社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据库索引本质上是一种数据结构(存储结构+算法),目的是为了加快目标数据检索的速度。
1.索引的本质与原理?
2.索引的分类?
3.福利彩蛋
我们先看一个问题:
假设现在有100000条从0到10000且从大到小排列的整型数据,1条数据的大小假设(真的只是假设)是1KB,操作系统的每次I/O数据块(页)大小是8KB。
如果现在我要查找其中 50001 这个数据值,有如下几个方式:
1.最蠢的方式,遍历,每次遍历到一个值,就用这个值跟目标值做对比,如果不等于那么查找下一个。这样的话那么每次I/O是8条数据,目标数据在50001/8 约6600多次I/O 才能找到目标数据。
2.二分查找,最好一次性将100000条数据全部读到内存,这样查找也是很快的。
但是即使二分查找很快,但这些数据也不能单单通过一次I/O全部进入内存,进行运算。
那么怎样在I/O 块大小 的限制下快速利用二分查找找到目标值呢?我们得引入新的数据结构,B+树正好可以解决上述I/O块大小的限制,解决限制不是说增大了限制范围,而是我们在此限制上改变了数据的存储结构,即在同等限制条件下,快速检索到目标数据,如下是B+树的原理讲解:
注意,我们主要讲解索引的原理,没有必要过于纠结B+树的各种操作,及代码实现
1.1 B+ 树
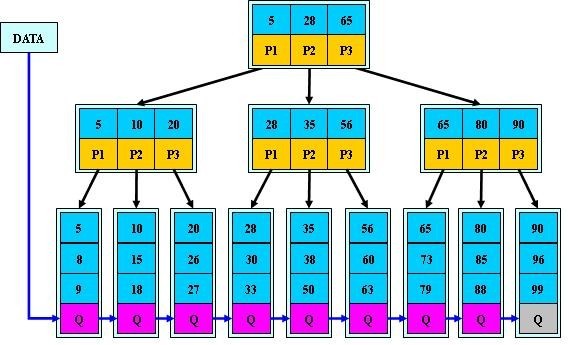
1.图上蓝色的块为关键字,我们发现所有的关键字最终都会被包含在叶子节点当中。
图上的黄色区块表示的是子树的指针域,比如根节点下的P2指向的就是28-65之间的索引。
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大
的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大
(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
现在我们来看下查找数据 60 的 查找过程,如下所示:
1.I/O第一次:读入5、28、65 数据块,在此同级别节点块上,60在28到65之间(其实是二分查找),那走P2指针指向的子树。
2.I/O第二次:读入28、35、56 数据块,在此同级别节点块上,60大于56,所以走P3指针指向的子树(上图中就是叶子节点)。
3.I/O第三次:读入叶子节点,在这个叶子节点中,使用二分查找算法找到目标值60。
由上述查找过程所示统共需要三次I/O就能查到目标值,性能大大提升。
InnoDB 主键使用的是聚簇索引,MyISAM 不管是主键索引,还是二级索引使用的都是非聚簇索引。
下图形象说明了聚簇索引表(InnoDB)和非聚簇索引(MyISAM)的区别:
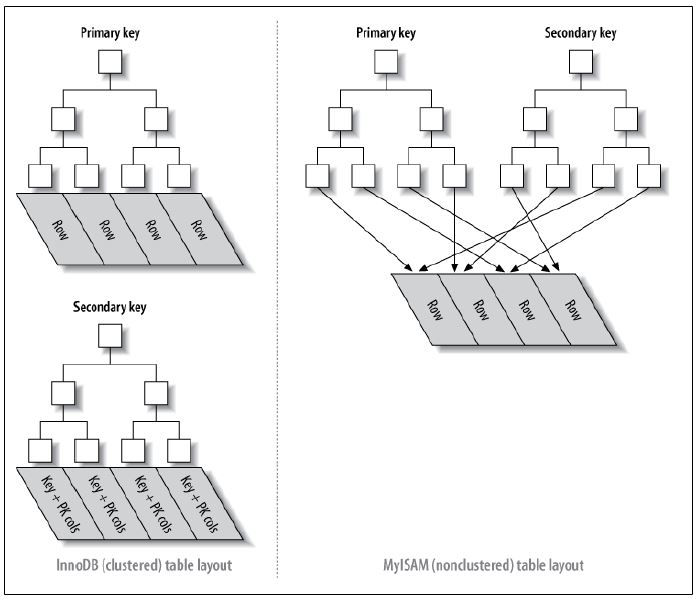
1.对于非聚簇索引表来说(右图),表数据和索引是分成两部分存储的,主键索引和二级索引存储上没有任何区别。使用的是B+树作为索引的存储结构,所有的节点都是索引,叶子节点存储的是索引+索引对应的记录的地址。
2.对于聚簇索引表来说(左图),表数据是和主键一起存储的,主键索引的叶结点存储行数据(包含了主键值),二级索引的叶结点存储行的主键值。使用的是B+树作为索引的存储结构,非叶子节点都是索引关键字,但非叶子节点中的关键字中不存储对应记录的具体内容或内容地址。叶子节点上的数据是主键与具体记录(数据内容)。
聚簇索引的优点
1.当你需要取出一定范围内的数据时
,用聚簇索引也比用非聚簇索引好。
2.当通过聚簇索引查找目标数据时理论上比非聚簇索引要快,因为非聚簇索引定位到对应主键时还要多一次目标记录寻址,即多一次I/O。
聚簇索引的缺点
1.插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
2.更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
3.二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
二级索引的叶节点存储的是主键值,而不是行指针(非聚簇索引存储的是指针或者说是地址),这是为了减少当出现行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多的空间。
4.采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距,聚簇索引遍历所有的叶子节点,非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有记录值,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
唯一索引
主键就是唯一索引,但是唯一索引不一定是主键,唯一索引可以为空,但是空值只能有一个,主键不能为空。
普通唯一索引:单个字段上建立唯一索引,需要此字段所在的列上不能有重复的值,属于二级索引。
复合唯一索引:多个字段上联合建立唯一索引,属于二级索引。
覆盖索引
查找的目标数据, 包含在索引中,如建立idx_colum1_colum2.
select colum1 from table where colum1 = ? and colum2 > ?
通过查询索引就能确定最终的数据,不用再利用叶子节点中存储的主键值去查询对应的数据。
覆盖索引的性能是极高的。
索引原理篇讲述完,下一篇讲解索引的优化,以及 explain 工具的使用。
职位:腾讯OMG 广告后台高级开发工程师;
Base:深圳;
场景:海量数据,To B,To C,场景极具挑战性。
基础要求:
熟悉常用数据结构与算法;
熟悉常用网络协议,熟悉网络编程;
熟悉操作系统,有线上排查问题经验;
熟悉MySQL,oracle;
熟悉JAVA,GoLang,c++其中一种语言均可;
可内推,欢迎各位优秀开发道友私信[微笑]
期待关注我的开发小哥哥,小姐姐们私信我,机会很好,平台对标抖音,广告生态平台,类似Facebook 广告平台,希望你们用简历砸我~
联系方式 微信 13609184526
博客搬家:大坤的个人博客
欢迎评论哦~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
