社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
将Kafka中的JSON数据持久化存储到Hive表中,以供后期有查找的需求。
(看了很多讲解的博文,出了各种bug!饶了很多弯路!总结出来的经验就是一定要仔细看Flume的官方文档!!!!!!)
Kafka中的数据示例:
>{"id":1,"name":"snowty","age":25}
Hive表示例:
hive> desc hivetable;
OK
id int
name string
age int
Time taken: 0.162 seconds, Fetched: 3 row(s)
建表时要进行分桶、赋予事务性,需要对hive进行配置
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
<description>
Set to org.apache.hadoop.hive.ql.lockmgr.DbTxnManager as part of turning on Hive
transactions, which also requires appropriate settings for hive.compactor.initiator.on,
hive.compactor.worker.threads, hive.support.concurrency (true),
and hive.exec.dynamic.partition.mode (nonstrict).
The default DummyTxnManager replicates pre-Hive-0.13 behavior and provides
no transactions.
</description>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>
Whether Hive supports concurrency control or not.
A ZooKeeper instance must be up and running when using zookeeper Hive lock manager
</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
$ hive --service metastore & //先启动元数据服务
$ hive
hive> create database hivedatabase;
hive> create table hivetable(id int,name string,age int) clustered by(id) into 2 buckets stored as orc tblproperties('transactional'='true');
(不拷贝的话会有dependency的问题,困扰了我好久..)
$ sudo cp /opt/hive/hcatalog/share/hcatalog/hive-hcatalog-streaming-3.1.1.jar /opt/flume/lib/
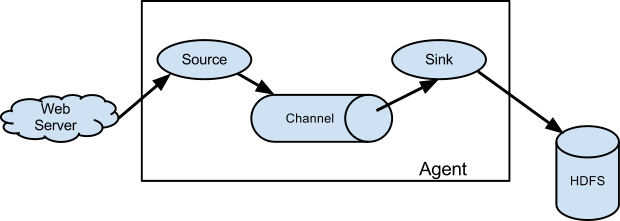
由图可知,flume中需要配置:
flume通过配置文件来运行,因此在`/opt/flume/conf`目录下创建` kafka2hive.conf`文件
1). 创建source、channel、sink:
a.sources=source_from_kafka
a.channels=mem_channel
a.sinks=hive_sink
2). 配置kafka source,参考官方文档,kafka的地址、topic必须配置:

例如:
a.sources.source_from_kafka.type=org.apache.flume.source.kafka.KafkaSource
a.sources.source_from_kafka.batchSize=10
a.sources.source_from_kafka.kafka.bootstrap.servers=localhost:9092
a.sources.source_from_kafka.topic=test
a.sources.source_from_kafka.channels=mem_channel
a.sources.source_from_kafka.consumer.timeout.ms=1000
3).配置hive sink:
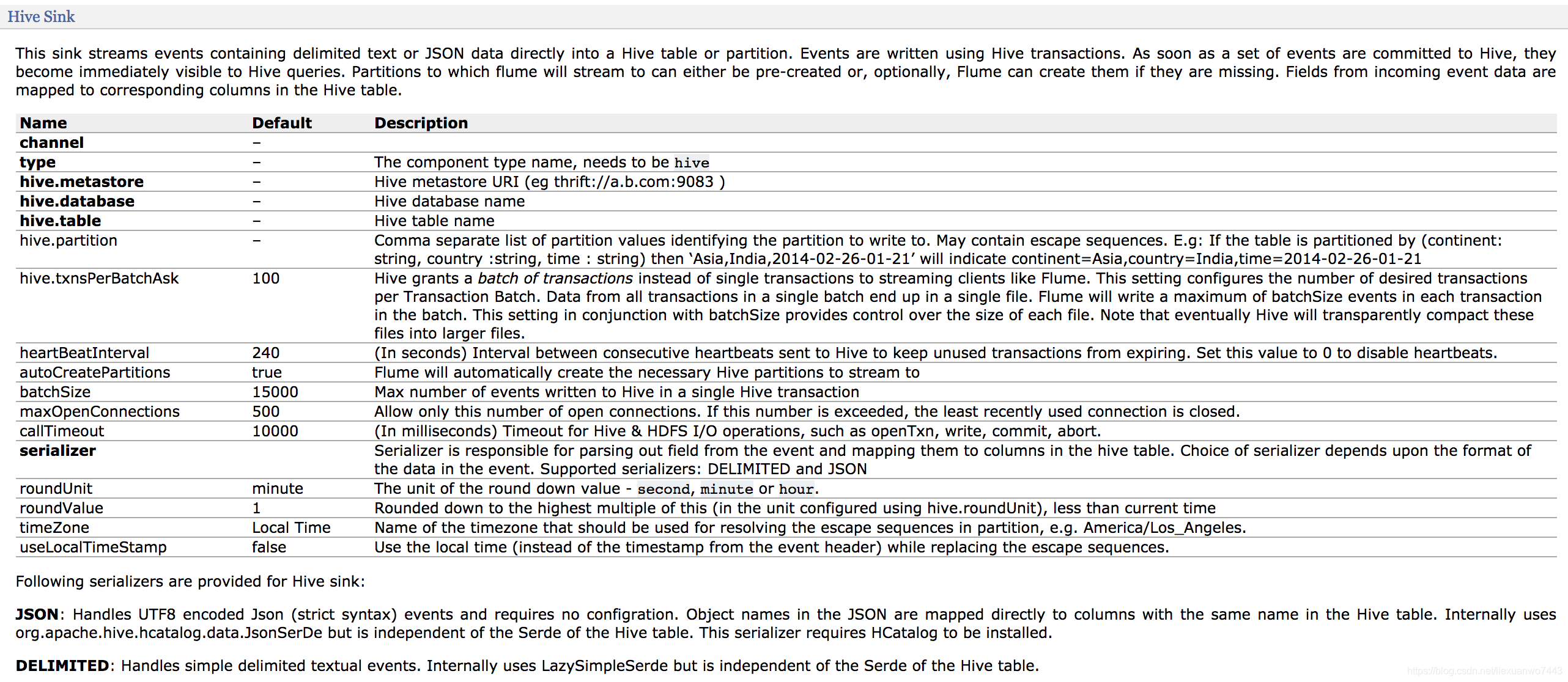
例如:
a.sinks.hive_sink.type=hive
a.sinks.hive_sink.hive.metastore=thrift://localhost:9083
a.sinks.hive_sink.hive.database=hivedatabase
a.sinks.hive_sink.hive.table=hivetable
a.sinks.hive_sink.hive.txnsPerBatchAsk=2
a.sinks.hive_sink.batchSize=10
a.sinks.hive_sink.serializer=JSON
a.sinks.hive_sink.serializer.fieldnames=id,name,age
4).完整的kafka2hive.conf文件为:
a.sources=source_from_kafka
a.channels=mem_channel
a.sinks=hive_sink
#kafka为souce的配置
a.sources.source_from_kafka.type=org.apache.flume.source.kafka.KafkaSource
a.sources.source_from_kafka.batchSize=10
a.sources.source_from_kafka.kafka.bootstrap.servers=localhost:9092
a.sources.source_from_kafka.topic=test
a.sources.source_from_kafka.channels=mem_channel
a.sources.source_from_kafka.consumer.timeout.ms=1000
#hive为sink的配置
a.sinks.hive_sink.type=hive
a.sinks.hive_sink.hive.metastore=thrift://localhost:9083
a.sinks.hive_sink.hive.database=hivedatabase
a.sinks.hive_sink.hive.table=hivetable
a.sinks.hive_sink.hive.txnsPerBatchAsk=2
a.sinks.hive_sink.batchSize=10
a.sinks.hive_sink.serializer=JSON
a.sinks.hive_sink.serializer.fieldnames=id,name,age
#channel的配置
a.channels.mem_channel.type=memory
a.channels.mem_channel.capacity=1000
a.channels.mem_channel.transactionCapacity=100
#三者之间的关系
a.sources.source_from_kafka.channels=mem_channel
a.sinks.hive_sink.channel=mem_channel
$ flume-ng agent -n a -c /opt/flume/conf -f /opt/flume/conf/kafka2hive.conf -Dflume.root.logger=INFO,console
>{"id":1,"name":"snowty","age":25}
select * from hivetable;

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
