社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Mysql数据库中索引
在Mysql索引使用中,常常出现索引性能需要考虑的问题,那我们是否应当对索引原理进行深入思考。
Mysql中不同的存储引擎使用的索引原理是不同的,下面介绍三种类型的索引类型B-tree、B+tree、hash。
什么是Btree
Btree是一种高效的数据库存储结构,具体结构形式如下图: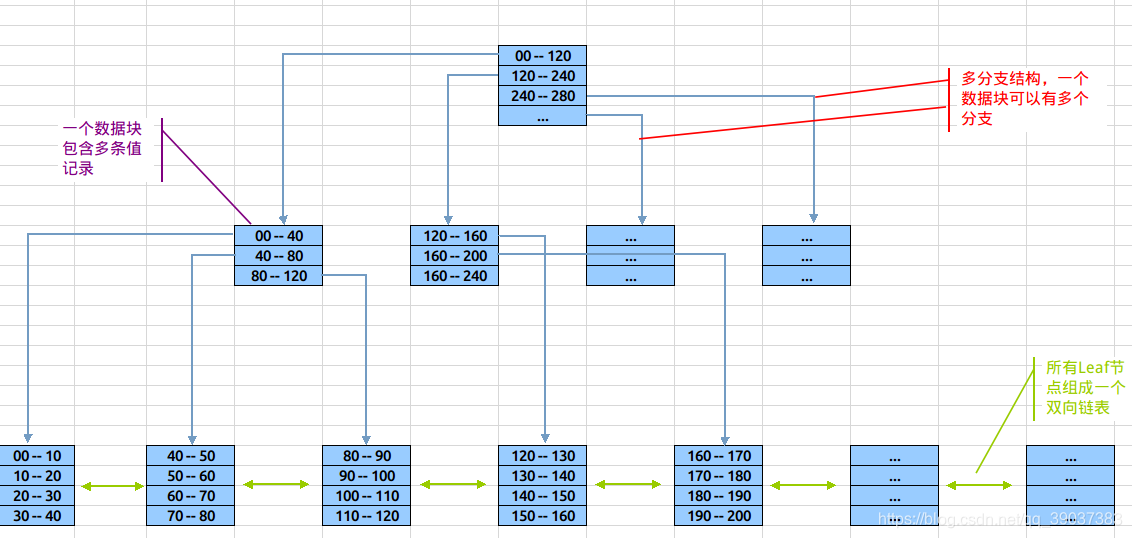
什么是平衡二叉树
我们在高效搜索的过程中,二叉搜索会提高我们搜索的效率,而平衡二叉树正是二分搜索的一种结构实现方式,这种树状结构大大减少无关数据的搜索,提高了搜索性能,使二分法搜索得到完美实现。
平衡二叉树结构组成条件为:非叶子节点只能允许最多两个子节点存在,每一个非叶子节点数据分布规则为左边的子节点小当前节点的值,右边的子节点大于当前节点的值(这里值是基于自己的算法规则而定的,比如hash值);如下图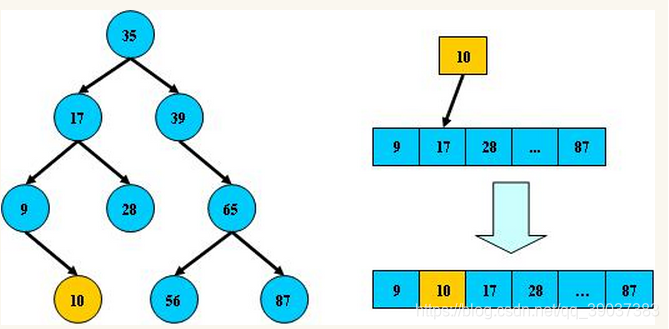
红黑树
我们在构建平衡二叉树时,会出现数值呈线性区分,导致破坏树状结构入下图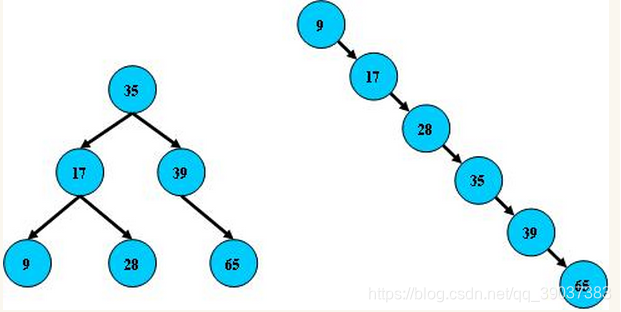
这时我们就要使用算法对平衡二叉树进行重新规定,常见的算法有:ALK、伸展树、红黑树等等,这里我们着重介绍红黑树,
红黑树是一种特殊的平衡二叉树,它是将二叉树的所有根与节点分为红色与黑色两种类别再进行规范,下面介绍它的性质:
1.不能出现两个连续的红色节点
2.根节点必须为黑色
3.每个到子节点的路径上黑节点的数目都相同
4.节点必须为红色或者黑色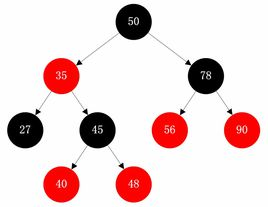
Mysql中MyISAM和Innodb的索引实现原理
MyISAM和Innodb两种存储引擎都是使用B+tree来进行索引的实现,但是二者却有很大区别
1.MyISAM索引的实现是使用B+tree树进行查找的,但是MyISAM索引的实现运用非聚集索引的形式进行搜索的,它在data域中存储的为我们数据的地址值,通过主索引或者辅助索引找到相对应的地址值,然后通过地址值再找到对应的数据并拿出,具体流程如下图: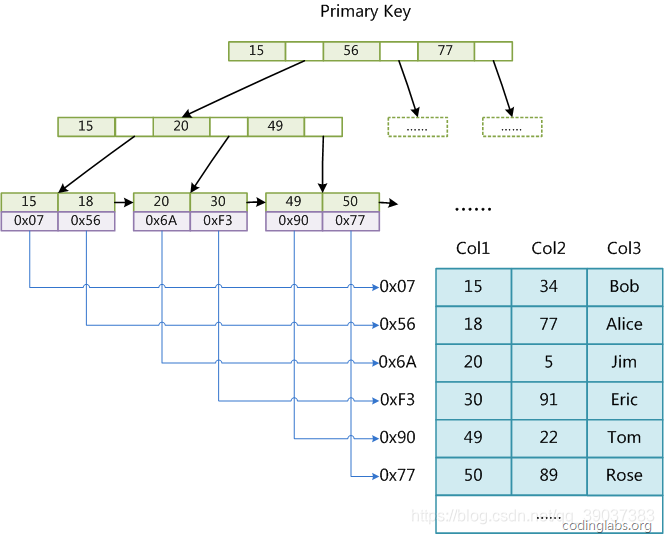
在图中Col1为主索引,而Col2为辅助索引,在B+tree结构中 辅助索引可以重复但是主索引不可重,我们称这种数据的搜索方式为非聚集索引,下面我们会对聚集性索引进行介绍
2.Innodb在Mysql中也是一种常用的存储引擎,Innodb与MyISAM相同同样是使用B+tree数据库结构,但是与之不同的是Innodb在进行操作时,在Innodb的B+tree结构中叶节点除了存储主索引与辅助索引以外还直接在data域中存储着相关数据,而不是通过地址值来进行获取,这种方式的索引我们常常称为聚集性索引,如下图: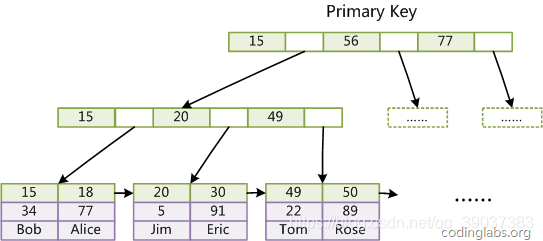
MySQL中hash索引形式
当然在Mysql中,也有一些存储引擎使用的是hash存储形式,hash存储形式有着比B+tree更加高效的索引效果,但是hash存储不能进行范围查询,只能进行 in “=” 操作,对数据的查询具有局限性。
在hash后,数据不能能与之前未进行hash的数据进行交互导致局限性,这是无法避免的/
Mysql的索引选择与思考
这时我们应当思考,同样拥有高性能的红黑树,Mysql为什么还要选择B+tree这种结构,在深度方面红黑树比B+tree有着更好的控制,我们从Mysql的主存存储原理与磁盘存储原理中去探究就会发现,B+tree在创建每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
这样就使磁头对磁道的操作大大减少,说明B+tree这种结构在物理级实现还是非常高效的,在去磁头去做每次I/O的过程中,渐进复杂度大大减少,相比之下,红黑树的结构,操作次数并没有这么简单,还是逐级读取,所以这体现了B+tree的优势,也是最终MySQL选择B+tree的原因。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
