社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
什么是数据规范化?
数据规范化是在设计关系型数据库时需要参考遵守的关系模式规范,可以用来判断一个关系模式是否需要分解
什么是数据的完整性约束?
使数据库中所有数据值处于正确的状态
1NF 每个属性不可再分
| D | 课程编号 | 教师姓名 |
|---|---|---|
| 01 | CS-101 | 张三 |
在上面的这个关系模式中,课程编号的CS-101表示计算机系的101号课程,这个属性可以分成系别和编号,如果在程序中有用到这个属性则需要额外的代码去分解并组合这两个属性,则此时不符合1NF
2NF 非主属性对主属性完全依赖 即:若有(AB)->C,则不存在A->C或者B->C
| 姓名 | 课程 | 教师 | 教师职称 | 教材 | 教室 | 上课时间 |
|---|
在上面这个关系模式中,姓名和课程决定了教材,并且课程也决定了教材,所以它不符合2NF.
产生的问题
1.插入异常 当需要插入一门新的课程时由于无法确定这个元组中的姓名,导致无法插入数据
2.删除异常 当需要删除一门课程时会把相应的学生信息也删除
3.更新异常 当需要更新课程信息时需要更新所有带有相同课程信息的数据
解决办法
将表分解为两个表
| 姓名 | 课程 | 教师 | 教师职称 | 教室 | 上课时间 |
|---|
| 课程 | 教材 |
|---|
3NF 非主属性之间不存在依赖(即非主属性与主属性之间不存在传递依赖)
| 姓名 | 课程 | 教师 | 教师职称 | 教室 | 上课时间 |
|---|
在上面的关系模式中,教师决定了教师职称,因为教师和教师职称都不是主属性,所以它不符合3NF
产生的问题
1.插入异常 当需要加入新的教师时时由于无法确定这个元组中的姓名和课程,导致无法插入数据
2.删除异常 当需要删除一位教师时会把相应的学生信息也删除
3.更新异常 当需要更新教师信息时需要更新所有带有相同教师信息的数据
解决办法
继续拆分表
| 姓名 | 课程 | 教师 | 教室 | 上课时间 |
|---|
| 教师 | 教师职称 |
|---|
BCNF 3NF+主属性之间不存在依赖
上述表中,姓名和课程两个主属性中不存在依赖,所以属于BCNF
什么是索引?
索引是一种帮助用户快速查询的数据结构。
什么是顺序索引?
一个按照顺序排列的索引,查找时使用二分法.
基本概念:
聚集索引: 记录的物理地址顺序和索引顺序相同也叫主索引,一般指主键上的索引.
非聚集索引: 记录的物理地址顺序和索引顺序不同,也叫副索引.
稠密索引: 文件中的每个记录都对应一个索引项
稀疏索引: 只有某些记录建立索引
搜索码: 用于查找记录的属性或属性集
稠密索引: 由于稠密索引的每个索引都对应一条记录,所以稠密索引的指针可以指向多条记录也可以指向具有相同记录块的第一个地址(此时需要稠密索引也是聚集索引),因此更新时要分为三种情况
插入:
删除:
稀疏索引: 由于稀疏索引只会指向一个数据块的第一个元素,所以更新时要分为索引中不包含此记录,索引中指向的是第一条记录但不是唯一的记录,索引指向的是第一条记录几种情况
插入:
删除:
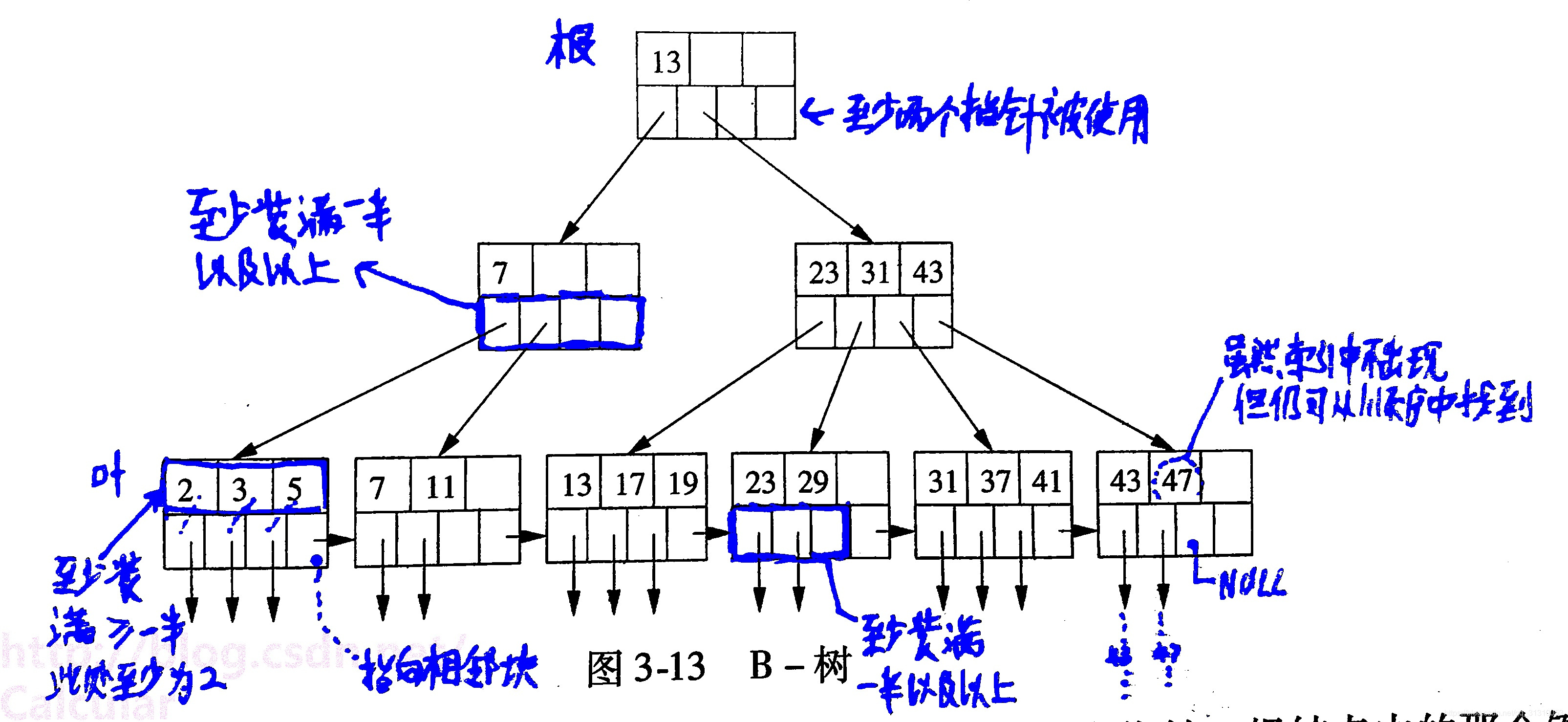
什么是B+树索引?
由于顺序索引随着文件增大,如果不进行重组的话索引的查找性能和顺序扫描的性能会下降,而B+树可以随着数据的插入和删除动态调整从而保证其执行效率.
为什么B+树索引能提升查找效率?
由于B+树是一个平横的树,因此从根节点查找到叶节点的路径较短,导致读取磁盘的次数较少,从而能够提升查找效率.
索引一定能提升查找效率吗?
在副索引上,当查询的数据量大于总量的30%时,效率不如全表扫描,因为此时每条记录的查找都要对索引进行查询,而查询索引需要额外的磁盘操作,当查询的数据量大时,会导致使用索引的效率不如顺序查找
什么时散列索引?
计算散列值,并根据散列值将数据映射到桶中
桶满后怎么办?
两种方法,一是使用溢出桶,二是使用下一个有空间的桶(线性探测法)
什么时位图索引?
把每一列当成一个二进制数,通过交计算来减少查找范围
select * from stu where id = 001假设ID上建立的是主索引,此时使用索引能提高搜索效率。select * from stu where name = '张山'假设name上建立了主索引但name 不是码,此时使用索引可以找到第一条满足name='张山'的记录,由于它是主索引所以满足条件的记录一定是连续存放的,所以只要拿出相应的数据块就能拿到所有满足条件的数据。age>20)A>num时可以提高查找效率,当选择条件是A<num时和顺 序查找的效率是一样的。select * from stu where id < 100 and score >80)id<100的值,然后再顺序查找到符合条件的记录select * from stu where id < 100时也会使用索引,而select * from stu where score < 80操作就不会使用索引,这是索引的前缀性质。如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
