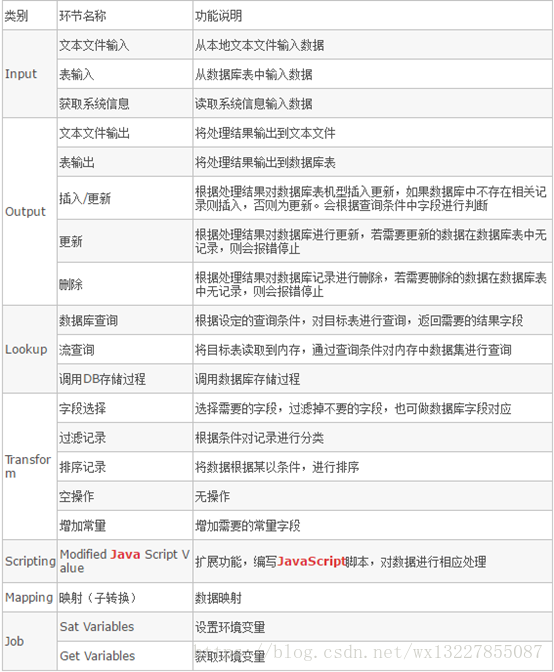
c) 输入步骤简介
输入类步骤用来从外部获取数据,可以获取数据的数据源包括,文本文件(txt,csv,xml,json)数据库、 Excel 文件等桌面文件,自定义的数据等。对特殊数据源和应用需求可以自定义输入插件。 例子:生成随机数步骤。
d) 转换步骤简介
转换类步骤是对数据进行各种形式转换所用到的步骤。例如:字段选择、计算器、增加常量。
e) 流程步骤简介
流程步骤是用来控制数据流的步骤。一般不对数据进行操作,只是控制数据流。 例如:过滤步骤。
f) 连接步骤简介
连接步骤用来将不同数据集连接到一起。 例如:笛卡尔乘积。
g) 输出步骤简介
输出步骤是输出数据的步骤,常见的输出包括文本文件输出、表输出等,可以根据应用的需求开发插件以其他形式输出。例如:表输出。
h) 在kettle里元数据的存储方式
i. 资源库 资源库包括文件资源库、数据库资源库 Kettle 4.0 以后资源库类型可以插件扩展 。
ii. XML 文件 .ktr 转换文件的XML的根节点必须是 transformation .kjb 作业XML的根节点是job。
iii. 数据库资源库:
1. 把 Kettle 的元数据串行化到数据库中,如 R_TRANSFORMATION 表保存了Kettle 转换的名称、描述等属性。
2. 在Spoon 里创建和升级数据库资源库。
iv. 文件资源库:
在文件的基础上的封装,实现了 org.pentaho.di.repository.Repository 接口。是Kettle 4.0 以后版本里增加的资源库类型
不使用资源库: 直接保存为ktr 或 kjb 文件。
i) Kettle资源库-如何选择资源库
i. 数据资源库的缺点:
1. 不能存储转换或作业的多个版本。
2. 严重依赖于数据库的锁机制来防止工作丢失。
3. 没有考虑到团队开发,开发人员不能锁住每个作业自己开发。
ii. 文件资源库的缺点:
1. 对象(如转换、作业、数据库连接等对象)之间的关联关系难以处理,所以删除、重命名等操作会比较麻烦。
2. 没有历史版本。
3. 难以进行团队开发。
不使用资源库,使用svn进行文件版本控制。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!