社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据库优化的目的
可以进行优化的方面
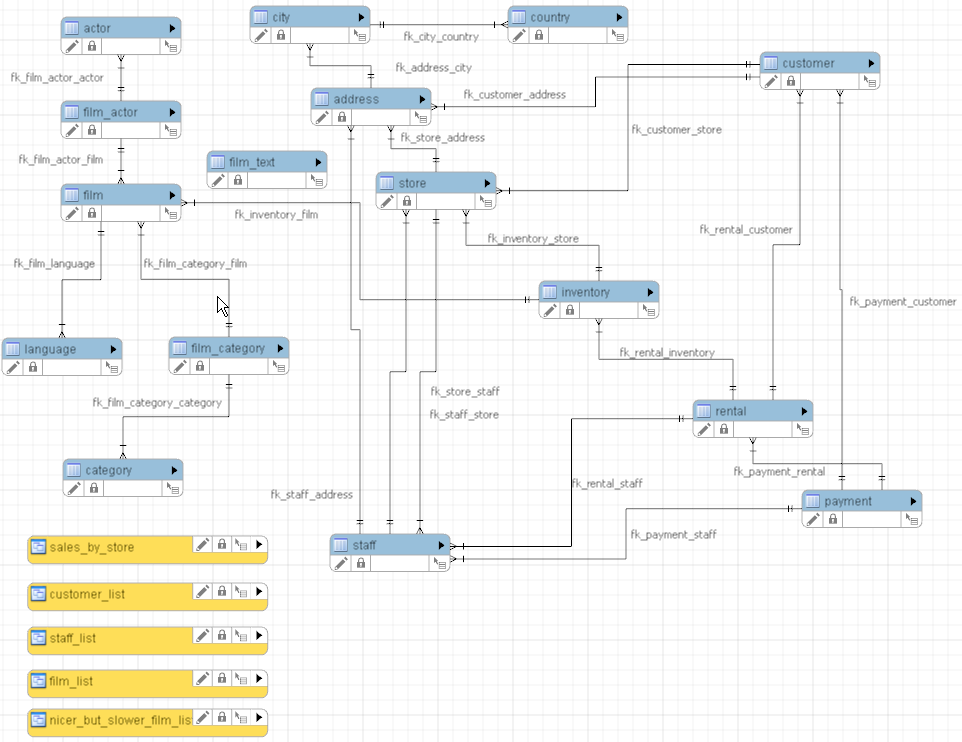
演示数据库说明
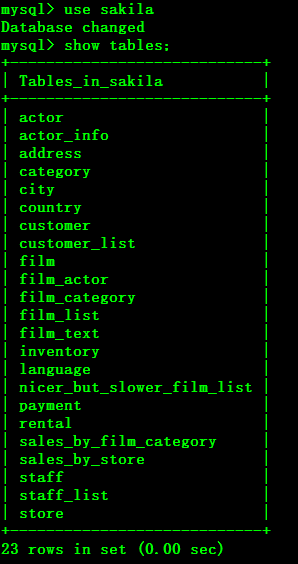
如何发现有问题的SQL
使用MySql慢查询日志可以对有效率问题的SQL进行监控
开启慢查询日志
相关命令:
//开启慢查询日志
set global slow_query_log=on;
//查看慢查询日志是否开启
show variables like 'slow_query_log';
//设置慢查询日志地址
set global slow_query_log_file='/var/lib/mysql/hsw-slow.log';
//设置没有使用索引的查询是否记录到慢查询日志中
set global log_queries_not_using_indexes = on;
//设置超过多少秒的操作记录到慢查询日志中,此处设置为0,方便学习
set global long_query_time=0;
慢查日志的存储格式

详情:
//执行SQL的主机信息:
User@Host: root[root] @ localhost [127.0.0.1]
//SQL的执行信息:
Query_time: 0.015001 Lock_time: 0.013001 Rows_sent: 200 Rows_examined: 200
//SQL执行时间:
SET timestamp=1585805431;
//SQL执行内容:
select * from actor;
慢查日志的分析工具
1.mysqldumpslow
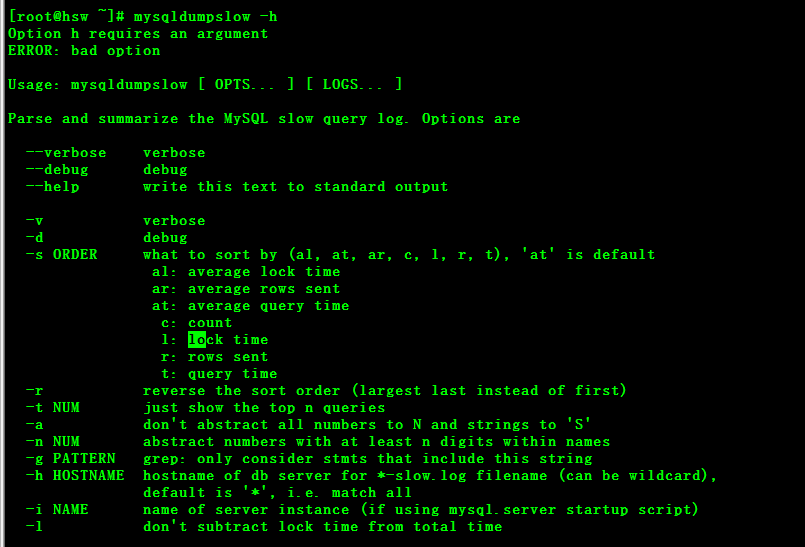
使用示例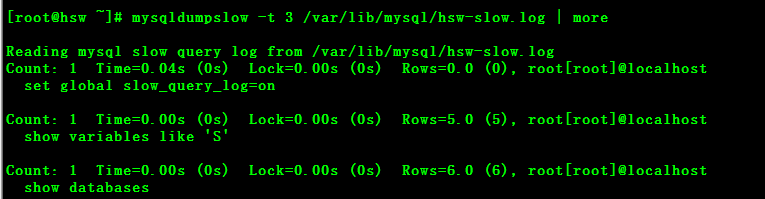 2.pt-query-digest
2.pt-query-digest
相关参考:点此
如何通过慢查询日志发现有问题的SQL
如何分析SQL查询
使用explain查询SQL的执行计划
explain返回各列的含义
table:显示这一行的数据是关于哪张表的
type:显示连接使用了何种类型。从最好到最差的连接类型依次为:
const、eq_reg(范围查找)、ref(连接查询,基于某个索引的查找)、range(基于某个索引范围的查找)、index(对于索引的扫描)、All(表扫描)
possible_keys:显示可能应用在这张表中的索引。如果为空可能没有索引
key:实际使用的索引。如果为NULL,则没有使用索引
key_len:使用索引的长度。在不损失精度的情况下、长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,最好是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
extra:需要注意以下返回值
- Using filesort:看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。他根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
- Using temporary 看到这个的时候也需要优化。这里MYSQL需要创建一个临时表来存储结果,这通常发生在对不同列集进行ORDER BY上,而不是GROUP BY上
count()和max()的优化方法 max() 优化方法:建立索引
max() 优化方法:建立索引
 count() 优化方法:使用正确的SQL语句
count() 优化方法:使用正确的SQL语句
举例:查询2006年和2007年电影的数量
select count(release_year='2006' or NULL) as '2006',
count(release_year='2007' or NULL) as '2007' from film;
 子查询的优化方式
子查询的优化方式
通常情况下需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多关系,因为这样可能会出现重复数据,此时可以使用distinct来去重
limit的优化方式
limit常用于分页处理,时常会伴随order by从句使用,因此大多时候会使用Filesorts,这样会造成大量IO问题。
select film_id,description from film order by title limit 50,5;
 优化步骤一:使用索引列或者主键进行order by 操作
优化步骤一:使用索引列或者主键进行order by 操作
select film_id,description from film order by film_id limit 50,5;
优化步骤二:记录上次返回的主键,在下次查询时使用主键过滤,因为仅仅使用第一步随着查询数量(对应上述SQL中的50)越来越大扫描行数也越来越大。
select film_id,description from film
where film_id>55 and film_id<=60
order by film_id limit 0,5;

如何选择合适的列建立索引
索引的维护及优化- -重复及冗余索引
重复索引 : 指相同的列以相同的顺序建立同类型的索引,如下表中primary key 和 id列上的索引就是重复索引。
create table test(
id int not null primary key,
name varchar(200) not null,
title varchar(200) not null,
unique(id)
)engine=innodb;
冗余索引: 指多个索引的前缀相同,或是在联合索引中包含了主键的索引,下面例子中key(name,id)就是一个冗余索引
create table test(
id int not null primary key,
name varchar(200) not null,
title varchar(200) not null,
key(name,id)
)engine=innodb;
使用pt-duplication-key-checker工具可以检查重复及冗余索引
索引的维护及优化- -删除不用的索引
在mysql中只能通过慢查询日志配合pt-index-usage工具进行索引使用情况的分析
选择合适的数据类型
表的范式化和反范式化
范式化是指数据库设计的规范,目前说道范式化一般是指第三范式- - -要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖。
反范式化是指为了查询效率的考虑把原本符合第三范式的表适当增加冗余已达到优化查询的目的,反范式化可以理解为是一种以空间换时间的操作。
表的垂直拆分
把原本有很多列的表拆分成多个表,这解决了表的宽度问题。
通常垂直拆分的原则为:
表的水平拆分
表的水平拆分主要是为了解决单表的数据量过大的问题,水平拆分后的每一个表结构完全一致。
常用的水平拆分方法为:
操作系统优化
数据库是基于操作系统的,目前大多数MySql都是安装在Linux系统之上,所以对于操作系统的一些参数配置也会影响到MySql的性能,下面就列出一些常用的系统配置
#网络方面的配置,修改/etc/sysctl.conf文件
#增加tcp支持的队列数
net.ipv4.tcp_max_syn_backlog = 65535
#减少断开连接时,资源回收
net.ipv4.tcp_max_tw_buckets = 8000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_recycle = 1
net.ipv4.tcp_timeout = 10
#修改打开文件数限制,可以使用ulimit -a 查看目录的限制
#可以修改/etc/security/limits.conf文件增加下面内容修改限制
soft nofile 65535
hard nofile 65535
#最后在MySql服务器上关闭iptables,selinux等防火墙软件
MySql配置文件优化
MySql可以通过启动时指定配置参数和使用配置文件两种方法进行配置,在大多数情况下配置文件位于/etc/my.cnf或是/etc/mysql/my.cnf在windows系统配置文件多为安装目录下的my.ini文件
常用参数说明:
#配置innodb缓冲池大小推荐为总内存的75%
innodb_buffer_pool_size
#配置innodb缓冲池个数
innodb_buffer_pool_instance
#配置innodb log缓冲的大小,由于一秒一刷新一般不用太大
innodb_log_buffer_size
#配置缓冲刷新到磁盘参数
innodb_flush_log_at_trx_commit
#配置innodb读写io进程数
innodb_read_io_threads
innodb_write_io_threads
#控制innodb中每一个表使用独立的表空间,默认off即所有表都会建立在共享表空间中
innodb_file_per_table
#配置MySql什么情况刷新innodb表的统计信息
innodb_stats_on_metadata
第三方配置工具
这个。。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
