社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据结构中的堆是一种特殊的二叉树,不同于 Java 内存模型中的堆。
堆必须符合以下两个条件:
从第一点可以知道,堆适合用数组来存储。
第二点中,若父节点都大于等于左右子节点,则被称为大顶堆,反之则为小顶堆。
如图,为一个大顶堆,
注意:堆首先得符合完全二叉树的特点,否则不是堆。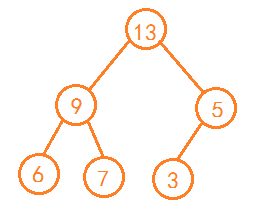
【下面代码均以大顶堆为例】
完全二叉树采用数组存储最省空间,并且对 CPU 缓存较链表友好。
如图,采用数组表示并空出 0 号位置,节点i的父节点为2xi,左右子节点分别为i/2和i/2+1。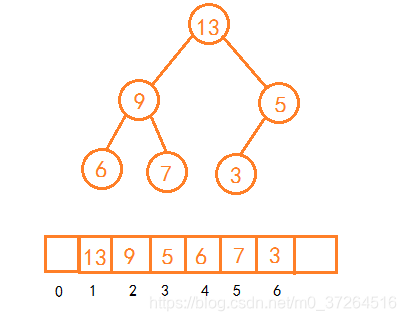
在堆尾(即数组末尾)插入数据,会导致破坏堆的特性,如图:
因此需要将被破坏的堆重新调整为堆,这个过程被称为堆化,堆化的操作可以自上而下,也可以自下而上。
图中插入元素8后,打破了大顶堆的特性,将元素8向上与其父节点比较,判断是否交换,若交换,则继续向上比较,直到所有父子节点符合要求。
代码实现:
public class Heap {
private int[] heapData; // 数组,从下标 1 开始存储数据
private int n; // 堆可以存储的最大数据个数
private int count; // 堆中已经存储的数据个数
public Heap(int capacity) {
heapData = new int[capacity + 1];
n = capacity;
count = 0;
}
public void insert(int data) {
if (count >= n)
return; // 堆满了
heapData[++count] = data;
int i = count;
while (i/2 > 0 && a[i] > a[i/2]) { // 自下往上堆化
swap(heapData, i, i/2); //交换下标为 i 和 i/2 的两个元素
i = i/2;
}
}
}
如图,删除堆顶元素后,如何堆化?
通过自上而下的堆化后,发现:虽然已经符合堆的大小规则,但是确不符合完全二叉树的定义了。
改进
删除堆顶元素后,将堆尾元素放到堆顶,再进行堆化操作。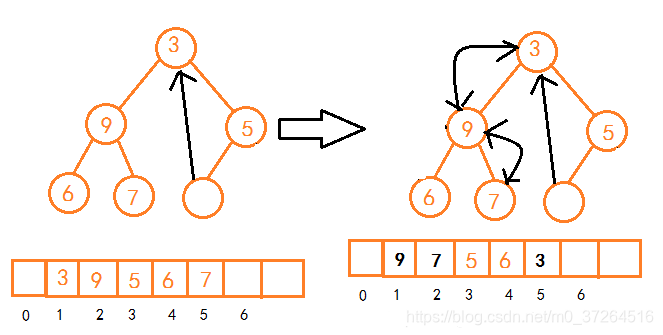
代码实现:
public void removeMax() {
if (count == 0)
return -1; // 堆中没有数据
heapData[1] = heapData[count];
--count;
heapify(heapData, count, 1);
}
private void heapify(int[] heapData, int n, int i) {
// 自上往下堆化
while (true) {
int maxPos = i;
int left = i*2;
int right = i*2+1;
if (left <= n && a[i] < heapData[left])
maxPos = left;
if (right <= n && heapData[maxPos] < heapData[right])
maxPos = right;
if (maxPos == i)
break;
swap(heapData, i, maxPos);
i = maxPos;
}
}
从前面的分析可知道,堆化的对象是一棵完全二叉树,并且自上而下或自下而上以高度为单位进行比较交换,因此堆化的时间复杂度与树的高度直接相关。
完全二叉树的高度为:,因此,删除、插入元素时间复杂度为 O()。
以大小为k的大顶堆为例,大顶堆的顶部元素为最大的值,我们将它与堆尾元素交换,再将前k-1个元素进行堆化,重复上述操作,直到堆中元素只剩 1 个为止,最后得到数据依次从小到大排列。
代码实现:
// n 表示数据的个数,数组 heapData 中的数据从下标 1 到 n 的位置。
public static void heapSort(int[] heapData, int n) {
buildHeap(heapData, n);//建堆
int k = n;
while (k > 1) {
swap(heapData, 1, k);
--k;
heapify(heapData, k, 1);
}
}
由代码可知,堆排序是一种原地排序算法,因此,空间复杂度为O(1)。
建堆过程时间复杂度为O(n),排序过程时间复杂度为O(nlog n),因此堆排序的时间复杂度为O(nlog n)。
虽然堆排序的时间复杂度与快速排序一样,但是实际开发中依然还是采用快速排序比较多,为什么呢
静态数据集合
针对静态数据集合,我们可以通过数据集合建立大小为k的堆,若是大顶堆,则堆顶元素为第 k 小元素,否则为第 k 大元素。
动态数据集合
针对动态数据集合,我们可以一直维护一个大小为k的堆,增加元素时,将元素与堆顶元素比较,若为大顶堆,并且比对顶元素小,则替换,再堆化,得到新的第 k 小元素。
具体案例与代码:LeetCode:703. Kth Largest Element in a Stream
队列:先进先出,后进后出。
优先队列:优先级高的先出队。
堆可以直接看做一个优先队列,入队,即往堆中添加元素,并且按照优先级堆化,而出队时,即堆顶元素为优先级最高的元素。
Java 中的 PriorityQueue 是优先级队列的一种实现。
一组具有n个元素的有序数据中,若元素个数为偶数,则 和 位置的元素取一个作为中位数,若元素个数为偶数,则中位数在 位置。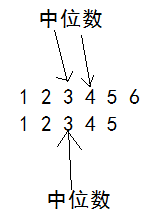
对于静态数据,中位数是固定的,只需要排序后直接获取中位数即可。即便排序比较耗时,但只需一次排序,所以总体时间复杂度还能接受。
但对于动态数据集合,由于数据是不断变化的,因此中位数也是不断变化的,若每次都需要重新排序来获取中位数,则时间复杂度比较高,因此,考虑采用同时维护两个堆来实现,大顶堆中存一半数据,小顶堆中存一半数据,并且小顶堆的数据都大于大顶堆的数据。
元素个数为偶数时,取其中一个堆的堆顶元素即为中位数。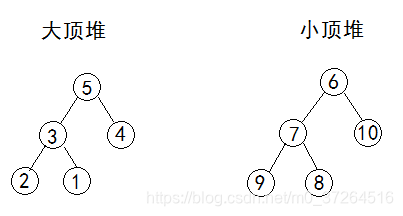
元素个数为奇数时,大顶堆存 个数,小顶堆存 个数,小顶堆堆顶元素为中位数。(也可以设置为大顶堆存 个数,则大顶堆堆顶元素为中位数)
当数据增加时,导致两个堆的元素个数比例失调,所以,应该如何进行调整呢?
可以从元素多的堆中,不停的将堆顶元素转移到另一个堆,直到两个堆元素比例恢复平衡,其中,堆化的操作时间复杂度为O(log n),而取中位数的操作的时间复杂度为O(1),因此整体时间复杂度为O(log n)。
扩展
在两个堆调整时,我们提到了两个堆的元素比例,在求中位数的场景中,比例为1:1。
由此可以想到,是否可以求其他比例下的数据呢,比如,我们要求 60 百分位的数(假设有 100 个数,并且正序,第 60 个数即为 60 百分位的数),则大小顶堆的比例为3:2。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
