社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
参考链接:
1、https://blog.csdn.net/u013108511/article/details/78577405
2、https://yiweifen.com/v-1-337993.html
3、https://blog.csdn.net/evolone/article/details/80765094
4、http://baijiahao.baidu.com/s?id=1599402950720714310&wfr=spider&for=pc
1、Introduction
主流的基于异构的GPU的加速和FPGA的加速,还有直接硬件化算法的 ASIC都没有真正处理还内存访问和内存带宽的限制,而由于大规模的神经网络的特点,这这种或多或少的直接给予DMA的方式不能对神经网络进行理想的加速。与CPU的设计不同的是将内存的访问作为设计的第一考虑因素。
首先调研了深度学习的加速器的设计,主要针对内存的使用进行设计,然后调研了加速器的架构设计和控制,尽可能的在最小化内存传输的同时提升效率。
具体的贡献总结如下:
1、对大规模的CNNs和DNNs机器学习算法的综合硬件的设计;
2、在很小的芯片空间上高吞吐率和低功耗;
3、专注访存的性能,性能不受计算任务访存的区别。
2、Primer on Recent Machine_Learning Techniques
神经网络经过多年的发展,目前达到很高水准的有CNNs和DNNs,他们相关性很高,只是在卷积层方面存在着差异。下面会从各个方面介绍神经网络。
训练和执行:目前实现的加速器主要是针对前向的运算而非反向的训练,这主要是商业诉求和技术促就的。技术上,有一个很大的误解就是在线学习的重要性,正相反,对于很对的工业应用而言,离线的学习就已经足够了,目前特别希望可以制定一种架构来加速训练的速度来针对一个很小的市场,对于这篇论文来说,主要关注针对终端用户的很大的市场。有趣的是最近涉足硬件加速器的机器学习研究员也做出了同样的选择。由于反向传播和前向传播有很多的相似性,后续会讨论支持训练的加速器的特征。
通用结构:尽管深度和卷积神经网络有很的组成形式,抽象其共同特征就可以给出统一的定义,通常定义的算法有一系列层组成。这些层通常顺序执行,因此可以看成是相互独立的,每个层有包含赌多个被称为特征映射的子层,我们称为输入特征映射和输出特征映射。总的来说,神经网络有三个很重要的层,分别是卷积层,池化层和分类层。
卷积层:解释一般卷积原理,DianNao的卷积后续会详细介绍Figure 3 Convoluational layer。
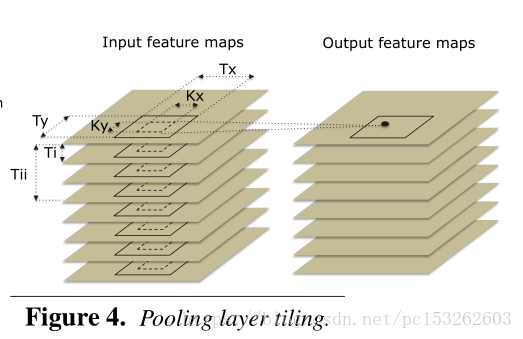
池化层:解释一般池化原理,DianNao的池化后续会详细介绍Figure 4 Pooling layer。
分类层:就是全连接层
3、Processor-Based Implementation of (large) Neural Networks
大型神经网络特点在于有很高的内存访问。在本章节中,我们将仔细分析内存的局部性原理,将其运用到各个layer中去,下面我们解释说明我们四个基本layer的带宽影响。对于本节内存带宽处理,我们通过cache模拟仿真,假设其具备每个cycle处理Tn个input、和Ti个weight(注:本文将neurons全部写出输入input,突触synapses全部写成weight)。Cache为Intel Core i7,L1 cache 大小为32KB,每行64byte,8 way,L2 cache 大小为2MB(optional),不同于i7,我们假设cache有足够的端口存储Tn4byte 给输入,TnTi4byte给weight,对于过大的Ti和Tn,导致cache过高,所以这里的cache只是用于本文内存和带宽的局部性原理,实验中,使用Ti=Tn=16。(注:我在实际处理时候使用的是Ti=Tn=32,原理一样。)
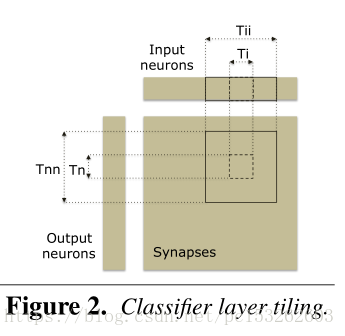
3.1 Classifier Layers
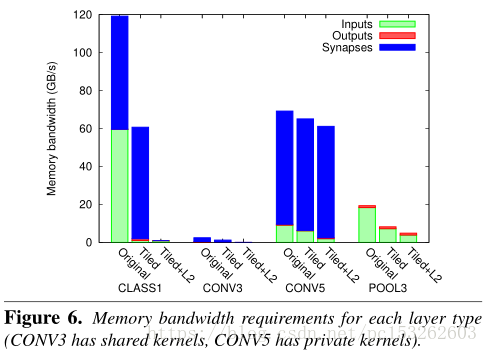
总共需要的带宽是(inputs load + synapse load + output load):NiNn + NiNn+ Nn。在Figure 6中可以看到,CLASS1的带宽达到了120GB/s,下面详细介绍如何降低带宽。
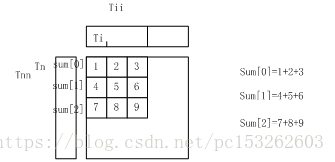
所有输入是不断向下移动的,input与weight乘积求和给output,所以对于output它是可以复用input,但是由于input过大,不能将所有的所需输入的input放到L1 cache中,所以tile输入,存入输入的Tii个数据,不断循环至完input。还有对于Tii与weight运算的部分和存入sum[n]
个人图解FC过程,将Tii放入cache,解决input 带宽问题。剩下weight 的带宽过大问题。
由于FC中,无法复用weight,所以利用2MB的L2 cache 将nerwork synapses全部存储,可以解决weight 的带宽问题。如图Figure 6的CONV3所示。
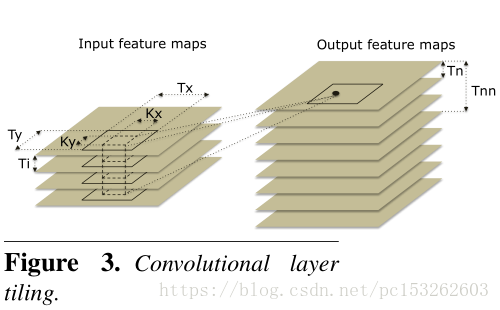
3.2 Convolutional Layers
本文考虑二维卷积层,如图Figure3和7所示,
Input/Output:对于输入和输出有两种类型复用机会。滑动子块扫描输入层和并将其复用到Z方向的Nn。KxKy/sx/sy和Nn复用次数。Tile方式按照Figure7来,将input的KxKyNi放入L1 cache中。如果放不下,将input tile,然后loop。
Synapse:由于KxKyNiNo超过L1 cahce的容量。取No中的Tnn个输出层,然后loop,以此减小weight的带宽。KxKyNiNnn放在L1 cahce。(注:我只考虑了CNN,没有考虑DNN)
3.3 Pooling Layers
看figure4和8
Pooling就是下采样,没有卷积
4、小神经网络的加速器
(这一章节主要讲解能适用小神经网络的硬件实现,大概读了一下,作者想说明自己做的必要性,讲解现在加速器的不足,本节摘与网络。这章节没啥意思)首先对之前关于神经网络加速器的实现进行一种评估,之前的加速器是将所有的神经元和突触硬件话,内存的使用只是输入阵列接口和输出保存结果。这种设计保证了设计的最小功耗,最近已经应用在感知器和基于脉冲式的神经网络硬件实现。
这种实现对于小规模神经网络是非常有效的,一方面高速度低延迟,另一方面是低功耗。
面积、延迟、功耗随着神经元数量的增加平方的形式增长。下图是神经网络规模延迟、芯片面积、功耗的关系图。图中的神经网络规模MxN中的M表示一个层上的神经元的个数,N表示每一层突触的个数。可能一个有较多神经元的全连接层就需要很大面积的芯片来实现,这对于大规模的神经网络硬件话来书是没办法实现的。
5、大规模神经网络加速器
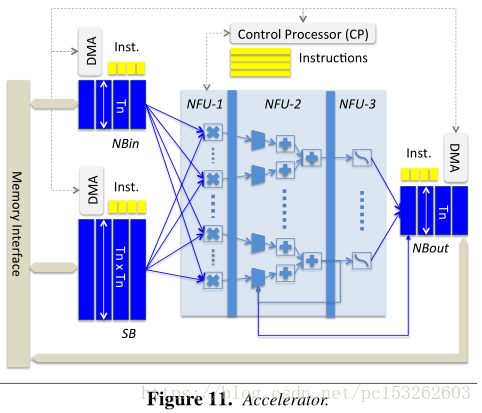
通过对神经网络结构的分析以及小规模的神经网络硬件带来的思考,下面是自己设计的加速器的组成和形式:
1、保存输入神经元的输入缓冲阵列(NBin)
2、保存输出神经元的输出缓冲阵列(NBout)
3、保存神经突触权重的第三个缓冲区(SB)
4、计算模块,称为神经功能单元(NFU)
5、控制逻辑(CP)
神经功能单元(NFU)用硬件逻辑模拟的神经网络结构。
计算操作:不同的层都可以讲计算划分为2或3个计算阶段。
1、分类器层:突出*输入;乘积求和;激活函数sigmoid
2、卷积层:计算阶段相同,只是激活函数可能不同
3、池化层:没有乘积的操作,可以是求最大池化和平均池化。
阶段流水化:将所有的2到3个操作进行流水化,流水化过程中重要的是分析三类不同层的特点。
NFU-1全是乘法单元。16X16=256个乘法器。这些乘法器同时计算,也就是说,一个周期可以执行256个乘法。
NFU-2是加法树。16个。每个加法树是按照8-4-2-1这样组成的结构。每个加法数有15个加法器。
NFU-3是激活单元。16个。
可以看出,NFU的所有逻辑资源,可以整体划分为16份,每一份,包括16个乘法器,15个加法器,1个激活。它的运算过程是,16个乘法器同时计算出16个结果,送给加法树(最左的8个加法器,每个有2个输入,恰好接收16个输入),形成一个结果,然后再送入激活。
NFU-1和NFU-2目的是计算出单个神经元接受到的所有刺激的量。
NFU-3是根据前面两个单元计算得到的刺激量,去判断是否需要激活操作。
除了这三个阶段的计算逻辑,剩下还有三个Buffer。一个存储输入数据,一个存储权值(filter值),一个存储计算结果。
16位定点操作代替32位浮点:大大降低芯片面积,减小计算量,降低功耗而仅仅损失一小部分的精度。
When I plan to write the test of the aricle,it’s useless as I know why nobody write it.U can read it by yourself.I will write something about the essence of DianNao’s convolution for reference.
重点来了!!!!!!!!!!!!!!!
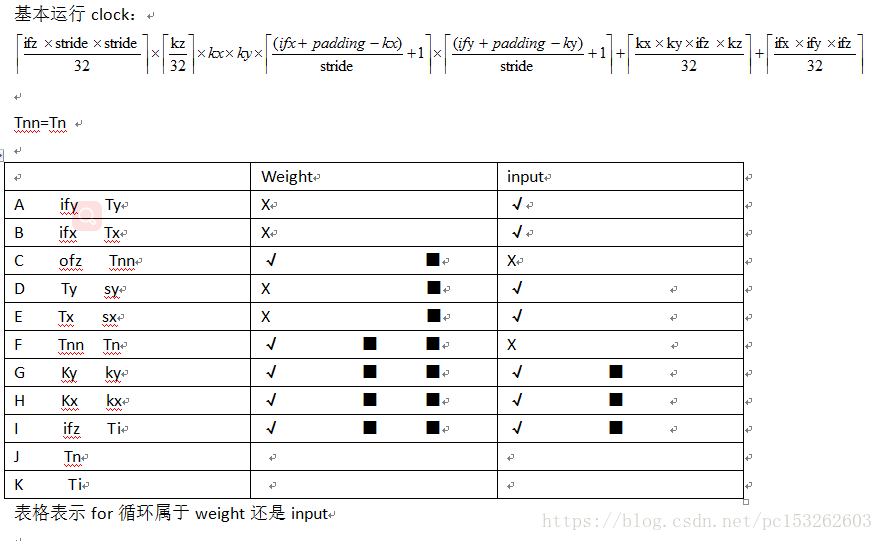
A、B循环是将feature map划分tile,分别是Tx、Ty。C循环是ofz输出层的Tnn个层,D和E循环tile,D以sy步长循环Ty,E以sx步长循环Tx,F是将Tnn划分层PE单元的Tn个层,Tn是最小输出层,( TIP:DianNao是1616,我的是3232,以下全以3232为准),sum[n]赋0,只为了在处理之前清零。G、H是循环KxKy,I是以Ti=32层的单位将ifz全部处理完,J、K是加速器的输入和输出,Ti=32的输入,Tn=32的输出,处理时间为一个clock,
(Ni、Tn、Ti三个循环意思是:设Ni=74,它将分为32+32+10,K循环第一个32,J循环Tn=32层(在kz)32的情况下),然后K循环第二个32,将结果叠加在之前的Tn=32上,最后在循环10,结果加在之前的Tn=32上,这个第一个点的Ni的输出的Tn=32值就弄完了),DianNao的方法就是先遍历完ifz,把第一个点的第一个Tn层的结果算出来,然后在把KyKx点的第一个Tn层的结果算出来,然后在遍历ofz,输出N个Tn层,所以SB buffer必须存储KxKyTnNi的数值,(这里没有选择Tnn是因为选择最小的Tn=32时候,在常用SSD网络中,SB buffer值已经达到了33322080个数了),DianNao的缺点是Ni不确定,导致SB大小不确定,有些很大,有些很小,我们为了防止底层重复load weights,所以将最大的package,buffer SB设为33322080
Weight的大小设为92163222,33是kernel的大小,9216是kxkyifz最大值,32是Tn,2是B,2是FIFO,FIFO时候可以不需要load wight的时间,F、G、H、I的clock是kxkyNi/Ti,需要weights 的大小是kxkyNi,当weight带宽是32时,双缓冲有效。
46083222=576KB,其中4608是一个合理的Ni最大值
460832=147456
Inputs的大小是921622,因为处理小块不浪费时间,大的也不需要了,2是B,2是FIFO,F、G、H、I的clock是kxkyNi/Ti,需要inputs的大小是kxkyNi,当inputs带宽时32时,双缓冲有效。所以带宽需要64,也就是128GB。
921622=36KB,9216是kxkyifz合理的最大值。
9216
NBout的大小时Tnnsxsy22,(当直接全部输出TxTyTnn是全部存在NBout),2是B,2是FIFO,当使得Tnn=Tn时,直接输出ifz,Tx=sx、Ty=sy,2是B,2是FIFO
Tnn22 Tnn如何设置,在网络较小时,kxkyifz越小时,Tnn越大,最大也就是2080/27,所以给其设定1000,就是4K。
全连接中ifz最大为1000
DianNao卷积clock
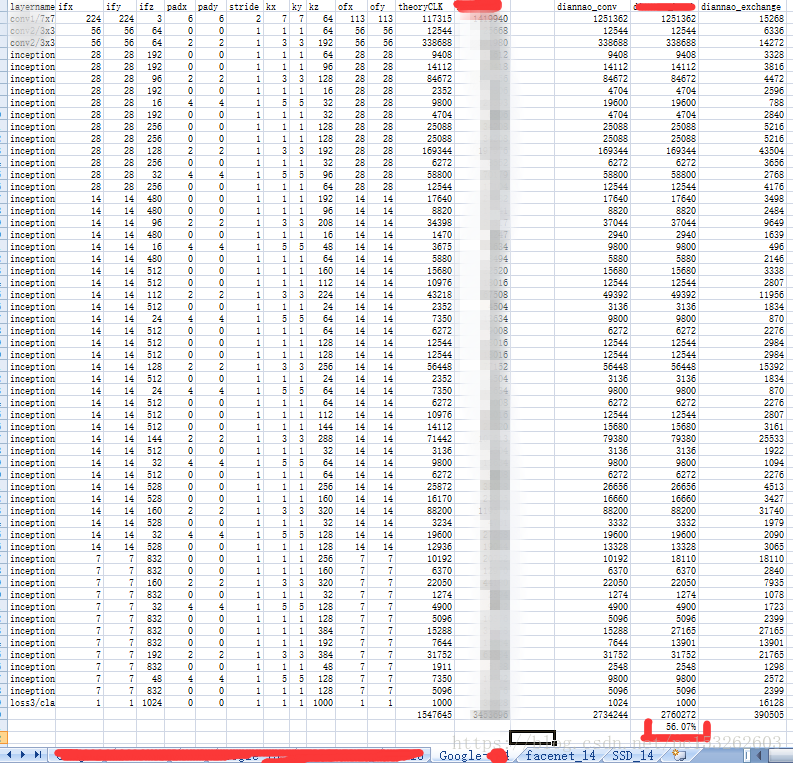
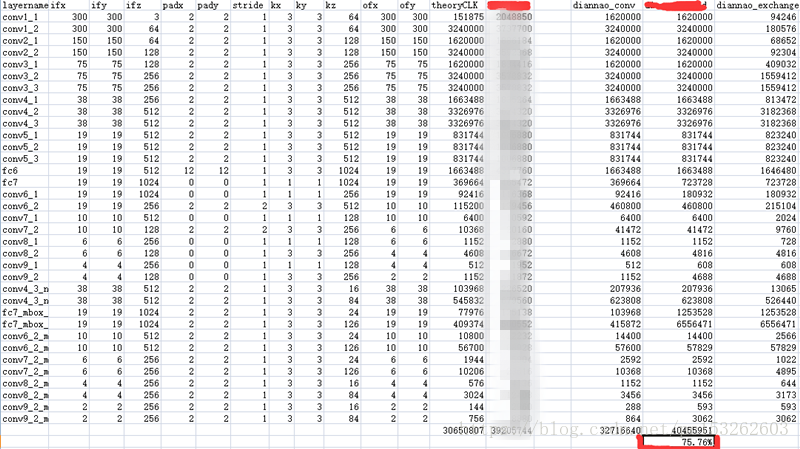
这里在计算给定weight和input 的buffer size后,对处理Google、faceNet和SSDnet时候切换数据所需要的clock。
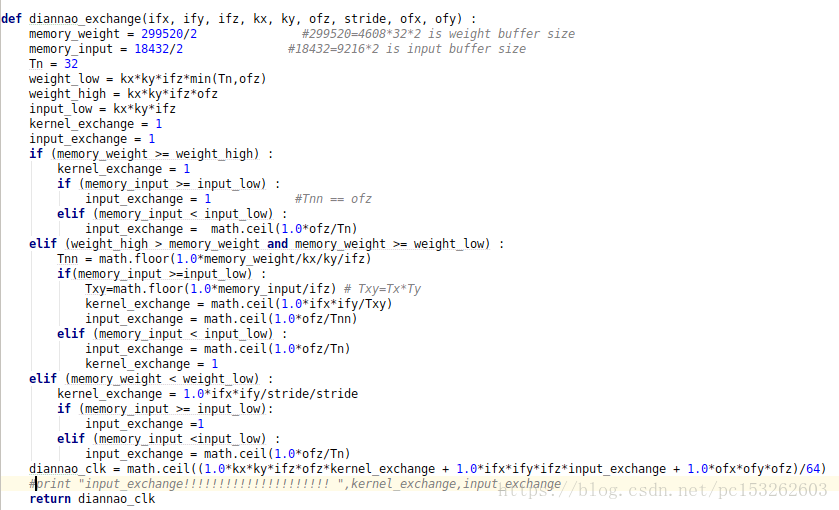
写出weight和input相互约束的伪代码:
对表格解释一下
weight在F、C之间时,可以复用weight,减少带宽,复用次数为Tx*Ty。当在F、C之间时候,我们要尽量扩大Tnn的数值,好让input的复用次数增加,因为数据表格中Tnn、Tx、Ty都是不定值,所以要看情况分析。原来打算将input也分为三个区域,但是C区域包涵了Tx、Ty不能确定所属区域范围,或者这样说:A、B、D、E就是input,它可以任意分配数据存放,不是一个固定值。
伪代码
//Tnn = floor(memory_W/kx/ky/ifz/32)
//Tx*Ty=memory_I/ifz
Tx*Ty=memory_I/ifz
w_L = kx*ky*ofz*ifz
w_h = kx*ky*ifz*Tnn(Tnn=Tn=32)
I_L = kx*ky*ifz
if(w_h<=memory_W)
kernel_exchange=1
if(I_L<=memory_I)
input_exchange=1 #Tnn == ofz
else if(I_L>memory_I)
input_exchange=ceil(ofz/Tn)
else if(w_L<=memory_W<w_h)
Tnn = floor(memory_W/kx/ky/ifz)
if(I_L<=memory_I)
Tx*Ty=floor(memory_I/ifz)
kernel_exchange=ceil(ifx*ify/Tx/Ty)
input_exchange=ofz/Tnn
else if(I_L>memory_I)
input_exchange=ofz/Tn
kernel_exchange=1
else if(w_L>memory_W)
kernel_exchange=ifx*ify/sx/sy
if(I_L<=memory_I)
input_exchange=1
else if(I_L>memory_I)
input_exchange=ofz/Tn
最后DianNao的clk是DianNao_conv 与DianNao_exchange相比较得到的最大值
对于全连接的clk计算时间为:
FC_clk: Tii/32Tnn/32ifz/Tiiofz/Tnn
Kernel_exchange=1
Out_exchange=1
Input_exchange=ceiling(ofz/Tnn,1)
Input_buffer_size:Tii
output_buffer_size: Tnn
SB:TiiTnn
GoogleNet和SSDNet的结果DianNao的效率,theoryCLK是百分百的效率计算时间
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!