社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
教程 http://www.runoob.com/mysql/mysql-install.html
这里要注意的几点:
必须要以管理员身份打开cmd 命令行工具;
当出现 ‘服务器无法启动’ 时,通常是端口被占用了,我的解决方法是:
在MySQL的bin目录下 输入 msqld --remove 删除掉服务,再把安装MySQL目录下的data文件夹也删除,重新执行以下三条指令即可完成
mysqld --initialize-insecure
mysqld --install
net start mysql
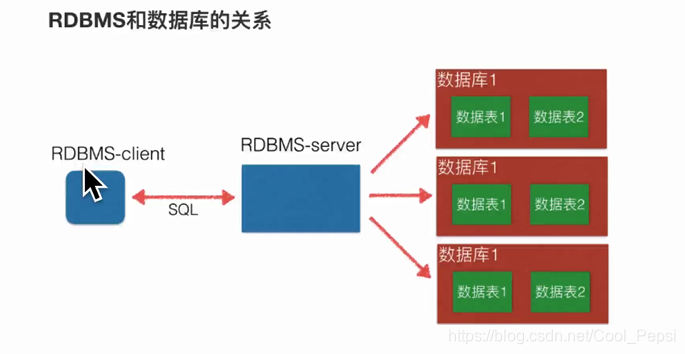
可以这样理解:一个excel文件就好比一个数据库,数据库是数据表的集合。excel中的每一个sheet就好比一个数据表(二维表),多个集合起来就是一个数据库,而数据表是数据的集合。
所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
表中的任何列都可以作为主键,只要它满足以下条件:
1)任意两行都不具有相同的主键值;
2)每一行都必须具有一个主键值(主键列不允许 NULL值);
3)主键列中的值不允许修改或更新;
4)主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
主键通常定义在表的一列上,也可以一起使用多个列作为主键。在使用多列作为主键时,上述条件必须应用到所有列,所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
先举个例子。若有两个表基本表A,信息表B,C是A的主键,而B中也有C字段,则C就是表B的外键。
在数据库中,常常不只是一个表,这些表之间也不是相互独立的,不同的表之间需要建立一种关系,才能将它们的数据相互沟通,而在这个沟通过程中,就需要表中有一个字段作为标志,不同的记录对应的字段取值不能相同,也不能是空白的,通过这个字段中不同的值可以区别各条记录。


alter table students modify age tinyint unsigned
tinyint(M) unsigned zerofill;
tinyint(5) unsigned zerofill 若插入值为9,则00009
Not null Default 0 例如 name varchar(10) not null default ‘’
则在新建一个字段时就默认填充0。
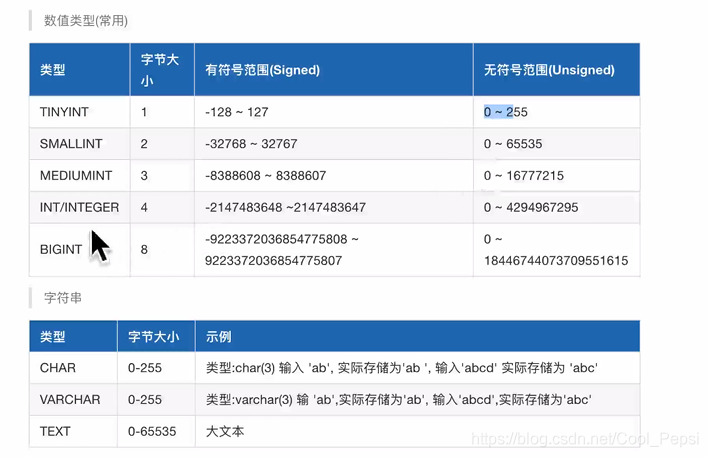
float(M,D) / decimal(M,D)
decimal更精确,推荐。
M : 精度(总位数,不包含点)
D : 标度(小数位)
float(6,2)范围在-9999.99到+9999.99之间。当然float(6,2) unsigned,则0到+9999.99。
若插入82.896则最后显示是82.90
char 和 varchar
char : 定长字符串,char(M),M代表宽度,0<=M<=255,即可容纳的字符数(不是字节,例如一个汉字占3个字节,但一样可以插入8个汉字)
varchar : 变长,varchar(M),M代表宽度,0<=M<=65535,即可容纳的字符数
区别:
char定长:M个字符,若存的小于M个字符,设N个字符,还是实占M个字符,利用率N/M<=100%;不够则用空格补齐,往回取的时候把后面的空格去掉,但是呢你存入的值尾部本来就有空格,往回取的时候后面的空格就丢失了,例如:存’list ‘,取回来是’list’;
varchar变长:存的小于M个字节,设N个字节,N<=M,实占N个,但是总得有一个信息标记着你存了多少个字节,所以这个信息占1-2个字节,所以最大可以存到65535个字节(转换到utf8大概可以从22000个字符左右),利用率N/(N+1-2)<100%。
所以:1. M不同;2. 实占空间不同,空间利用率不同;3. 存入时尾部的空格会丢失与否;4. 速度不同,char速度更快。
选择原则:1. 空间利用率 如:四字成语表 char(4),个人简介 varchar(140);2. 速度 如:用户名:char 本来用户名也就那么短,优先考虑速度
这里还有一个枚举类型:enum()
但是这和关系型数据库的设计理念有悖。数据表中存储的数据是原子型,即不可再分割,而枚举类型,例如gender enum(‘男’,‘女’),这里存储的是一种结构,里面可以再分割;如果要符合原子型,可以gender tinyint(1),并注释1代表男,0代表女。

#语法:
create view 视图名 as select 语句
为什么要用视图?
视图的algorithm:
Algorithm = merge/ temptable/ undefined
Merge: 当引用视图时,引用视图的语句与定义视图的语句合并
Temptable: 当引用视图时,根据视图的创建语句建立一个临时表
Undefined: 未定义,让系统自动帮你选
Merge,意味着视图只是一个规则,语句规则,当查询视图时,把查询试图的语句(例如where,order by等)与创建视图的语句where子句合并,形成一条select,最终从表中进行查询
如:
创建视图的语句:create view g as select goods_id,shop_price from goods order by goods_id,shop_price desc;
查询试图的语句:select * from g group by goods_id;
最终相当于变成:select goods_id,shop_price from goods group by goods_id order by goods_id,shop_price desc;
就相当于将两句话分析合并成一句话在基表中查询。
而temptable是根据创建语句的瞬间创建一张临时表,然后查询视图的语句从该临时表查数据。
创建视图:create algorithm = temptable view g as select goods_id,shop_price from goods order by goods_id,shop_price desc;
查询视图:select * from g group by goods_id;
最终执行2句话,从goods取数据创视图放在临时表,然后在该临时表中查询。
申明表为utf8:
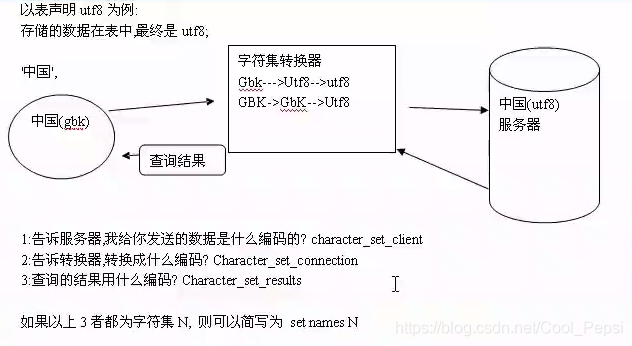
校对集就是字符集内部的排序规则,一个字符集有一种或多种校对集(就是有很多排序规则,看你怎么排)。以Utf8为例,我们默认使用utf8_general_ci规则,也可以指定使用utf8_bin(二进制)。
声明校对集 :create table (…) Charset utf8 collate utf8_bin;
用触发器,可以监视某表的变化,当发生某种变化时,触发某个操作。
能监视:增 删 改
能触发:增 删 改
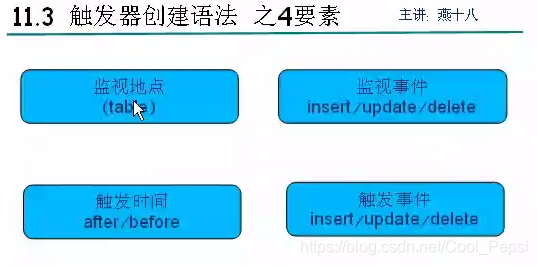
delimiter $ #这句话的意思是不再以 ; 作为一条语句结束标志,改成$
Create trigger triggerName
After/before insert/update/date/ on 表名 #在监视某张表 发生了某种操作 之后或之前
For each row #这句话是固定的
Begin
Sql语句; #触发操作
End$
因为在begin 和 end之间的SQL语句最后要加上; 并且有可能不止一条,每一条有;隔开,所以指定结束标志不能再是; 改成$
如何在触发器引用行的值
对于insert而言,新增的行用new来表示,行中每一列的值,用 new. 列名 来表示。
对于delete而言,删除的行用old来表示,行中每一列的值,用 old. 列名 来表示。
对于update而言,被修改的行:
修改前的数据用old来表示,行中每一列的值,用 old. 列名 来表示;
修改后的数据用new来表示,行中每一列的值,用 new. 列名 来表示。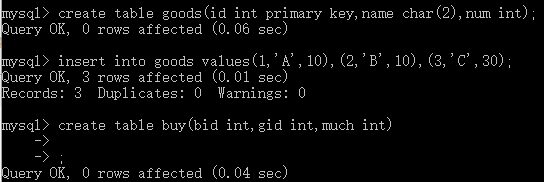
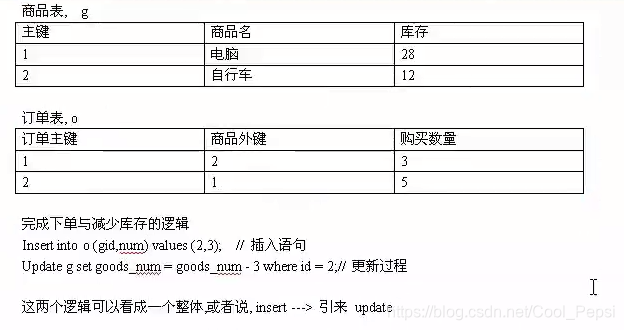
对于INSERT:
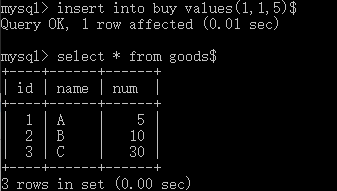
对于update:
如果不是更改数量,而是更改id:
before与after:
After 是先完成数据的增删改再触发,触发中的语句晚于增删改,无法影响前面的增删改动作。
Before是先完成触发,再增删改,触发的语句先于监视的增删改发生,我们有机会判断、修改即将发生的操作。例如本来这个操作本来就不合理,那么需要before来审查。
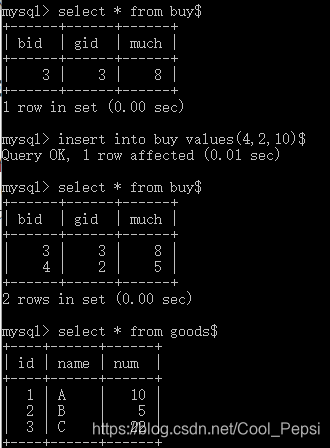
例题:若购买数量大于5被认为是恶意订单,强制将购买数量变成5.
存储引擎:数据库对同样的数据,有着不同的存储方式和管理方式。在mysql中,称为存储引擎。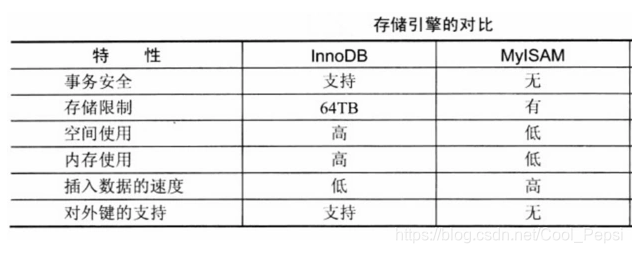
Myisam:批量插入速度快,不支持事务,锁表;
Innodb:批量插入速度慢,支持事务,锁行;
4个特性:
通俗说的事务,就是一组操作,要么全部执行,要么全部不执行 ---- 原子性(就是这组操作不能被分割了)
在所有的操作没有执行完毕之前,其他事务不能看见中间改变的过程(该事务下还是能看见的) ---- 隔离性 (先扣汇款人的钱,再加被汇款人的钱,必须都执行完成才能看到汇款人或者被汇款人金额的变化)
事务发生前和发生后,数据的总额依然匹配 ---- 一致性 (汇款人少了100,那被汇款人必须多100 ,不考虑手续费)
事务产生的影响不能撤销 ---- 持久性
开启事务
关于事务的引擎:选用InnoDB
开启事务:start transaction
SQL…
SQL…
commit 提交/rollback 回滚
注意:当一个事务commit或rollback时,该事务就结束了。
再注意:有些语句会造成事务的隐式提交,例如start transaction; SQL; start transaction; 前一个事务就隐式提交了。
系统运行中,增量备份与整体备份。
例:每周日整体备份一次,周一到周六备份当天。若周五出问题了,可以使用上周日的整体备份+周一到周四来恢复。
备份工具:系统默认是mysqldump,可以导出库和表。
对于表级的备份文件
mysql>use 库名
mysql>source 备份文件地址
针对表级备份
mysql -u 用户名 -p 密码 库名< 表级备份文件地址
索引:是针对数据所建立的目录
作用:加快查询速度
负面影响:降低增删改速度
案例:
设有表15列,10列上有索引,共500w行数据,如何快速导入?
索引创建原则
4. 不过度索引
5. 在where条件最频繁的列上加(查询最频繁的列)
6. 尽量索引散列值,过于集中的值加索引意义不大
索引类型:
普通索引:index 仅仅是加快查询速度
唯一索引:unique index 行上的值不能重复
主键索引:primary key 不能重复
主键必唯一,但是唯一索引不一定是主键索引;一张表只有一个主键索引,但是可以有一个或多个唯一索引
全文索引:fulltext index
查看一张表的所有索引:
show index from 表名
建立索引:
alter table 表名 add index / unique / fulltext [索引名] (列名)
alter table 表名 add primary key (列名) //不要加索引名,因为主键只有一个
删除索引:
删除非主键索引:alter table 表名 drop index 索引名;
删除主键索引:alter table 表名 drop primary key;
关于全文索引的使用
Match (全文索引名) against (‘keyword’);
关于全文索引的停止词
全文索引不针对非常频繁的词做索引
如this, is, you, my…
全文索引在mysql的默认情况下,对于中文意义不大
因为英文有空格,标点符号来拆成单词,进而对单词进行索引
而对于中文,没有空格来隔开单词,mysql无法识别每个中文词。
查看现有存储过程
show procedure status
删除存储过程
Drop procedure 存储过程的名字
调用存储过程
Call 存储过程名字
#创建存储过程
create procedure p1(n int,j char(1))
begin
if j = 'h'
select * from g where num > n ; #返回结果
else
select * from g where num <= n ;
end if;
end$
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
