社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
真皮沙发这次又来了!在上次的两个爬虫中,笔者探讨了python爬虫的入门以及re模块的运用。而上两次的爬取内容都是笔者闲的蛋疼入门爬虫所选择的连个爬取页面。
今天笔者要来搞事了,这次是搞正事。是的,搞正事。相信很多的同学都有在各大招聘网站上浏览过,各种层出不起的信息,着实让人厌烦。很多人也在着急寻找实习单位为以后找工作打好基础,笔者本着服务于人的态度爬取了一个实习生招聘网站-实习僧,因为笔者在武汉就读,就爬取了100页武汉本地的实习单位信息。通过所得到的数据分析了一下实习生的工资待遇,就笔者目前所得到的结果来看,整体就一个惨字啊!
哇,一个偌大的武汉对待实习生也太差了吧,真的是让人心寒。这里笔者先买个关子,等会和大家一起看分析结果。那么现在我们进入正题,首先我们要将信息爬取下来,这需要一个爬虫框架,这里便不多累述,前两篇都有。而后我们将爬取得到的数据存入数据库,这里用到的是MongoDB,不得不说这个C++开发的数据库效率还是很高的,数据的存储方式与知名的关系数据库大相径庭,但却显得十分有个性。接下来我们便要用到赞誉极高的jupyter notebook来进行数据分许了,对于数据的可视化笔者用的是charts这个第三方库,当然你也可以用matplotlib这个神奇的库。
我们先来看一看本次爬取的页面:
说个实话笔者觉得这个实习僧网面简直不要太友好,类容简介又好看,爬虫又好爬,着实让笔者偷了很多懒。关于爬虫这一块,感兴趣的可以看一下笔者前两遍文章或者去查询一下资料。这里我先上我的代码:
import requests
from bs4 import BeautifulSoup
import re
import pymongo
def get_one_page(url):
wb_data = requests.get(url)
if wb_data.status_code == 200:
return wb_data.text
else:
return None
def parse_one_page(response):
soup = BeautifulSoup(response, 'lxml')
datas = soup.select('div#load_box div.jib_inf div.job_inf_inf')
pattern = re.compile(
r'<div.*?<h3>(.*?)</h3>.*?<a class="company_name".*?title="(.*?)">.*?<i class="money"></i>(.*?)</span>.*?<i class="days"></i>(.*?)</span>.*?</div>',
re.S)
wants = []
for item in datas:
final = re.findall(pattern, str(item))
# print(final[0])
wants.append(final[0])
return wants
def get_all_page():
client=pymongo.MongoClient('localhost',27017)
db=client['shixi']
item=db['db']
for i in range(1, 101):
url = 'http://www.shixiseng.com/interns?k=&c=%E6%AD%A6%E6%B1%89&s=0,0&d=&m=&x=&t=zh&ch=&p=' + str(
i)
response = get_one_page(url)
wants = parse_one_page(response)
for want in wants:
data = {
'职位': want[0],
'公司': want[1],
'薪资': want[2],
'要求': want[3]
}
print(data)
item.insert_one(data)
if __name__ == '__main__':
get_all_page()
整篇代码的思想便是先得到每一页网页的数据,然后从中抓取数据信息,然后跳转页面直至得到100页的全部数据,将其写入mongdb数据库中。
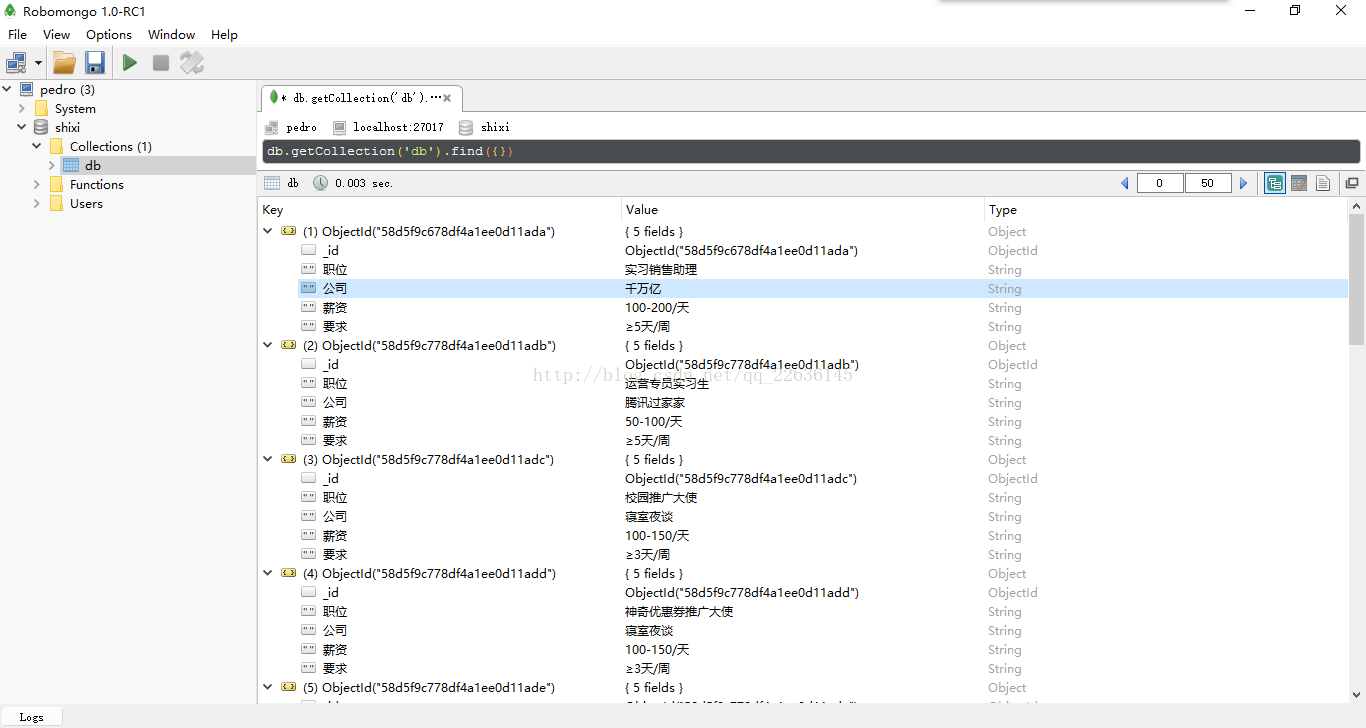
上图显示的便是爬下来的数据和存在数据库中的信息,信息共有1000条,总体能反映出武汉实习生的基本待遇情况。接下来我们便要进行数据分析了:
client=pymongo.MongoClient('localhost',27017)
db=client['shixi']
item=db['db']
low=0
medium=0
high=0
shigh=0
noknow=0
for i in item.find():
score=i['薪资'].strip().split('-')[0]
if score=='面议':
noknow=noknow+1
else:
grade=int(score)
if grade<=50:
low=low+1
elif grade>50&grade<=100:
medium=medium+1
elif grade>100&grade<=200:
high=high+1
elif grade>200:
shigh=shigh+1
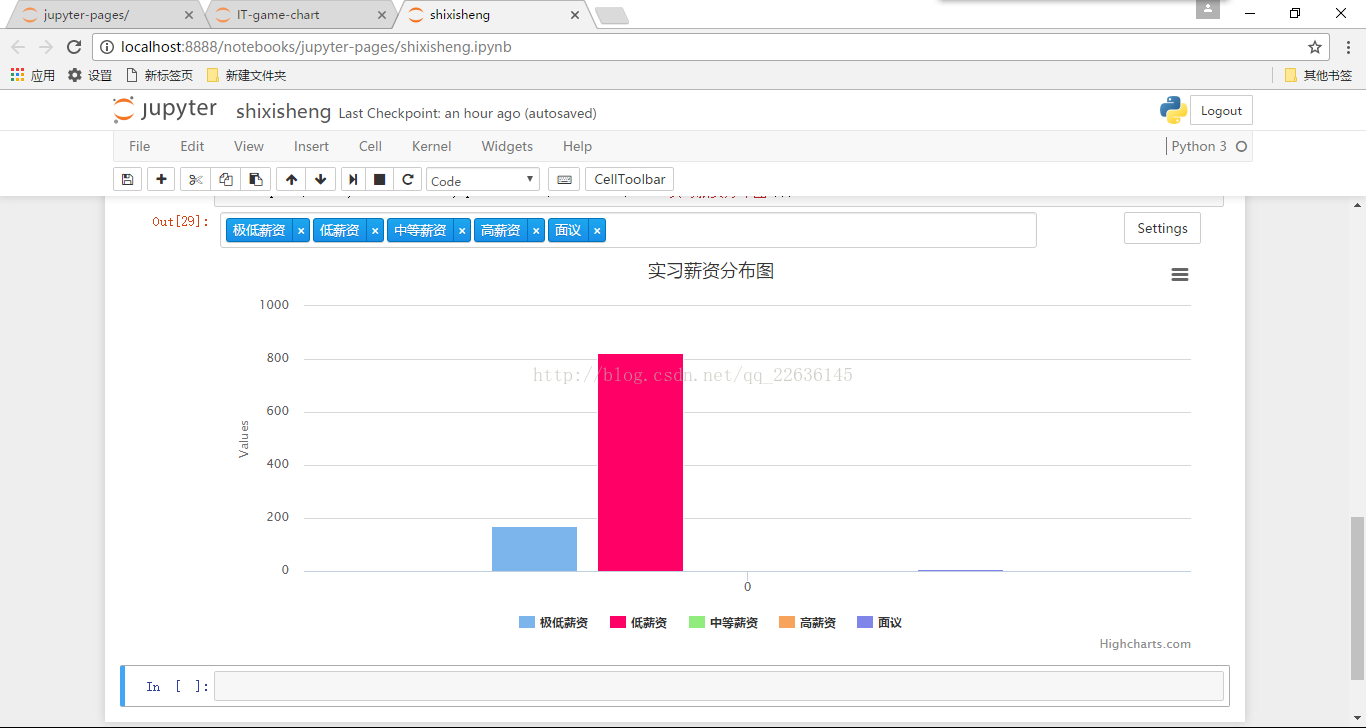
print(low,medium,high,shigh,noknow)我们从每条数据中得到‘薪资’这一项的类容并对它进行处理得到具体的薪资数值,其中主要运用到了python中string模块的strip()和split()方法。不知道的同学们可以去网上查阅一下相关资料。总之python很方便,方便到不行。
上面图片的底部便是这次统计所得到的统计结果,可以看到实习生的待遇是多么多么多么的差强人意。得到这些数据之后便要让它可视化。
series = [
{
'name': '极低薪资',
'data': [low],
'type': 'column'
}, {
'name': '低薪资',
'data': [medium],
'type': 'column',
'color':'#ff0066'
}, {
'name': '中等薪资',
'data': [high],
'type': 'column'
}, {
'name': '高薪资',
'data': [shigh],
'type': 'column'
},{
'name': '面议',
'data': [noknow],
'type': 'column'
}
]
charts.plot(series, show='inline',options=dict(title=dict(text='实习薪资分布图')))上面的代码便是其所用的python代码,一般这样的东西都很死,这个时候必须得用API。感兴趣的可以去查阅相关的API,一般都是英文的,就很气。泱泱华夏,巍巍中华什么就没有一个像样的第三方库。哎!
现在数据结果可以说是一目了然。写到这里本次的爬虫和简单的数据分析及可视化便要走入尾声了,希望这篇文章能给想学习python的同学们一点指导,如果你是高手希望你不吝赐教。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!