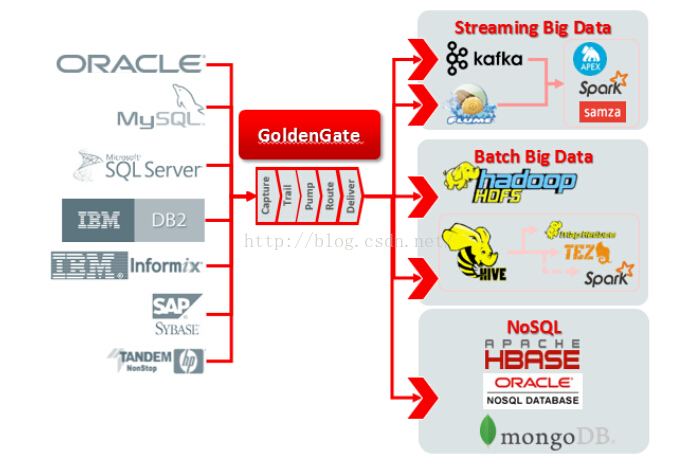
安装kafka
安装zookeeper
配置环境变量,/etc/profile添加以下内容:
[
root@T2 kafkaogg]# export ZOOKEEPER_HOME=/opt/app/kafka/zookeeper-3.4.6
[
root@T2 kafkaogg]# export PATH=$PATH:$ZOOKEEPER_HOME/bin
修改配置文件
[
root@T2 kafkaogg]# cd zookeeper-3.4.6/conf/
configuration.xsl log4j.properties zoo_sample.cfg
[
root@T2 conf]# cat zoo_sample.cfg | grep -v '#' > zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper
clientPort=2181
接着启动zookeeper服务
[
root@T2 conf]# ../bin/zkServer.sh start
JMX enabled by default
Using config: /opt/app/kafkaogg/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看是否启动
[
root@T2 conf]# ../bin/zkServer.sh status
JMX enabled by default
Using config: /opt/app/kafkaogg/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: standalone
Server启动之后, 就可以启动client连接server了, 执行脚本:
[
root@T2 bin]#./zkCli.sh -server localhost:2181
安装kafka
安装kafka server之前需要单独安装zookeeper server,而且需要修改config/server.properties里面的IP信息
/opt/app/kafkaogg/kafka_2.11-0.9.0.0/config
[root@T2 config]# vi server.properties
zookeeper.connect=localhost:2181
这里需要修改默认zookeeper.properties配置
[
root@T2 config]# vi zookeeper.properties
dataDir=/tmp/zkdata
先启动zookeeper,启动前先kill掉之前的zkServer.sh启动的zookeeper服务
[root@T2 bin]# ./zookeeper-server-start.sh ../config/zookeeper.properties
启动kafka服务
[root@T2 bin]# ./kafka-server-start.sh ../config/server.properties
查看kafka进程是否启动:
16882 QuorumPeerMain
17094 Kafka
17287 Jps
创建topic
[
root@T2 bin]#./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
查看topic列表
[
root@T2 bin]#./kafka-topics.sh --list --zookeeper localhost:2181
test
创建broker集群
[
root@T2 config]#cp server.properties ./server-1.properties
[
root@T2 config]#cp server.properties ./server-2.properties
更改以下内容
[
root@T2 config]#vi server-1.properties
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
[
root@T2 config]#vi server-2.properties
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
其中broker.id是每一个broker的唯一标识号
启动另外两个Broker进程:
[
root@T2 config]#../bin/kafka-server-start.sh ./server-1.properties &
[
root@T2 config]#../bin/kafka-server-start.sh ./server-2.properties &
在同一台机器上创建三个broker的topic:
[
root@T2 bin]#./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic fafacluster
Created topic "fafacluster".
查看三个broker中,leader和replica角色:
[
root@T2 bin]#./kafka-topics.sh --describe --zookeeper localhost:2181 --topic fafacluster
Topic:fafacluster PartitionCount:1 ReplicationFactor:3 Configs:
Topic: fafacluster Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
对于三个broker的伪cluster,可以尝试杀掉其中一个或两个broker进程,然后看看leader,replica,isr会不会发生变化,消费者还能不能正常消费消息。
生产者推送消息:
[
root@T2 bin]#./kafka-console-producer.sh --broker-list localhost:9092 --topic fafacluster
fafa
fafa01
杀掉一个broker进程
[
root@T2 bin]#./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic fafacluster
..................................
..................................
java.nio.channels.ClosedChannelException
at kafka.network.BlockingChannel.send(BlockingChannel.scala:110)
at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:98)
at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:83)
at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:149)
at kafka.consumer.SimpleConsumer.earliestOrLatestOffset(SimpleConsumer.scala:188)
at kafka.consumer.ConsumerFetcherThread.handleOffsetOutOfRange(ConsumerFetcherThread.scala:84)
at kafka.server.AbstractFetcherThread$$anonfun$addPartitions$2.apply(AbstractFetcherThread.scala:187)
at kafka.server.AbstractFetcherThread$$anonfun$addPartitions$2.apply(AbstractFetcherThread.scala:182)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:778)
at scala.collection.immutable.Map$Map1.foreach(Map.scala:116)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:777)
at kafka.server.AbstractFetcherThread.addPartitions(AbstractFetcherThread.scala:182)
at kafka.server.AbstractFetcherManager$$anonfun$addFetcherForPartitions$2.apply(AbstractFetcherManager.scala:88)
at kafka.server.AbstractFetcherManager$$anonfun$addFetcherForPartitions$2.apply(AbstractFetcherManager.scala:78)
at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:778)
at scala.collection.immutable.Map$Map1.foreach(Map.scala:116)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:777)
at kafka.server.AbstractFetcherManager.addFetcherForPartitions(AbstractFetcherManager.scala:78)
at kafka.consumer.ConsumerFetcherManager$LeaderFinderThread.doWork(ConsumerFetcherManager.scala:95)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:63)
fafa
fafa01
可以看到一大堆报错之后,还是完整的消费到生产的消息
使用kafka连接工具导入导出信息
[root@T2 kafka_2.11-0.9.0.0]# cat test.txt
foo
bar
dadadada
fgdgeg
sfewfwef
sfd
[root@T2 kafka_2.11-0.9.0.0]# cat config/connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
[root@T2 kafka_2.11-0.9.0.0]# cat config/connect-file-source.properties
name=local-file-source
connector.class=org.apache.kafka.connect.file.FileStreamSourceConnector
tasks.max=1
file=test.txt
topic=fafacluster
[root@T2 kafka_2.11-0.9.0.0]# cat config/connect-file-sink.properties
name=local-file-sink
connector.class=org.apache.kafka.connect.file.FileStreamSinkConnector
tasks.max=1
file=test.sink.txt
topics=fafacluster
[root@T2 kafka_2.11-0.9.0.0]# bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
此时在接受端收到消息
[root@T2 bin]# ./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic fafacluster
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"dadadada"}
{"schema":{"type":"string","optional":false},"payload":"fgdgeg"}
{"schema":{"type":"string","optional":false},"payload":"sfewfwef"}
{"schema":{"type":"string","optional":false},"payload":"sfd"}
原理解析:
1,kafka连接进程启动以后,源端连接开始读test.txt数据
2,把消息推送给topic fafacluster
3,sink connector连接开始读topic为fafacluster的消息,并把它写入文件名为test.sink.txt的文件
继续插入文件
[root@T2 kafka_2.11-0.9.0.0]# echo "Another line" >> test.txt
接收端查看发现,新增加的信息到达接收端
{"schema":{"type":"string","optional":false},"payload":"Another line"}
测试结束,现在我们创建一个同步数据topic,这里先确保zookeeper和kafka进程在运行
[
root@T2 bin]#./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic fafatable
[
root@T2 bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic fafatable
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/app/Kafka/kafka_2.11-0.9.0.0/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/app/kafkaogg/kafka_2.11-0.9.0.0/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Created topic "fafatable".
注意这里是kafka扫描到其他路径有SLF4J而报错
这样既可解决
现在正式开始ogg oracle到kafka的同步
一.源端Oracle数据库安装ogg client
(过程略)不过需要在源端生产DEF文件
二.目标端Kafka 安装ogg for bigdata client
只有ogg for bigdata 12.2版本才开始支持kafka。
ogg for bigdata client所需的jar包在libs文件夹下都有的
[
root@T2 kafka_2.11-0.9.0.0]# cd libs/
aopalliance-repackaged-2.4.0-b31.jar javax.annotation-api-1.2.jar jetty-servlet-9.2.12.v20150709.jar log4j-1.2.17.jar
argparse4j-0.5.0.jar javax.inject-1.jar jetty-util-9.2.12.v20150709.jar lz4-1.2.0.jar
connect-api-0.9.0.0.jar javax.inject-2.4.0-b31.jar jopt-simple-3.2.jar metrics-core-2.2.0.jar
connect-file-0.9.0.0.jar javax.servlet-api-3.1.0.jar kafka_2.11-0.9.0.0.jar osgi-resource-locator-1.0.1.jar
connect-json-0.9.0.0.jar javax.ws.rs-api-2.0.1.jar kafka_2.11-0.9.0.0.jar.asc scala-library-2.11.7.jar
connect-runtime-0.9.0.0.jar jersey-client-2.22.1.jar kafka_2.11-0.9.0.0-javadoc.jar scala-parser-combinators_2.11-1.0.4.jar
hk2-api-2.4.0-b31.jar jersey-common-2.22.1.jar kafka_2.11-0.9.0.0-javadoc.jar.asc scala-xml_2.11-1.0.4.jar
hk2-locator-2.4.0-b31.jar jersey-container-servlet-2.22.1.jar kafka_2.11-0.9.0.0-scaladoc.jar slf4j-api-1.7.6.jar
hk2-utils-2.4.0-b31.jar jersey-container-servlet-core-2.22.1.jar kafka_2.11-0.9.0.0-scaladoc.jar.asc slf4j-log4j12-1.7.6.jar
jackson-annotations-2.5.0.jar jersey-guava-2.22.1.jar kafka_2.11-0.9.0.0-sources.jar snappy-java-1.1.1.7.jar
jackson-core-2.5.4.jar jersey-media-jaxb-2.22.1.jar kafka_2.11-0.9.0.0-sources.jar.asc validation-api-1.1.0.Final.jar
jackson-databind-2.5.4.jar jersey-server-2.22.1.jar kafka_2.11-0.9.0.0-test.jar zkclient-0.7.jar
jackson-jaxrs-base-2.5.4.jar jetty-http-9.2.12.v20150709.jar kafka_2.11-0.9.0.0-test.jar.asc zookeeper-3.4.6.jar
jackson-jaxrs-json-provider-2.5.4.jar jetty-io-9.2.12.v20150709.jar kafka-clients-0.9.0.0.jar
jackson-module-jaxb-annotations-2.5.4.jar jetty-security-9.2.12.v20150709.jar kafka-log4j-appender-0.9.0.0.jar
javassist-3.18.1-GA.jar jetty-server-9.2.12.v20150709.jar kafka-tools-0.9.0.0.jar
前期配置工作
在目标端kafka的ogg配置,这里安装OGG_v12.2.0.1_bigdata_Linux_x64.zip
AdapterExamples dircrd dirtmp ggMessage.dat lib libggperf.so libxml2.txt prvtclkm.plb usrdecs.h
bcpfmt.tpl dirdat dirwlt ggparam.dat libantlr3c.so libggrepo.so licenses replicat zlib.txt
bcrypt.txt dirdef dirwww ggs_Adapters_Linux_x64.tar libdb-6.1.so libicudata.so.48 logdump retrace
cachefiledump dirdmp emsclnt ggsci libggjava.so libicudata.so.48.1 mgr reverse
checkprm dirout extract ggserr.log libggjava_ue.so libicui18n.so.48 notices.txt server
convchk dirpcs freeBSD.txt help.txt libggjava_vam.so libicui18n.so.48.1 OGG_BigData_12.2.0.1.0_Release_Notes.pdf sqlldr.tpl
convprm dirprm gendef kafka_2.11-0.9.0.0 libgglog.so libicuuc.so.48 OGG_BigData_12.2.0.1_README.txt tcperrs
db2cntl.tpl dirrpt ggcmd kafka_2.11-0.9.0.0.tgz libggnnzitp.so libicuuc.so.48.1 oggerr ucharset.h
dirchk dirsql ggjava keygen libggparam.so libxerces-c.so.28 OGG_v12.2.0.1_bigdata_Linux_x64.zip UserExitExamples
这里使用的是oracle用户
cd $OGG_HOME(在.bash_profile中添加$OGG_HOME环境变量)即/opt/app/kafkaogg
Oracle GoldenGate Command Interpreter
Version 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2
Linux, x64, 64bit (optimized), Generic on Nov 10 2015 16:18:12
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.
GGSCI (T2) 1> CREATE SUBDIRS
Creating subdirectories under current directory /opt/app/kafkaogg
Parameter files /opt/app/kafkaogg/dirprm: created
Report files /opt/app/kafkaogg/dirrpt: created
Checkpoint files /opt/app/kafkaogg/dirchk: created
Process status files /opt/app/kafkaogg/dirpcs: created
SQL script files /opt/app/kafkaogg/dirsql: created
Database definitions files /opt/app/kafkaogg/dirdef: created
Extract data files /opt/app/kafkaogg/dirdat: created
Temporary files /opt/app/kafkaogg/dirtmp: created
Credential store files /opt/app/kafkaogg/dircrd: created
Masterkey wallet files /opt/app/kafkaogg/dirwlt: created
Dump files /opt/app/kafkaogg/dirdmp: created
GGSCI (T2) 7> edit params mgr
GGSCI (T2) 9> start mgr
Manager started.
拷贝kafka adapter 配置文件:
/opt/app/kafkaogg/AdapterExamples/big-data/kafka
[
root@T2 kafka]# cp * /opt/app/kafkaogg/dirprm/
[
root@T2 kafka]# vi /opt/app/kafkaogg/dirprm/custom_kafka_producer.properties
#bootstrap.servers=host:port
bootstrap.servers=172.16.57.55:9092
acks=1
#compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
# 100KB per partition
batch.size=102400
linger.ms=10000
解释:
这里测试发现compression.type=gzip,replicate识别不了报错。尚不清楚原因
bootstrap是HOSTNAME
[
root@T2 kafka]# vi /opt/app/kafkaogg/dirprm/kafka.props
gg.handlerlist = kafkahandler
gg.handler.kafkahandler.type = kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
gg.handler.kafkahandler.TopicName =fafatable
gg.handler.kafkahandler.format =avro_op
gg.handler.kafkahandler.SchemaTopicName=fafaschema
gg.handler.kafkahandler.BlockingSend =true
gg.handler.kafkahandler.includeTokens=false
#gg.handler.kafkahandler.topicPartitioning=table
gg.handler.kafkahandler.mode =op
#gg.handler.kafkahandler.maxGroupSize =100, 1Mb
#gg.handler.kafkahandler.minGroupSize =50, 500Kb
goldengate.userexit.timestamp=utc
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
gg.classpath=dirprm/:/opt/app/kafkaogg/kafka_2.11-0.9.0.0/libs/*:
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
解释:
gg.handler.kafkahandler.TopicName 对应kafka的topic,跟源端数据库的table相对应,但可以不同名,用map可以匹配。
gg.handler.kafkahandler.SchemaTopicName 当format为avro时,需要配置此参数,否则可以不配。
gg.handler.kafkahandler.BlockingSend 当值为true时,表示同步更新,下一个消息发送需要等到写入到目标topic中,且确认已经收到才发下一条消息。为false为异步更新,将一次性发给目标topic。
gg.handler.kafkahandler.topicPartitioning有两种参数值none | table,控制是否已发布到kafka的数据应按表分区。设置为表,不同表的数据被写入到不同的kafka主题。设置为None,来自不同表的数据交织在同一话题。
gg.handler.kafkahandler.mode 当值为tx时,表示源端一次事务内的操作在kafka上作为一个record。
查看当前Java版本
java version "1.8.0_77"
Java(TM) SE Runtime Environment (build 1.8.0_77-b03)
Java HotSpot(TM) 64-Bit Server VM (build 25.77-b03, mixed mode)
注意:需要是jdk-1.7版本,不然启动时会报如下超时错误,ogg不支持jdk-1.8版本
删除1.8版本 yum remove java-1.8.0*
root@n3:/opt/app/kafkaogg# yum install java-1.7.0*
java version "1.7.0_79"
OpenJDK Runtime Environment (rhel-2.5.5.4.el6-x86_64 u79-b14)
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
root@n3:/opt/app/kafkaogg# ls /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/
bin lib
[root@T2 dirprm]# vi ~/.bash_profile
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.101.x86_64/jre/lib/amd64/libjsig.so:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.101.x86_64/jre/lib/amd64/server/libjvm.so:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.101.x86_64/jre/lib/amd64/server:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.101.x86_64/jre/lib/amd64
生效
[
root@T2 dirprm]# source ~/.bash_profile
root@n3:/opt/app/kafkaogg# export LD_LIBRARY_PATH=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/lib/amd64/libjsig.so:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/lib/amd64/server/libjvm.so:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/lib/amd64/server:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre/lib/amd64/
源端oracle上搭建ogg,这里安装fbo_ggs_Linux_x64_shiphome.zip
1、开启主库归档日志、补充日志及force logging
SQL> alter database archivelog;
alter database archivelog
*
ERROR at line 1:
ORA-01126: database must be mounted in this instance and not open in any
instance
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /opt/app/oracle/oraarch
Oldest online log sequence 91
Next log sequence to archive 93
Current log sequence 93
SQL> alter database add supplemental log data;
Database altered.
SQL> alter database force logging;
Database altered.
SQL> alter system set enable_goldengate_replication=true scope=both;
System altered.
2、关闭回收站
SQL> alter system set recyclebin=off scope=spfile;
System altered.
3、创建OGG管理用户(主备库都要设置)
create user ogg identified by ogg account unlock;
grant connect,resource to ogg;
grant select any dictionary to ogg;
grant select any table to ogg;
grant execute on utl_file to ogg;
grant restricted session to ogg;
GRANT CREATE TABLE,CREATE SEQUENCE TO OGG; (必须有的操作,后续会介绍)
grant dba to ogg;(可选)
数据初始化(Oracle initial load)
此时我们需要把dataprod用户下所有表导入到kafka中
查看
SQL> SELECT table_name FROM all_tables WHERE owner = upper('dataprod');
TABLE_NAME
------------------------------------------------------------
CRM_AGG_USERBEHAVIOR_CALC1
DP_TRADE_PVCOUNT
CRM_AGG_USERBEHAVIOR_CALC1_BK
DP_AGG_USERBEHAVIORSCORE
CRM_AGG_USERPUSH_CALC1
CRM_AGG
6 rows selected.
SQL> select owner,trigger_name from all_triggers where owner in ('DATAPROD');
OWNER
------------------------------------------------------------
TRIGGER_NAME
------------------------------------------------------------
DATAPROD
EID_ID
了解完dataprod用户表以后,我们开始初始化
安装源端ogg软件
total 464752
drwxr-xr-x 3 oracle oinstall 4096 Dec 12 2015 fbo_ggs_Linux_x64_shiphome
-rw-r--r-- 1 oracle oinstall 475611228 Jul 13 17:54 fbo_ggs_Linux_x64_shiphome.zip
-rw-r--r-- 1 oracle oinstall 282294 Jan 19 07:13 OGG-12.2.0.1.1-ReleaseNotes.pdf
-rw-r--r-- 1 oracle oinstall 1559 Jan 19 07:12 OGG-12.2.0.1-README.txt
install response runInstaller stage
这里采用静默安装
oracle.install.responseFileVersion=/oracle/install/rspfmt_ogginstall_response_schema_v12_1_2
DATABASE_LOCATION=/opt/app/oracle/product/11g
INVENTORY_LOCATION=/opt/app/oraInventory
解释:
DATABASE_LOCATION是指ORACLE_HOME路径
oracle@bd-qa-oracle-86:/opt/app/kafkaogg/fbo_ggs_Linux_x64_shiphome/Disk1$./runInstaller -silent -responseFile /opt/app/kafkaogg/fbo_ggs_Linux_x64_shiphome/Disk1/response/oggcore.rsp Starting Oracle Universal Installer...
Checking Temp space: must be greater than 120 MB. Actual 6427 MB Passed
Checking swap space: must be greater than 150 MB. Actual 7793 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2016-07-14_09-54-11AM. Please wait
...oracle@bd-qa-oracle-86:/opt/app/kafkaogg/fbo_ggs_Linux_x64_shiphome/Disk1$[WARNING] [INS-75003] The specified directory /opt/app/kafkaogg is not empty.
CAUSE: The directory specified /opt/app/kafkaogg contains files.
ACTION: Clean up the specified directory or enter a new directory location.
You can find the log of this install session at:
/opt/app/oraInventory/logs/installActions2016-07-14_09-54-11AM.log
WARNING:OUI-10030:You have specified a non-empty directory to install this product. It is recommended to specify either an empty or a non-existent directory. You may, however, choose to ignore this message if the directory contains Operating System generated files or subdirectories like lost+found.
Do you want to proceed with installation in this Oracle Home?
The installation of Oracle GoldenGate Core was successful.
Please check '/opt/app/oraInventory/logs/silentInstall2016-07-14_09-54-11AM.log' for more details.
Successfully Setup Software.
ogg软件安装成功
Oracle GoldenGate Command Interpreter for Oracle
Version 12.2.0.1.1 OGGCORE_12.2.0.1.0_PLATFORMS_151211.1401_FBO
Linux, x64, 64bit (optimized), Oracle 11g on Dec 12 2015 00:54:38
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.
GGSCI (bd-qa-oracle-86) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
源端配置mgr进程
GGSCI (bd-qa-oracle-86) 10> edit params mgr
PORT 1357
dynamicportlist 9901-9920,9930
autostart er *
autorestart er *,retries 4,waitminutes 4
startupvalidationdelay 5
purgeoldextracts /opt/app/kafkaogg/dirdat/ff,usecheckpoints,minkeephours 2
配置数据同步用户
GGSCI (bd-qa-oracle-86) 7> dblogin userid ogg,password ogg
Successfully logged into database.
GGSCI (bd-qa-oracle-86 as
ogg@BDDEV) 8> add trandata dataprod.*
2016-07-14 10:43:59 WARNING OGG-06439 No unique key is defined for table CRM_AGG. All viable columns will be used to represent the key, but may not guarantee uniqueness. KEYCOLS may be used to define the key.
Logging of supplemental redo data enabled for table DATAPROD.CRM_AGG.
TRANDATA for scheduling columns has been added on table 'DATAPROD.CRM_AGG'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.CRM_AGG'.
Logging of supplemental redo data enabled for table DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1.
TRANDATA for scheduling columns has been added on table 'DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1'.
Logging of supplemental redo data enabled for table DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1_BK.
TRANDATA for scheduling columns has been added on table 'DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1_BK'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.CRM_AGG_USERBEHAVIOR_CALC1_BK'.
Logging of supplemental redo data enabled for table DATAPROD.CRM_AGG_USERPUSH_CALC1.
TRANDATA for scheduling columns has been added on table 'DATAPROD.CRM_AGG_USERPUSH_CALC1'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.CRM_AGG_USERPUSH_CALC1'.
Logging of supplemental redo data enabled for table DATAPROD.DP_AGG_USERBEHAVIORSCORE.
TRANDATA for scheduling columns has been added on table 'DATAPROD.DP_AGG_USERBEHAVIORSCORE'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.DP_AGG_USERBEHAVIORSCORE'.
2016-07-14 10:44:00 WARNING OGG-06439 No unique key is defined for table DP_TRADE_PVCOUNT. All viable columns will be used to represent the key, but may not guarantee uniqueness. KEYCOLS may be used to define the key.
Logging of supplemental redo data enabled for table DATAPROD.DP_TRADE_PVCOUNT.
TRANDATA for scheduling columns has been added on table 'DATAPROD.DP_TRADE_PVCOUNT'.
TRANDATA for instantiation CSN has been added on table 'DATAPROD.DP_TRADE_PVCOUNT'.
源端初始化配置
A:配置extract进程,注意这里使用direct file模式,而不是load模式
GGSCI (bd-qa-oracle-86) 2> add extract fafainie, sourceistable
EXTRACT added.
GGSCI (bd-qa-oracle-86) 3> info extract *,tasks
EXTRACT FAFAINIE Initialized 2016-07-14 11:03 Status STOPPED
Checkpoint Lag Not Available
Log Read Checkpoint Not Available
First Record Record 0
Task SOURCEISTABLE
GGSCI (bd-qa-oracle-86) 8> edit params fafainie
extract fafainie
userid ogg,password ogg
rmthost 172.16.57.55,mgrport 1357
--rmttask replicat,group fafainir
RMTFILE ./dirdat/ff
table dataprod.*;
目标端初始化配置
配置mgr
GGSCI (T2) 2> edit params mgr
port 1357
ACCESSRULE, PROG REPLICAT, IPADDR 172.16.57.*, ALLOW
dynamicportlist 9901-9920,9930
autostart er *
autorestart er *,retries 4,waitminutes 4
startupvalidationdelay 5
purgeoldextracts /opt/app/kafkaogg/dirdat/*,usecheckpoints,minkeephours 2
LAGREPORTHOURS 1
LAGINFOMINUTES 30
LAGCRITICALMINUTES 45
A:配置replicat进程
GGSCI (T2) 5> add replicat fafainir, specialrun
REPLICAT added.
GGSCI (T2) 11> info replicat *, TASKS
REPLICAT FAFAINIR Initialized 2016-07-14 11:05 Status STOPPED
Checkpoint Lag 00:00:00 (updated 00:00:07 ago)
Log Read Checkpoint Not Available
Task SPECIALRUN
B:编辑replicat进程参数
注意这里修改这个文件
SPECIALRUN
end runtime
-- REPLICAT fafainir
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/ff
setenv (NLS_LANG=AMERICAN_AMERICA.ZHS16GBK)
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
EXTFILE ./dirdat/ff
DDL INCLUDE ALL
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP dataprod.*, TARGET fafaschema.*;
[
root@T2 dirprm]# mv rkafka.prm fafainir.prm
这里target 可以随便取名,但是这里可源库的gg.handler.kafkahandler.SchemaTopicName一致,只是做一个标识。kafka发出的消息所有消费者都可以消费了。
启动初始化进程
源端:
GGSCI (bd-qa-oracle-86) 5> start fafainie
Sending START request to MANAGER ...
EXTRACT FAFAINI starting
GGSCI (bd-qa-oracle-86) 6> view report fafainie
目标端:
[
root@T2 kafkaogg]# replicat paramfile ./dirprm/fafainir.prm reportfile ./dirrpt/fafainir.rpt -p INITIALDATALOAD
[
root@T2 kafkaogg]# tail -100f ggserr.log
验证传输情况,查看kafka消费情况
JFAFASCHEMA.CRM_AGG_USERBEHAVIOR_CALC1I42016-07-14 07:24:09.02265842016-07-15T18:03:05.741000(00000000000000003583
USERID:2016-05-03:00:00:00.00000000020250006userA001탰?탰?퀄SHSHSHSH:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.0000000000000:2016-05-03:00:00:00.000000000000
JFAFASCHEMA.CRM_AGG_USERBEHAVIOR_CALC1I42016-07-14 07:24:09.02265842016-07-15T18:03:25.776000(00000000000000004064
USERID:2016-05-03:00:00:00.00000000020250006userA002탰?탰?퀄SHSHSHSH:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.000000000:2016-05-03:00:00:00.0000000000000:2016-05-03:00:00:00.000000000000
JFAFASCHEMA.CRM_AGG_USERBEHAVIOR_CALC1I42016-07-14 07:24:09.02265842016-07-15T18:03:35.783000(00000000000000004545
数据成功传输
数据同步
1、配置DDL同步
A:目标库 配置globals参数
GGSCI (T2) 3> view param ./globals
ggschema ogg
B:源库 执行DDL配置脚本
sqlplus / as sysdba
SQL> @/opt/app/kafkaogg/marker_setup.sql
Marker setup script
You will be prompted for the name of a schema for the Oracle GoldenGate database objects.
NOTE: The schema must be created prior to running this script.
NOTE: Stop all DDL replication before starting this installation.
Enter Oracle GoldenGate schema name:ogg
Marker setup table script complete, running verification script...
Please enter the name of a schema for the GoldenGate database objects:
Setting schema name to OGG
MARKER TABLE
--------------------------------------------------------------
OK
MARKER SEQUENCE
--------------------------------------------------------------
OK
Script complete.
输入OGG管理用户名:ogg
首先建立ogg独有的表空间
SQL> CREATE TABLESPACE TBS_OGG DATAFILE '/opt/app/oracle/oradata/orcl11g/tbs_ogg_01.dbf' SIZE 2G AUTOEXTEND ON NEXT 50M MAXSIZE UNLIMITED;
Tablespace created.
SQL> alter user ogg DEFAULT TABLESPACE TBS_OGG;
User altered.
SQL> grant connect,resource,unlimited tablespace to ogg;
Grant succeeded.
SQL> @/opt/app/kafkaogg/ddl_setup.sql
Oracle GoldenGate DDL Replication setup script
Verifying that current user has privileges to install DDL Replication...
You will be prompted for the name of a schema for the Oracle GoldenGate database objects.
NOTE: For an Oracle 10g source, the system recycle bin must be disabled. For Oracle 11g and later, it can be enabled.
NOTE: The schema must be created prior to running this script.
NOTE: Stop all DDL replication before starting this installation.
Enter Oracle GoldenGate schema name:ogg
Working, please wait ...
Spooling to file ddl_setup_spool.txt
Checking for sessions that are holding locks on Oracle Golden Gate metadata tables ...
Check complete.
Using OGG as a Oracle GoldenGate schema name.
Working, please wait ...
DDL replication setup script complete, running verification script...
Please enter the name of a schema for the GoldenGate database objects:
Setting schema name to OGG
CLEAR_TRACE STATUS:
Line/pos
--------------------------------------------------------------------------------
Error
-----------------------------------------------------------------
No errors
No errors
....................
....................
输入OGG管理用户名:ogg
注意1:此处可能会报错:ORA-04098: trigger 'SYS.GGS_DDL_TRIGGER_BEFORE' is invalid and failed,同时OGG中的很多表和视图无法创建,原因主要由于OGG缺少权限引起,即便有
DBA权限也是不足的(OGG BUG),可以通过如下方法修复:
1)先将触发器关闭,否则执行任何sql都会包ORA-04098的错误
@/opt/app/OGG/ddl_disable.sql
2)赋予ogg对应权限
grant execute on utl_file to ogg;
grant restricted session to ogg;
GRANT CREATE TABLE,CREATE SEQUENCE TO OGG;
3)重新执行ddl_setup.sql
注意2:当主库上有很多应用连接时,执行该sql会出现如下报警:
IMPORTANT: Oracle sessions that used or may use DDL must be disconnected. If you
continue, some of these sessions may cause DDL to fail with ORA-6508.
To proceed, enter yes. To stop installation, enter no.
Enter yes or no:
为了不影响主库,选no,选择一个时间点,停止应用再创建ddl。
如果不创建ddl,需要在主备库的ogg进程参数中添加truncate选项:
gettruncates,参考后面同步进程配置。
SQL> @/opt/app/kafkaogg/role_setup.sql
GGS Role setup script
This script will drop and recreate the role GGS_GGSUSER_ROLE
To use a different role name, quit this script and then edit the params.sql script to change the gg_role parameter to the preferred name. (Do not run the script.)
You will be prompted for the name of a schema for the GoldenGate database objects.
NOTE: The schema must be created prior to running this script.
NOTE: Stop all DDL replication before
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u010522235/article/details/51920509
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
-
发表于 2020-06-06 09:38:22
- 阅读 ( 1331 )
- 分类: