社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
缓存穿透:当发送请求时通过key去缓存查询,如果不存在对应的value,就应该去数据库查找。一些恶意的请求会故意查询不存在的key,而且需求量很大。如果发送一万个不存在key的请求,就会对后端系统造成很大的压力,数据库有可能会挂掉,这叫做缓存穿透。
解决方法:
A:缓存空对象:当发送了请求,通过不存在的key去查找值时,我们可以在缓存中去添加这个key,并且给这份key赋值为null,只要他去查找这个key时,直接给他返回一个null即可,当他第一次查询时,判断缓存没有就会去数据库查找,缓存就会台添加这个key,并且复制为null,第二次查询时就会查询缓存,不会再查询数据库,就可以避免这个问题,如果之后确实添加了这个key的值,也会将之前的值覆盖 。缺点就是这样做的话,如果发送了很多不存在的key,会给redis造成大量的空间浪费,也是治标不治本。
B:布隆过滤器:
布隆过滤器会隔一段时间扫描一次缓存和数据库,会将缓存和数据库共有的数据添加到布隆过滤器,当由请求过来时,会先进入布隆过滤器中进行查找,有的话返回数据,没有的话会到数据中查找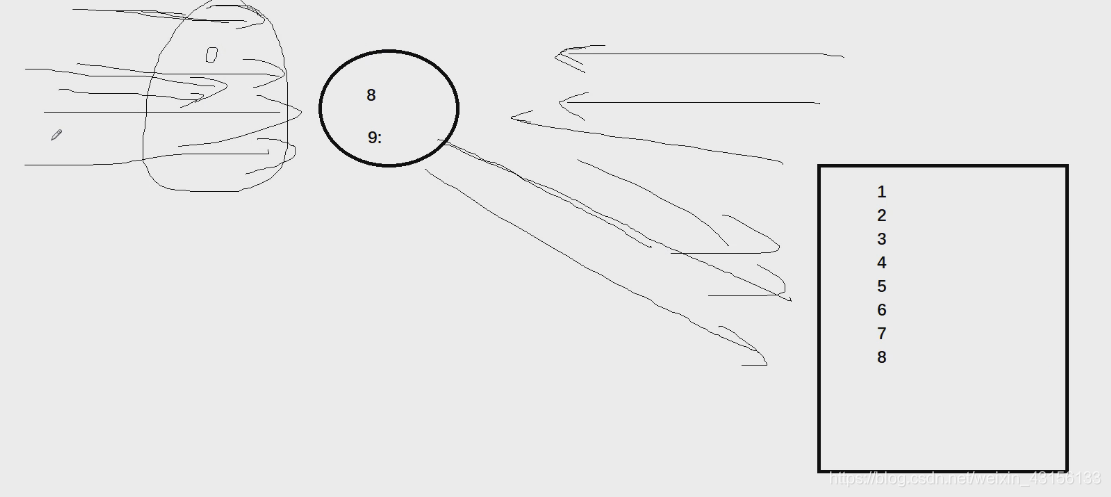
那个左边的椭圆理解成布隆过滤器,圆圈理解成redis(缓存),长方形是数据库。
但是使用布隆过滤器会出现误判的现象,为什么的呢,这里就需要介绍下布隆过滤器了。
布隆过滤器可以理解成数组,将信息添加到数组中,有两个参数,一个是size:意思是插入多少数据,一个是fpp:代表容错率。
左边是我们已经添加的数据,右边是查找数据,明显右边这个数据并没有添加,但却有可能存在,因为这个数据算出来的hash值和别的数据算出来的hash值相同,所以有可能存在。
怎样尽量避免呢,那就是降低容错率,因为容错率对位数组的大小还有hash函数的个数有关,容错率越低,位数组越大,hash函数个数越多,这样就会减少错误个数。
如果数据库的数据删除了,这时所删除的数据在布隆过滤器中还存在,这个是没办法避免的,如果数据库删除过多的数据则需要重建编写布隆过滤器。
如果误判了怎么办呢,如果布隆过滤器中由1000个数据,它拦截了900多个数据,即使误判了,也只有一两个不存在的数据去数据库查找,并不会对数据库造成多大的影响。
布隆多滤器优点:底层是bit数组,占用内存少。
缓存击穿:意思是缓存当中没有,而数据库有的数据,如果有98次请求的话,就会查询98次数据库,出现的了是并发问题。
原因:缓存中没有这个数据或者是这个数据刚刚达到过期时间失效了。
解决方法:添加分布式锁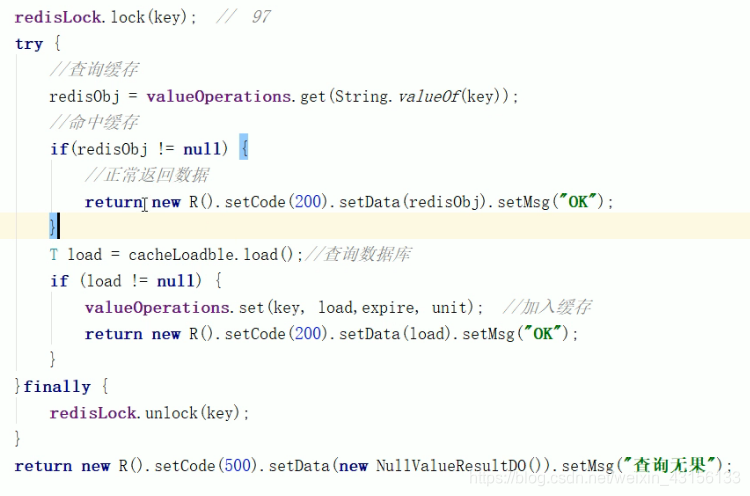
从这个代码中可以看出:如果我们有98次请求去查找这个key,当我们redisLock.lock(key),开启分布式锁时,98次请求就会只进去一次请求,只有一个线程执行,查询缓存,如果缓存没有的话去数据库查找,然后给缓存添加数据,最后解锁,然后就会在进去一次请求,还是只有一个线程执行,此时缓存中已经有数据了,这个线程就会到缓存中去查找,后续的都一样,所以就会执行一次查询数据的方法,这样就解决了缓存穿透这个问题。
缓存雪崩:如果机器宕机,数据丢失,是一种雪崩,如果redis添加了100w的数据,在同一时刻40w数据同时失效,也是一种雪崩,意思是在同一时刻大量数据丢失就可以理解为雪崩。
解决办法
A:搭建高可用集群
B:设置过期时间错开,不要把100w数据的过期时间全部设置成一样的,把时间错开来。比如有的3天,有的10天这种的。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
