Producer :消息生产者,就是向 kafka broker 发消息的客户端。
Consumer :消息消费者,向 kafka broker 取消息的客户端
Topic :名称。
Consumer Group (CG):这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 CG。topic 的消息会复制(不是真的复制,是概念上的)到所有的 CG,但每个 partion 只会把消息发给该 CG 中的一个consumer。如果需要实现广播,只要每个 consumer 有一个独立的 CG 就可以了。要实现单播只要所有的 consumer 在同一个 CG。用 CG 还可以将 consumer 进行自由的分组而不需要多次发送消息到不同的 topic。
Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
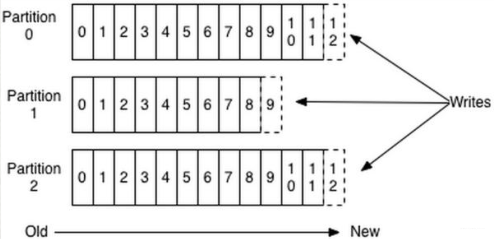
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给 consumer,不保证一个 topic 的整体(多个 partition 间)的顺序。
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是00000000000.kafka
Replication:Kafka 支持以 Partition 为单位对 Message 进行冗余备份,每个 Partition 都可以配置至少 1 个 Replication(当仅 1 个 Replication 时即仅该 Partition 本身)。
Leader:每个 Replication 集合中的 Partition 都会选出一个唯一的 Leader,所有的读写请求都由Leader 处理。其他 Replicas 从 Leader 处把数据更新同步到本地,过程类似大家熟悉的 MySQL中的 Binlog 同步。每个 Cluster 当中会选举出一个 Broker 来担任 Controller,负责处理 Partition的 Leader 选举,协调 Partition 迁移等工作。
ISR(In-Sync Replica):是 Replicas 的一个子集,表示目前 Alive 且与 Leader 能够“Catch-up”的Replicas 集合。 由于读写都是首先落到 Leader 上,所以一般来说通过同步机制从 Leader 上拉取数据的 Replica 都会和 Leader 有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该 Replica 踢出 ISR。每个 Partition 都有它自己独立的 ISR。
下载安装包:wget http://mirrors.shuosc.org/apache/kafka/1.0.0/kafka_2.11-1.0.0.tgz
解压,修改目录名:tar -zxvf kafka_2.11-1.0.0.tgz -C /export/servers/cd /export/servers/mv kafka_2.11-1.0.0 kafka
修改配置文件cp /export/servers/kafka/config/server.properties /export/servers/kafka/config/server.properties.bakvi /export/servers/kafka/config/server.properties
#broker 的全局唯一编号,不能重复host.name 为本机 IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessful 错误!
分发安装包
依次修改各broker(各个服务器)的broker.id,不得重复
启动集群nohup /export/servers/kafka/bin/kafka-server-start.sh /export/servers/kafka/config/server.properties >/dev/null 2>&1 &https://blog.csdn.net/loongshawn/article/details/50514018 )command >/dev/null 2>&1 &
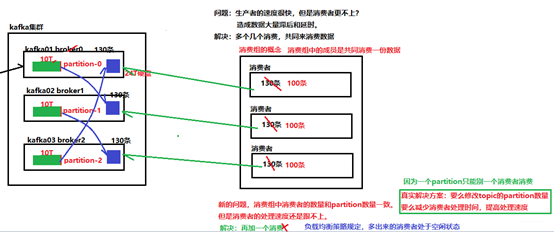
Consumer和Topic的关系
每个 group 中可以有多个 consumer,每个 consumer 属于一个 consumer group;通常情况下,一个 group 中会包含多个 consumer,这样不仅可以提高 topic 中消息的并发消费能力,而且还能提高"故障容错"性,如果 group 中的某个 consumer 失效那么其消费的 partitions 将会有其他 consumer 自动接管。
对于 Topic 中的一条特定的消息,只会被订阅此 Topic 的每个 group 中的其中一个 consumer 消费,此消息不会发送给一个 group 的多个 consumer;那么一个 group 中所有的 consumer 将会交错的消费整个 Topic,每个 group 中 consumer 消息消费互相独立,我们可以认为一个 group 是一个"订阅"者。
在 kafka 中,一个 partition 中的消息只会被 group 中的一个 consumer 消费( 同一时刻);一个 Topic 中的每个 partions,只会被一个"订阅者"中的一个 consumer 消费,不过一个 consumer 可以同时消费多个 partitions 中的消息。
kafka 的设计原理决定,对于一个 topic,同一个 group 中不能有多于 partitions 个数的 consumer 同时消费,否则将意味着某些 consumer 将无法得到消息。kafka 只能保证一个 partition 中的消息被某个 consumer 消费时是顺序的;事实上,从 Topic角度来说, 当有多个 partitions 时,消息仍不是全局有序的。
Kafka消息的分发
kafka 集群中的任何一个 broker 都可以向 producer 提供 metadata 信息,这些 metadata 中包含"集群中存活的 servers 列表"/"partitions leader 列表"等信息;
当 producer 获取到 metadata 信息之后, producer 将会和 Topic 下所有 partition leader 保持socket 连接;
消息由 producer 直接通过 socket 发送到 broker,中间不会经过任何"路由层",事实上,消息被路由到哪个 partition 上由 producer 客户端决定;比如可以采用"random"“key-hash”“轮询"等, 如果一个 topic 中有多个 partitions, 那么 在producer 端实现” 消息均衡分发" 是必要的。
在 producer 端的配置文件中,开发者可以指定 partition 路由的方式。Producer 消息发送的应答机制
Consumer的负载均衡 consumer.id 排序: C0,C1
Kafka的文件存储机制(重点:分片-副本机制)
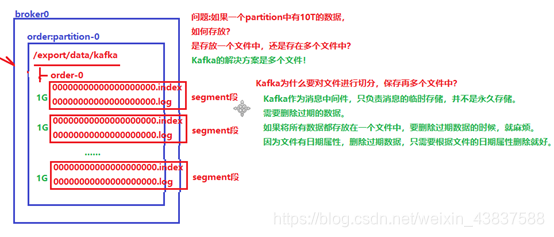
在Kafka文件存储中,同一个 topic下有多个不同partition,每个 partition 为一个目录,partiton命名规则为 topic 名称+有序序号,第一个 partiton 序号从 0 开始,序号最大值为 partitions数量减 1。
每个 partion(目录)相当于一个巨型文件被平均分配到多个大小相等 segment(段)数据文件中。 但每个段 segment file 消息数量不一定相等,这种特性方便 old segment file 快速被删除。默认保留 7 天的数据。
每个 partiton 只需要支持顺序读写就行了,segment 文件生命周期由服务端配置参数决定。(什么时候创建,什么时候删除)
Kafka Partition Segment
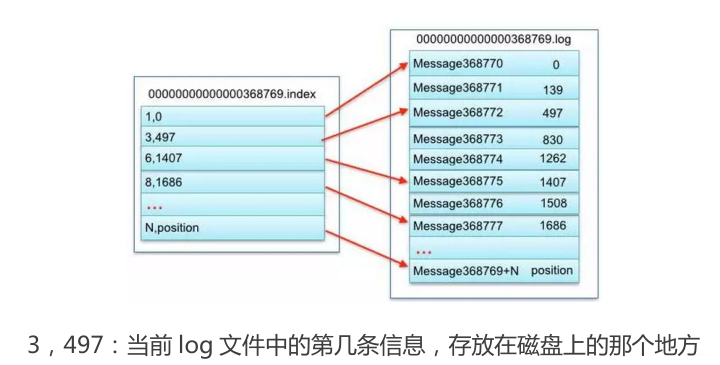
Segment file 组成:由 2 大部分组成,分别为 index file 和 data file,此 2 个文件一一对应,成对出现,后缀".index"和“.log”分别表示为 segment 索引文件、数据文件。
Segment 文件命名规则:partion 全局的第一个 segment 从 0 开始,后续每个 segment文件名为上一个 segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用 0 填充。
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中 message 的物理偏移地址。
消息不丢失机制
生产者端消息不丢失 消息生产分为同步模式和异步模式
消息确认分为三个状态
在同步模式下
在异步模式下 如果broker迟迟不给ack,而buffer又满了。
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。