社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
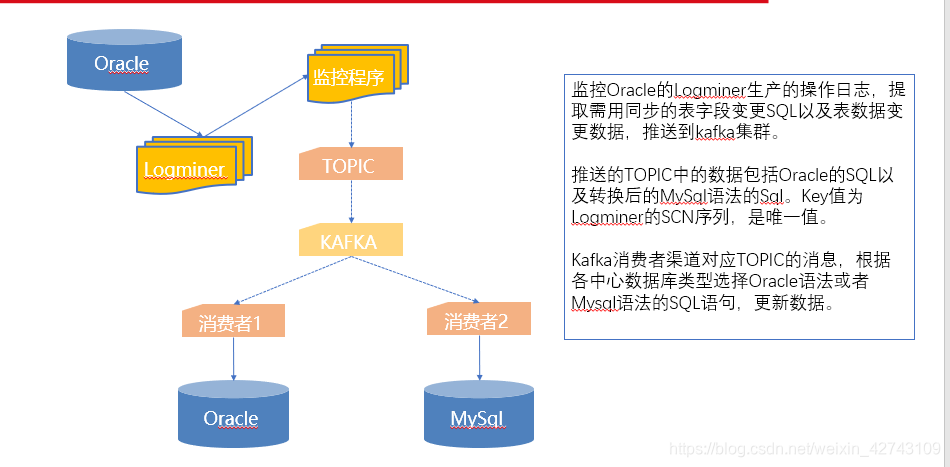
Oracle同步数据最佳的解决方案是自家的ogg,但是考虑到成本,需要找到其他的解决方案。如果是MySQL通过kafka同步,问题简单的多,因为阿里巴巴的开源数据同步方案——canel是最佳的解决方案。但是,canel只开源了MySQL数据库同步方案,Oracle同步没有开源出来。
借鉴canel的思路,canel通过实时获取MySQL的binlog日志做数据同步,Oracle有没有类似的方法呢
答案是肯定的,那就是Oracle的日志分析工具——logmner。通过实时获取logmner的重做日志,筛选出需要的信息,发送到kafka即可。
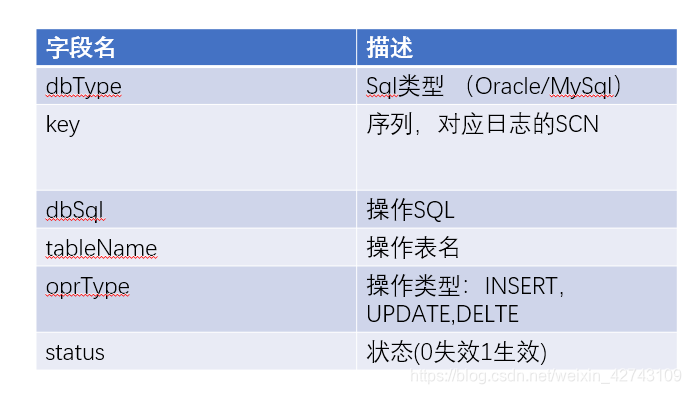
{
"sqlList": [
{
"dbType": "Oracle",
"key": "3172712",
"oprType": "UPDATE",
"tableName": "PRODUCT_CHANNEL_CFG",
"status": "1",
"dbSql": "update "PRODUCT_CHANNEL_CFG" set "STATUS" = '1', "OPR_CODE" = '2' where "PRODUCT_ID" = '21000004' and "CHANNEL_ID" = '12345678' and "STATUS" = '1' and "INURE_TIME" = TO_DATE('01-1月 -19', 'DD-MON-RR') and "EXPIRE_TIME" = TO_DATE('01-1月 -19', 'DD-MON-RR') and "OPR_CODE" = '1' and "EFFT_TYPE" = '1' and "CREATE_ID" = '1000815' and "CREATE_TIME" = TO_DATE('23-8月 -19', 'DD-MON-RR') and "MODIFY_ID" IS NULL and "MODIFY_TIME" IS NULL;"
},
{
"dbType": "MySql",
"key": "3172712",
"oprType": "UPDATE",
"tableName": "PRODUCT_CHANNEL_CFG",
"status": "1",
"dbSql": "update product_channel_cfg set status = '1', opr_code = '2' where product_id = '21000004' and channel_id = '12345678' and status = '1' and inure_time = str_to_date('20190101', '%Y%m%d%H') and expire_time = str_to_date('20190101', '%Y%m%d%H') and opr_code = '1' and efft_type = '1' and create_id = '1000815' and create_time = str_to_date('20190823', '%Y%m%d%H') and modify_id is null and modify_time is null;"
}
]
}
import java.util.List;
public class AcceptBean {
private List<InputBean> sqlList;
public List<InputBean> getSqlList() {
return sqlList;
}
public void setSqlList(List<InputBean> sqlList) {
this.sqlList = sqlList;
}
}
InputBean
public class InputBean {
private String key;
private String dbType;
private String dbSql;
public String getDbType() {
return dbType;
}
public void setDbType(String dbType) {
this.dbType = dbType;
}
public String getDbSql() {
return dbSql;
}
public void setDbSql(String dbSql) {
this.dbSql = dbSql;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
}
KafkaProducerDemo
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerDemo {
private final Producer<String,String> kafkaProducer;
public final static String TOPIC="POC_TOPIC";
public KafkaProducerDemo(){
kafkaProducer=createKafkaProducer() ;
}
private Producer<String,String> createKafkaProducer(){
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
return kafkaProducer;
}
void produce(String key,String msg){
String data= msg;
kafkaProducer.send(new ProducerRecord<String, String>(TOPIC, key, data), new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//do sth
}
});
System.out.println(data);
}
}
这里是读取日志的核心代码
LogMinerUtils
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class LogMinerUtils {
public List<InputBean> getLog(Connection sourceConn, Connection targetConn) throws Exception {
List<InputBean> rets = new ArrayList<InputBean>();
ResultSet resultSet = null;
Statement statement = sourceConn.createStatement();
// 添加所有日志文件,本代码仅分析联机日志
StringBuffer sbSQL = new StringBuffer();
sbSQL.append(" BEGIN");
sbSQL.append(" dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"/redo01.log', options=>dbms_logmnr.NEW);");
sbSQL.append(" dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"/redo02.log', options=>dbms_logmnr.ADDFILE);");
sbSQL.append(" dbms_logmnr.add_logfile(logfilename=>'"+Constants.LOG_PATH+"/redo03.log', options=>dbms_logmnr.ADDFILE);");
sbSQL.append(" END;");
System.out.println(sbSQL);
CallableStatement callableStatement = sourceConn.prepareCall(sbSQL+"");
callableStatement.execute();
// 打印获分析日志文件信息
resultSet = statement.executeQuery("SELECT db_name, thread_sqn, filename FROM v$logmnr_logs");
while(resultSet.next()){
System.out.println("已添加日志文件==>"+resultSet.getObject(3));
}
System.out.println("开始分析日志文件,起始scn号:"+Constants.LAST_SCN);
callableStatement = sourceConn.prepareCall("BEGIN dbms_logmnr.start_logmnr(startScn=>'"+Constants.LAST_SCN+"',dictfilename=>'"+Constants.DATA_DICTIONARY+"/zyhd.ora',OPTIONS =>DBMS_LOGMNR.COMMITTED_DATA_ONLY+dbms_logmnr.NO_ROWID_IN_STMT);END;");
System.out.println("BEGIN dbms_logmnr.start_logmnr(startScn=>'"+Constants.LAST_SCN+"',dictfilename=>'"+Constants.DATA_DICTIONARY+"/zyhd.ora',OPTIONS =>DBMS_LOGMNR.COMMITTED_DATA_ONLY+dbms_logmnr.NO_ROWID_IN_STMT);END;");
callableStatement.execute();
System.out.println("完成分析日志文件");
// 查询获取分析结果
System.out.println("查询分析结果");
resultSet = statement.executeQuery("SELECT scn,operation,timestamp,status,sql_redo FROM v$logmnr_contents WHERE seg_owner='"+Constants.SOURCE_CLIENT_USERNAME+"' AND seg_type_name='TABLE' AND operation !='SELECT_FOR_UPDATE' AND TABLE_NAME IN ('PRODUCT_DEF')");
System.out.println("SELECT scn,operation,timestamp,status,sql_redo FROM v$logmnr_contents WHERE seg_owner='"+Constants.SOURCE_CLIENT_USERNAME+"' AND seg_type_name='TABLE' AND operation !='SELECT_FOR_UPDATE'");
String lastScn = Constants.LAST_SCN;
boolean isCreateDictionary = false;
String operation = null;
String sql = null;
while(resultSet.next()){
lastScn = resultSet.getObject(1)+"";
if( lastScn.equals(Constants.LAST_SCN) ){
continue;
}
operation = resultSet.getObject(2)+"";
if( "DDL".equalsIgnoreCase(operation) ){
isCreateDictionary = true;
}
sql = resultSet.getObject(5)+"";
// 替换用户
sql = sql.replace("""+Constants.SOURCE_CLIENT_USERNAME+"".", "");
System.out.println("scn="+lastScn+",自动执行sql=="+sql+"");
InputBean inputBean = new InputBean();
inputBean.setKey(lastScn);
inputBean.setDbType("Oracle");
inputBean.setDbSql(sql);
rets.add(inputBean);
try {
//targetStatement.executeUpdate(sql.substring(0, sql.length()-1));
} catch (Exception e) {
System.out.println("测试一下,已经执行过了");
}
}
// 更新scn
Constants.LAST_SCN = (Integer.parseInt(lastScn))+"";
// DDL发生变化,更新数据字典
if( isCreateDictionary ){
System.out.println("DDL发生变化,更新数据字典");
createDictionary(sourceConn);
System.out.println("完成更新数据字典");
isCreateDictionary = false;
}
System.out.println("完成一个工作单元");
return rets;
}
public void createDictionary(Connection sourceConn) throws Exception{
String createDictSql = "BEGIN dbms_logmnr_d.build(dictionary_filename => 'zyhd.ora', dictionary_location =>'"+Constants.DATA_DICTIONARY+"'); END;";
System.out.println(createDictSql);
CallableStatement callableStatement = sourceConn.prepareCall(createDictSql);
callableStatement.execute();
}
}
Oracle的sql语法转mysql
Ora2Mysql
public class Ora2Mysql {
public static String convertMysql(String sql){
return "";
}
public static String transSql(String str){
str = str.toLowerCase().replaceAll(""","");
StringBuilder sb = new StringBuilder();
int i = -1;
while(str.indexOf("to_date(",i+1) >= 0) {
int j = str.indexOf("to_date(",i+1);
sb.append(str.substring(i+1,j));
sb.append(getDataString(str.substring(j+9,j+18)));
i = j+32;
}
sb.append(str.substring(i+1,str.length()));
return sb.toString();
}
private static String getDataString(String date){
String[] times = date.split("-");
StringBuilder sb = new StringBuilder();
sb.append("20");
if(times.length == 3){
sb.append(times[2].trim());
String mon = times[1].trim().replaceAll("月","");
sb.append(fixDate(mon));
sb.append(fixDate(times[0]));
}
return "str_to_date('"+sb.toString()+"', '%Y%m%d%H')";
}
private static String fixDate(String date){
if(date.length() == 1)
return "0"+date;
else
return date;
}
}
启动类
Start
public class Start {
public static void main(String[] args) throws Exception {
SyncTask syncTask = new SyncTask();
syncTask.startLogmur();
}
}
SyncTask
import net.sf.json.JSONObject;
import org.apache.commons.beanutils.BeanUtils;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
public class SyncTask {
private LogMinerUtils logMinerUtils;
private KafkaProducerDemo kafkaProducerDemo;
/**
* <p>方法名称: createDictionary|描述: 调用logminer生成数据字典文件</p>
* @throws Exception 异常信息
*/
public SyncTask(){
logMinerUtils = new LogMinerUtils();
kafkaProducerDemo = new KafkaProducerDemo();
}
public void createDictionary(Connection sourceConn) throws Exception{
String createDictSql = "BEGIN dbms_logmnr_d.build(dictionary_filename => 'zyhd.ora', dictionary_location =>'"+Constants.DATA_DICTIONARY+"'); END;";
System.out.println(createDictSql);
CallableStatement callableStatement = sourceConn.prepareCall(createDictSql);
callableStatement.execute();
}
/**
* <p>方法名称: startLogmur|描述:启动logminer分析 </p>
* @throws Exception
*/
public void startLogmur() throws Exception{
Connection sourceConn = null;
Connection targetConn = null;
try {
// 获取源数据库连接
Class.forName("oracle.jdbc.driver.OracleDriver");
sourceConn = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:orcl","logminer","123321");
while (true) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
List<InputBean> retBeans = logMinerUtils.getLog(sourceConn,targetConn);
AcceptBean acceptBean = new AcceptBean();
for(InputBean inputBean : retBeans){
acceptBean.setSqlList(new ArrayList<InputBean>());
acceptBean.getSqlList().add(inputBean);
String mySqlStr = Ora2Mysql.transSql(inputBean.getDbSql());
InputBean inputBean2 = new InputBean();
BeanUtils.copyProperties(inputBean2,inputBean);
inputBean2.setDbType("MySql");
inputBean2.setDbSql(mySqlStr);
acceptBean.getSqlList().add(inputBean2);
kafkaProducerDemo.produce(inputBean.getKey(),JSONObject.fromObject(acceptBean).toString());
}
}
}
finally{
if( null != sourceConn ){
sourceConn.close();
}
if( null != targetConn ){
targetConn.close();
}
sourceConn = null;
targetConn = null;
}
}
}
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
