社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
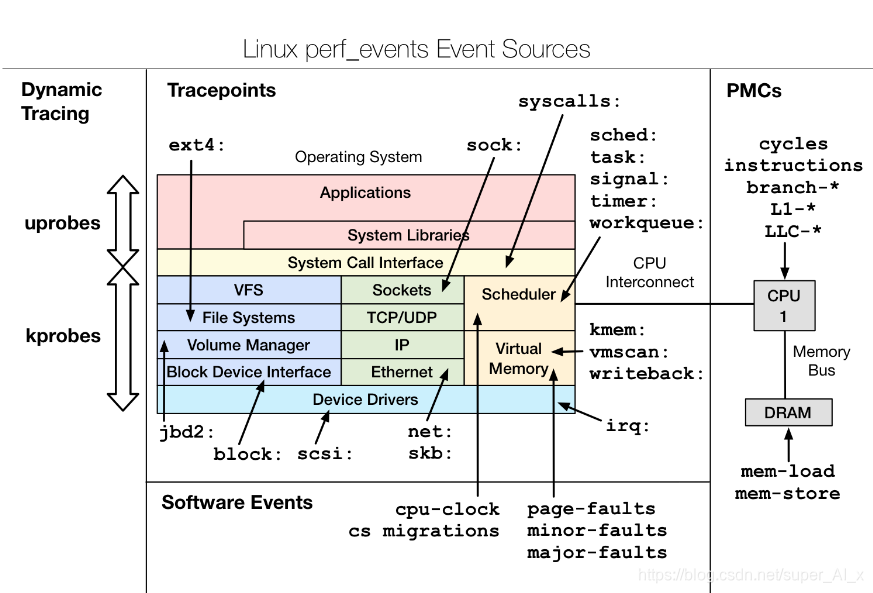
per 功能介绍:
perf_events是一个面向事件的可观察性工具,可以帮助您解决高级性能和故障排除功能。 可以回答的问题包括:
1:为什么内核在CPU上这么多? 什么代码路径?
2:哪些代码路径导致CPU级别2缓存未命中?
3:CPU是否在内存I / O上停滞不前?
4:哪些代码路径分配内存,以及多少?
5:什么是触发TCP重传?
6:是否正在调用某个内核函数,并且多久一次?
7:线程离开CPU的原因是什么?
perf_events是Linux内核的一部分,在tools / perf下。 虽然它使用了许多Linux跟踪功能,但有些功能尚未通过perf命令公开,而是需要通过ftrace接口使用。 我的perf-tools集合(github)根据需要使用perf_events和ftrace。
关键部分包括:事件,单行,演示文稿,先决条件,CPU统计信息,定时分析和火焰图。 另请参阅我关于perf_events的帖子,以及主要(官方)perf_events页面的链接,很棒的教程和其他链接。 接下来的部分将进一步介绍perf_events,从屏幕截图,单行开始,然后是背景开始。
这个页面正在构建中,而且我想添加的perf_events还有很多。 希望到目前为止这是有用的。
1.截图
从屏幕截图开始,这里的perf版本3.9.3跟踪磁盘I / O: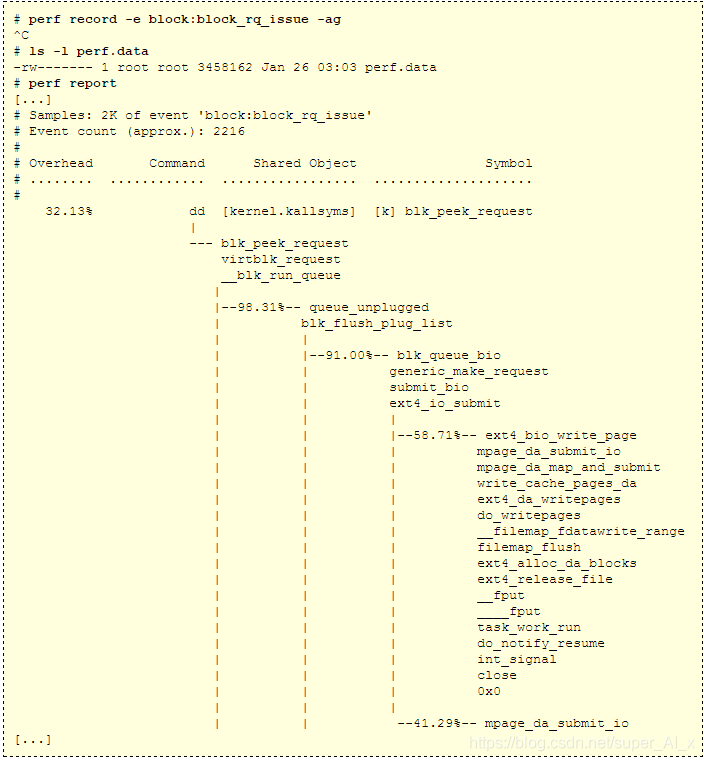
使用perf记录命令跟踪块:block_rq_issue探测器,该探测器在发出块设备I / O请求时触发(磁盘I / O)。 选项包括 -a跟踪所有CPU,-g捕获调用图(堆栈跟踪)。 跟踪数据被写入perf.data文件,并且在Ctrl-C被命中时跟踪结束。 使用perf报告打印perf.data文件的摘要,该报告从堆栈跟踪构建树,合并公共路径,并显示每个路径的百分比。
perf报告输出显示跟踪了2,216个事件(磁盘I / O),其中32%来自dd命令。 这些是由内核函数blk_peek_request()发出的,并且在堆栈中向下走,这些32%中的大约一半来自close()系统调用。
请注意,我使用“#”提示符表示这些命令是以root身份运行的,我将使用“$”作为用户命令。 根据需要使用sudo。
2.单线
我收集或写过的一些有用的单行。 我正在使用的术语,从最低到最高的开销:
statistics / count:增加事件的整数计数器
sample:从事件子集中收集详细信息(例如,指令指针或堆栈)(每次…)
trace:收集每个事件的详细信息
Listing Events
# Listing all currently known events:
perf list
# Listing sched tracepoints:
perf list 'sched:*'
计算事件
#指定命令的CPU计数器统计信息:
perf stat command
#指定命令的详细CPU计数器统计信息(包括附加内容):
perf stat -d command
#CPU计数器指定PID的统计信息,直到Ctrl-C:
perf stat -p PID
#CPU计数器统计整个系统,持续5秒:
perf stat -a sleep 5
#系统范围内的各种基本CPU统计信息,持续10秒:
perf stat -e循环,指令,缓存引用,缓存未命中,总线循环 - 睡眠10
#指定命令的各种CPU级别1数据高速缓存统计信息:
perf stat -e L1-dcache-loads,L1-dcache-load-miss,L1-dcache-stores command
#指定命令的各种CPU数据TLB统计信息:
perf stat -e dTLB-loads,dTLB-load-miss,dTLB-prefetch-missses command
#指定命令的各种CPU最后一级缓存统计信息:
perf stat -e LLC-loads,LLC-load-miss,LLC-stores,LLC-prefetches command
#使用原始PMC计数器,例如,计算未经加速的核心周期:
perf stat -e r003c -a sleep 5
#PMCs:通过原始规范计算周期和前端停顿:
perf stat -e cycles -e cpu / event = 0x0e,umask = 0x01,inv,cmask = 0x01 / -a sleep 5
#计算系统范围内的每秒系统调用次数:
perf stat -e raw_syscalls:sys_enter -I 1000 -a
#按类型为指定的PID计算系统调用,直到Ctrl-C:
perf stat -e'scccalls:sys_enter_ *' - p PID
#按整个系统的类型计算系统调用,持续5秒:
perf stat -e'syscalls:sys_enter_ *'-a sleep 5
#计算指定PID的调度程序事件,直到Ctrl-C:
perf stat -e'ssched:*' - p PID
#计算指定PID的调度程序事件,持续10秒:
perf stat -e'ssched:*' - p PID sleep 10
#计算整个系统的ext4事件,持续10秒:
perf stat -e'ext4:*' - 睡觉10
#计算整个系统的块设备I / O事件,持续10秒:
perf stat -e'block:*'-a sleep 10
#计算所有vmscan事件,每秒打印一次报告:
perf stat -e'vmscan:*' - a -I 1000
剖析:
#示例指令命令的CPU函数示例,为99赫兹:
perf record -F 99 command
#示例指定PID的CPU函数,为99赫兹,直到Ctrl-C:
perf record -F 99 -p PID
#示例指定PID的CPU函数,99赫兹,持续10秒:
perf record -F 99 -p PID sleep 10
#对指定PID的CPU堆栈跟踪(通过帧指针)进行采样,为99赫兹,持续10秒:
perf record -F 99 -p PID -g -- sleep 10
#示例PID的CPU堆栈跟踪,使用dwarf(dbg info)以99赫兹的速度展开堆栈,持续10秒:
perf record -F 99 -p PID --call-graph dwarf sleep 10
#示例整个系统的CPU堆栈跟踪,为99赫兹,持续10秒(<Linux 4.11):
perf record -F 99 -ag -- sleep 10
#整个系统的CPU堆栈跟踪样本,为99赫兹,持续10秒(> = Linux 4.11):
perf record -F 99 -g -- sleep 10
#如果上一个命令不起作用,请尝试强制perf使用cpu-clock事件:
perf record -F 99 -e cpu-clock -ag -- sleep 10
#示例由/ sys / fs / cgroup / perf_event cgroup标识的容器的CPU堆栈跟踪:
perf record -F 99 -e cpu-clock --cgroup=docker/1d567f4393190204...etc... -a -- sleep 10
#示例整个系统的CPU堆栈跟踪,使用矮化堆栈,速度为99赫兹,持续10秒:
perf record -F 99 -a --call-graph dwarf sleep 10
#示例整个系统的CPU堆栈跟踪,使用堆栈的最后一个分支记录,...(> = Linux 4.?):
perf record -F 99 -a --call-graph lbr sleep 10
#示例CPU堆栈跟踪,每10,000个1级数据高速缓存未命中,持续5秒:
perf record -e L1-dcache-load-misses -c 10000 -ag -- sleep 5
#示例CPU堆栈跟踪,每100个最后一级缓存未命中,持续5秒:
perf record -e LLC-load-misses -c 100 -ag -- sleep 5
#Sample内核指令示例,持续5秒:
perf record -e cycles:k -a -- sleep 5
#Sample用户指令示例,持续5秒:
perf record -e cycles:u -a -- sleep 5
#精确地使用CPU用户指令(使用PEBS),持续5秒:
perf record -e cycles:up -a -- sleep 5
#执行分支跟踪(需要硬件支持),持续1秒:
perf record -b -a sleep 1
#示例CPU为49赫兹,显示顶部地址和符号,实时(无perf.data文件):
perf top -F 49
#示例CPU为49赫兹,显示顶级进程名称和段,实时:
perf top -F 49 -ns comm,dso
静态跟踪
#跟踪新进程,直到Ctrl-C:
perf记录-e sched:sched_process_exec -a
#示例上下文切换,直到Ctrl-C:
perf record -e context-switches -a
#跟踪所有上下文切换,直到Ctrl-C:
perf record -e context-switches -c 1 -a
#包括使用的原始设置(请参阅:man perf_event_open):
perf record -vv -e context-switches -a
#通过sched tracepoint跟踪所有上下文切换,直到Ctrl-C:
perf record -e sched:sched_switch -a
#使用堆栈跟踪的示例上下文切换,直到Ctrl-C:
perf record -e context-switches -ag
#使用堆栈跟踪的示例上下文切换,持续10秒:
perf record -e context-switches -ag - sleep 10
#Sample CS,堆栈跟踪和时间戳(<Linux 3.17,-T now now):
perf record -e context-switches -ag -T
#示例CPU迁移,持续10秒:
perf record -e migrations -a - sleep 10
#使用堆栈跟踪(出站连接)跟踪所有connect(),直到Ctrl-C:
perf record -e syscalls:sys_enter_connect -ag
#使用堆栈跟踪(入站连接)跟踪所有accept(),直到Ctrl-C:
perf record -e syscalls:sys_enter_accept * -ag
#使用堆栈跟踪跟踪所有块设备(磁盘I / O)请求,直到Ctrl-C:
perf record -e block:block_rq_insert -ag
#跟踪所有块设备问题和完成(有时间戳),直到Ctrl-C:
perf record -e block:block_rq_issue -e block:block_rq_complete -a
#跟踪所有块完成,大小至少为100 KB,直到Ctrl-C:
perf record -e block:block_rq_complete --filter'nr_sector> 200'
#跟踪所有块完成,仅同步写入,直到Ctrl-C:
perf record -e block:block_rq_complete --filter'rwbs ==“WS”'
#跟踪所有块完成,所有类型的写入,直到Ctrl-C:
perf record -e block:block_rq_complete --filter'rwbs〜“* W *”'
#使用堆栈跟踪示例小故障(RSS增长),直到Ctrl-C:
perf record -e minor-faults -ag
#使用堆栈跟踪跟踪所有次要故障,直到Ctrl-C:
perf record -e minor-faults -c 1 -ag
#堆栈跟踪的示例页面错误,直到Ctrl-C:
perf record -e page-faults -ag
#跟踪所有ext4调用,并写入非ext4位置,直到Ctrl-C:
perf record -e'ext4:*' - o /tmp/perf.data -a
#Trace kswapd唤醒事件,直到Ctrl-C:
perf record -e vmscan:mm_vmscan_wakeup_kswapd -ag
#添加Node.js USDT探针(Linux 4.10+):
perf buildid-cache --add `which node`
#跟踪节点http__server__request USDT事件(Linux 4.10+):
perf record -e sdt_node:http__server__request -a
动态追踪
#为内核tcp_sendmsg()函数条目添加一个跟踪点(“ - add”是可选的):
perf probe --add tcp_sendmsg
#删除tcp_sendmsg()跟踪点(或使用“--del”):
perf probe -d tcp_sendmsg
#为内核添加跟踪点tcp_sendmsg()函数返回:
perf probe 'tcp_sendmsg%return'
#显示内核tcp_sendmsg()函数的可用变量(需要debuginfo):
perf probe -V tcp_sendmsg
#显示内核tcp_sendmsg()函数的可用变量,以及外部变量(需要debuginfo):
perf probe -V tcp_sendmsg --externs
#显示tcp_sendmsg()的可用行探测(需要debuginfo):
perf probe -L tcp_sendmsg
#在第81行显示tcp_sendmsg()的可用变量(需要debuginfo):
perf probe -V tcp_sendmsg:81
#为tcp_sendmsg()添加一个跟踪点,带有三个入口参数寄存器(特定于平台):
perf probe'tcp_sendmsg%ax%dx%cx'
#为tcp_sendmsg()添加一个跟踪点,其中包含%cx寄存器的别名(“bytes”)(特定于平台):
perf probe'tcp_sendmsg bytes =%cx'
#当bytes(别名)变量大于100时,跟踪先前创建的探测:
perf record -e probe:tcp_sendmsg --filter'bytes> 100'
#为tcp_sendmsg()返回一个tracepoint,并捕获返回值:
perf probe'tcp_sendmsg%return $ retval'
#为tcp_sendmsg()和“size”条目参数添加一个跟踪点(可靠,但需要debuginfo):
perf probe'tcp_sendmsg size'
#为tcp_sendmsg()添加一个跟踪点,其大小和套接字状态(需要debuginfo):
perf probe'tcp_sendmsg size sk - > __ sk_common.skc_state'
#告诉我你在地球上会怎么做,但实际上并不这样做(需要debuginfo):
perf probe -nv'tcp_sendmsg size sk - > __ sk_common.skc_state'
#当size不为零时跟踪上一个探测,状态不是TCP_ESTABLISHED(1)(需要debuginfo):
perf record -e probe:tcp_sendmsg --filter'size> 0 && skc_state!= 1'-a
#使用局部变量seglen(需要debuginfo)为tcp_sendmsg()第81行添加一个跟踪点:
perf probe'tcp_sendmsg:81 seglen'
#为do_sys_open()添加一个跟踪点,文件名为字符串(需要debuginfo):
perf probe'do_sys_open filename:string'
#为myfunc()返回添加跟踪点,并将retval包含为字符串:
perf probe'myfunc%return +0($ retval):string'
#从libc添加用户级malloc()函数的跟踪点:
perf probe -x /lib64/libc.so.6 malloc
#为此用户级静态探测添加跟踪点(USDT,又称SDT事件):
perf probe -x /usr/lib64/libpthread-2.24.so% sdt_libpthread:mutex_entry
#列出当前可用的动态探针:
perf probe -l
Mixed
#按进程跟踪系统调用,每2秒刷新一次摘要:
perf top -e raw_syscalls:sys_enter -ns comm
#Trace通过CPU进程发送网络数据包,滚动输出(不清楚):
stdbuf -oL perf top -e net:net_dev_xmit -ns comm | strings
#示例堆栈为99赫兹,以及上下文切换:
perf record -F99 -e cpu-clock -e cs -a -g
#示例堆栈深度为2级,上下文切换堆栈为5级(需要4.8):
perf record -F99 -e cpu-clock/max-stack=2/ -e cs/max-stack=5/ -a -g
Special
#记录缓存行事件(Linux 4.10+):
perf c2c record -a -- sleep 10
#报告以前录制的缓存行事件(Linux 4.10+):
perf c2c report
Reporting
#如果可能,在ncurses浏览器(TUI)中显示perf.data:
perf report
#显示带有样本计数列的perf.data:
perf report -n
#将perf.data显示为文本报告,数据合并为百分比:
perf report --stdio
#Report,折叠格式的堆栈:每堆一行(需要4.4):
perf report --stdio -n -g folded
#列出perf.data中的所有事件:
perf script
#列出所有perf.data事件,包含数据头(较新的内核;以前是默认的):
perf script --header
#列出所有perf.data事件,使用自定义字段(<Linux 4.1):
perf script -F time,event,trace
#列出所有perf.data事件,使用自定义字段(> = Linux 4.1):
perf script -F time,event,trace
#列出所有perf.data事件,包括我推荐的字段(需要记录-a;较新的内核):
perf script --header -F comm,pid,tid,cpu,time,event,ip,sym,dso
#列出所有perf.data事件,包括我推荐的字段(需要记录-a;较旧的内核):
perf script -f comm,pid,tid,cpu,time,event,ip,sym,dso
#将perf.data中的原始内容转储为十六进制(用于调试):
perf script -D
#用百分比反汇编和注释指令(需要一些debuginfo):
perf annotate --stdio
--------------------未完 待续
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
