社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
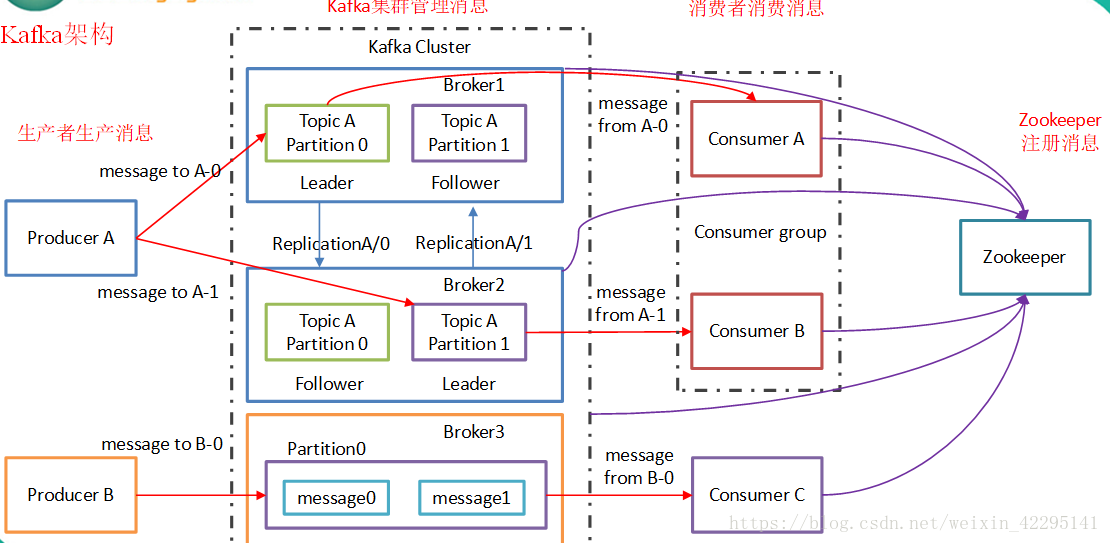
架构图
1)Producer :消息生产者,就是向kafka broker发消息的客户端。
2)Consumer :消息消费者,向kafka broker取消息的客户端
3)Topic :可以理解为一个队列。
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
第一台机器修改kafka配置文件server.properties
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/export/servers/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=node01
第二台 (同一只需改这两个即可)
broker.id=1
host.name=node02
第三台同理
broker.id=2
host.name=node03
进入kafka的目录下 后台启动命令 三台都要启动
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
关闭集群
bin/kafka-server-stop.sh stop
创建topic
kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic kafkatopic --zookeeper node01:2181,node02:2181,node03:2181
查看 是否创建成功(删除是delete 加上topic名)
bin/kafka-topics.sh --zookeeper node03:2181 --list
模拟生产者
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic kafkatopic
模拟消费者(会接受所有的消息删除from-beginning 会接收活着的消息)
kafka-console-consumer.sh --from-beginning --topic kafkatopic --zookeeper node01:2181,node02:2181,node03:2181
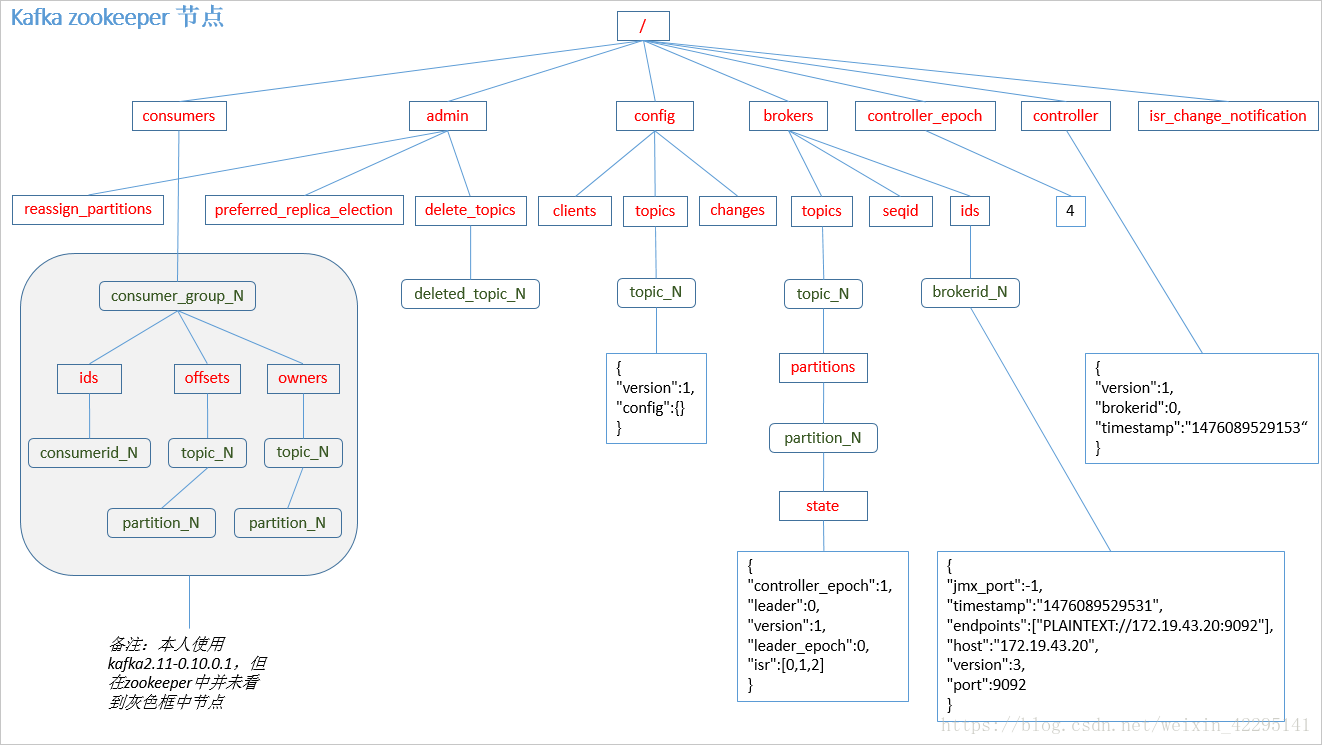
1)producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
2)producer将消息发送给该leader
3)leader将消息写入本地log
4)followers从leader pull消息,写入本地log后向leader发送ACK
5)leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件)
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
注意:producer不在zk中注册,消费者在zk中注册
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!