社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
我们经常在编程中碰到一种情况叫符号重复定义。多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误。比如我们在目标文件A和目标文件B都定义了一个全局整形变量global,并将它们都初始化,那么链接器将A和B进行链接时会报错:
1 b.o:(.data+0x0): multiple definition of `global'
2 a.o:(.data+0x0): first defined here
这种符号的定义可以被称为强符号(Strong Symbol)。有些符号的定义可以被称为弱符号(Weak Symbol)。
对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。我们也可以通过GCC的"__attribute__((weak))"来定义任何一个强符号为弱符号。注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用。比如我们有下面这段程序:
extern int ext;
int weak;
int strong = 1;
__attribute__((weak)) weak2 = 2;
int main()
{
return 0;
}
上面这段程序中,"weak"和"weak2"是弱符号,"strong"和"main"是强符号,而"ext"既非强符号也非弱符号,因为它是一个外部变量的引用。
针对强弱符号的概念,链接器就会按如下规则处理与选择被多次定义的全局符号:
· 规则1:不允许强符号被多次定义(即不同的目标文件中不能有同名的强符号);如果有多个强符号定义,则链接器报符号重复定义错误。
· 规则2:如果一个符号在某个目标文件中是强符号,在其他文件中都是弱符号,那么选择强符号。
· 规则3:如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。比如目标文件A定义全局变量global为int型,占4个字节;目标文件B定义global为double型,占8个字节,那么目标文件A和B链接后,符号global占8个字节(尽量不要使用多个不同类型的弱符号,否则容易导致很难发现的程序错误)。
弱引用和强引用
目前我们所看到的对外部目标文件的符号引用在目标文件被最终链接成可执行文件时,它们须要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误,这种被称为强引用(Strong Reference)。与之相对应还有一种弱引用(Weak Reference),在处理弱引用时,如果该符号有定义,则链接器将该符号的引用决议;如果该符号未被定义,则链接器对于该引用不报错。链接器处理强引用和弱引用的过程几乎一样,只是对于未定义的弱引用,链接器不认为它是一个错误。一般对于未定义的弱引用,链接器默认其为0,或者是一个特殊的值,以便于程序代码能够识别。
在GCC中,我们可以通过使用"__attribute__((weakref))"这个扩展关键字来声明对一个外部函数的引用为弱引用,比如下面这段代码:
1 __attribute__ ((weakref)) void foo();
2 int main()
3 {
4 foo();
5 }
6
我们可以将它编译成一个可执行文件,GCC并不会报链接错误。但是当我们运行这个可执行文件时,会发生运行错误。因为当main函数试图调用foo函数时,foo函数的地址为0,于是发生了非法地址访问的错误。一个改进的例子是:
1 __attribute__ ((weakref)) void foo();
2 int main()
3 {
4 if (foo)
5 foo();
6 }
7
这种弱符号和弱引用对于库来说十分有用,比如库中定义的弱符号可以被用户定义的强符号所覆盖,从而使得程序可以使用自定义版本的库函数;或者程序可以对某些扩展功能模块的引用定义为弱引用,当我们将扩展模块与程序链接在一起时,功能模块就可以正常使用;如果我们去掉了某些功能模块,那么程序也可以正常链接,只是缺少了相应的功能,这使得程序的功能更加容易裁剪和组合。
在Linux程序的设计中,如果一个程序被设计成可以支持单线程或多线程的模式,就可以通过弱引用的方法来判断当前的程序是链接到了单线程的Glibc库还是多线程的Glibc库(是否在编译时有-lpthread选项),从而执行单线程版本的程序或多线程版本的程序。我们可以在程序中定义一个pthread_create函数的弱引用,然后程序在运行时动态判断是否链接到pthread库从而决定执行多线程版本还是单线程版本。
编译的时候可以给ld传递--audit AUDITLIB参数,如此就会创建一个DT_AUDIT section,ld.so看到这个section就会去执行glibc规定的audit接口。在特定的事件发生的时候,会去编译指定的库中找到指定的函数来执行。例如当程序调用dlopen打开了一个动态库的时候,就会发生一个事件,从而调用指定库中的 la_objopen()函数。
这个接口是用来做连接维度的统计的,更多被连接器的开发者使用。但是开发者可以利用单独分发的这个库做函数实现版本的管理和替换。例如加载一个库的时候首先调用了audit接口,在audit接口中,我们将要打开的库替换掉。
动态库的核心包含了两个层次的代码共享:编译成的二进制可以不用每个二进制文件都包含一份动态库的拷贝;在执行的时候,动态库的代码段只需要加载一次,后面再有人用到同一个动态库,内核就可以把动态库代码段加载到的页面直接映射到其他需要的进程,这样代码段也不用加载多次(代码段是只读的)。
而加载到内存,由于CPU执行的时候必须要使用相对或者绝对地址,代码段的每个函数虽然在物理地址是一样的,但是他们映射到每个进程内存空间的地址都是不一样的。所以动态库需要有一份符号表,记录了其在代码段的偏移,然后还需要一个全局偏移,意味着其整个符号表在进程地址空间中的偏移。
而一个使用了动态库的可执行文件,其内部有调用这些符号的代码,这种代码是无法在链接期解析出具体的地址偏移的(因为链接器根本没有实际的链接他们),所以他们在二进制文件中只是一个占位符,其地址需要在动态库加载了之后再填充。而这种调用是分散在整个程序中的,所以在加载后就得去搜索找到所有的未解析符号去解析,这样肯定是不合适的,所以就需要有一个表,记录了所有这些没有解析的符号。
动态库在内存中只要执行到任何一行动态库的代码,动态库就可以通过偏移找到本库内的其他符号,因为同一个库的符号偏移,本库内都是知道的。但是可惜的是i386不支持通过当前执行指令(PC)偏移的寻址方式(如果支持就简单了,根本什么重分配都不需要,只需要在执行到的代码中使用偏移就好了)。但是x64是支持的,所以elf在x64时代慢慢的可能要有点变化。
上面分别说了可执行文件和动态库的需求,两者的衔接就是通过.got段和.plt段.got是数据外部解析,.plt是函数外部解析。Elf文件链接完成,将调用动态库的符号放到这两个表里,当动态库加载的时候,加载器要负责查找这个表,将加载的动态库的对应的符号所在内存的地址填充到可执行文件的这两个表,如此完成加载时候的符号绑定。同时解决了动态库位置不固定的问题。
X86与x64提供了栈的寄存器指针,但是并不规定怎么使用这个栈,例如参数入栈的先后顺序,返回值放在哪里,两个调用之间是否要空点空间。
在x86时代,常用的调用栈有:stdcall, thiscall, fastcall, cdecl,这几种在对栈的使用上有区别。在x64时代,只剩下fastcall一种。例如stdcall的调用约定意味着:1)参数从右向左压入堆栈,2)函数自身修改堆栈 3)函数名自动加前导的下划线,后面紧跟一个@符号,其后紧跟着参数的尺寸。Stdcall因为早期用在pascal有此殊荣。c的默认是cdel,cdecl调用约定的参数压栈顺序是和stdcall是一样的,参数首先由右向左压入堆栈。所不同的是,函数本身不清理堆栈,调用者负责清理堆栈。由于这种变化,C调用约定允许函数的参数的个数是不固定的,这也是C语言的一大特色。thiscall是为了解决面向对象的函数调用要默认传输this指针,所以是C++的默认调用方式,参数从右向左入栈。
而fastcall使用寄存器来传递参数,因为在x64环境,寄存器很多,所以规定了fastcall的前4个整数和浮点都放入寄存器中,超过的部分才放入栈中。所以,使用fastcall可以显著的加快调用速度。也是因此,在写代码的时候,尽量使用4个以下的函数参数。fastcall也保留了cdel的灵活,由调用者清理栈,所以也可以做到参数不固定。但是你看你的栈可能会发现有一块额外的空间,x64会默认的在站上分配一个备份空间,用来core dump分析的时候方便。这个空间保存了每次发生函数调用的寄存器情况。如果你开了编译器优化,这个空间一般就不会保留了。
当一个参与动态链接,其内部含有PT_DYNAMIC段,这个段里含有.dynamic这个section,.rel.plt section是用于函数重定位,.rel.dyn section是用于变量重定位。.got section保存全局变量偏移表,.got.plt section存储着全局函数偏离表。.dynsym节区包含了动态链接符号表。.plt节是过程链接表。过程链接表把位置独立的函数调用重定向到绝对位置。
程序在执行的过程中,可能引入的有些C库函数到结束时都不会执行。所以ELF采用延迟绑定的技术,在第一次调用C库函数是时才会去寻找真正的位置进行绑定。但是也有设置为加载的时候就全部完成绑定(RELRO攻击对抗技术就是这样)。
一个应用由一个主要ELF二进制文件(可执行文件)和数个动态库构成,它们都是ELF格式。每个ELF对象由多个segments组成,每个segment则含有一个或多个sections。这些段看起来很多,但是大都非常简单。每一个段基本只存储一种类型的数据,例如.dynstr里面就是有字符串。每一个段我们都要将其理解为一个表,而不是一个结构体数组。这个表里面放的都是相同结构的数据,并且基本上只有一两种数据。结构体的概念更多是横向的,一个结构体可能包含多个表。
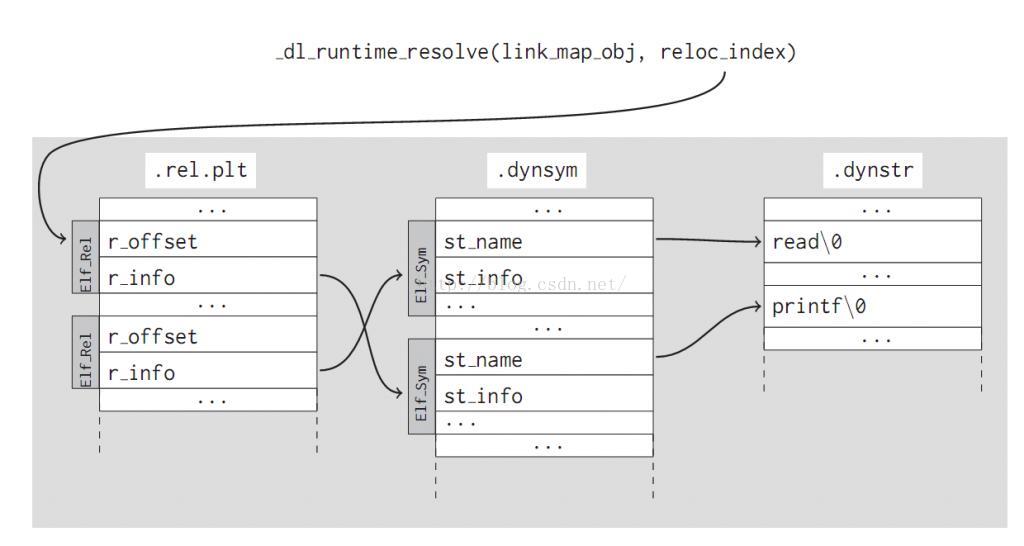
例如.rel.plt中有待解析外部符号的桩函数每个elf要访问外部符号的时候,首先进入到.rel.plt中对应的桩函数,这个桩函数会进入对应的.got.plt中的条目加载对应的外部符号,并且把符号地址存放在.got.plt中,这样以后再访问的时候.rel-plt中的桩函数就可以直接从.got.plt中拿。这就是惰性加载的原理。
而每个.rel.plt中条目都指向一个.dynsym条目,每个.dynsym条目都指向一个.dynstr条目。.dynstr里面只有字符串,而.dynsym中存储的数据有这个符号的虚地址(在没有执行的时候,虚地址自然为0)和符号的类型和绑定类型,如下图:
Elf文件中有两种section:可分配和不可分配的,可分配就是在运行时会被加载到内存的,不可分配的就是给调试器用的,在执行的时候没用。Strip程序可以把这些执行期无用的东西删除,使得文件更小。有两种符号表:.symtab and .dynsym,.dynsym是.symtab的子集,.dynsyn是运行期需要的,而.symtab调试需要的。Strip可以把.symtab去掉。
http://www.inforsec.org/wp/?p=389
elf安全性
当有了root权限之后,内核了无秘密。大部分人即使获得了root权限,能看到的东西也不多,其实linux已经提供了,只是大家没有找到查看的方法。
例如我们可以查看任何物理内存的内容,方法是通过打开/dev/mem设备,然后mmap到你的程序,直接读取就好了。我们也可以查看任何的内核数据(不只是proc和sys文件系统暴漏出来的信息),方法是打开/proc/kmem设备,然后直接读取
我们每个进程可以查看自己的所有可读内存,方法是使用/proc/<pid>/mem,你可能cat这个文件永远是错误,因为不是所有的内存都被进程映射了,尤其是文件开始的位置,所以需要根据/proc/<pid>/mmaps文件找到具体的文件映射的模式,然后seek到对应的偏移才能读。这种需求基本没有,因为既然是我们自己的进程,我们在程序内部自然也就可以完全读取了。
由于/proc/<pid>/mem的权限是只有自己可读,所以其他进程如果想要读取的话就必须要ptrace到这个进程。但是root是可以读到的,但是程序仍然必须要暂停才能读。直接读内存不太好(竞态),使用gcore命令可以稳定的将整个内存导出到文件。
内核后面增加的CONFIG_STRICT_DEVMEM和CONFIG_IO_STRICT_DEVMEM等特性逐渐的对/dev/mem文件的访问内存能力进行限制,所以新版的内核已经不是那么容易的访问内存了。
最早的elf攻击就是shellcode放到栈上,也正式因为如此,这种方法最先被防御。现在一般的栈都没有可执行权限,但是控制这个可执行权限的是elf文件本身的section,所以如果有elf文件的修改权限这也就不是问题。用gcc编译可以用-z execstack打开栈的执行权限,或者使用execstack的shell命令。
Gcc对c支持一个扩展,就是函数的嵌套定义。而这个定义是通过将嵌套的函数代码放在栈中执行的,这就要求这种栈是有可执行权限的。而如果代码中没有使用这个功能,栈的可执行权限就会开启,所以如果代码的安全性要求比较高,就不要使用嵌套函数。默认情况下,编译器都是在栈对应的section,例如GNU_STACK上关闭可执行权限的。如果对于这个文件有修改的权限就能打破这个封锁。
还有一个是编译器添加的保护,在栈之间加上空隙,这个空隙是没有映射内存的,如果这个空隙被访问了,那么就是segment fault。如此很多注入的shellcode就会导致程序崩溃,从而注入失败。或者是这个选项会加入gcc指定的字符,如果你修改了它,他执行的时候的检查函数(__stack_chk_failed)就会调用失败,导致程序退出。后面一种叫做stack canary。
return-to-libc 攻击是一种电脑安全攻击。这种攻击方式一般应用于缓冲区溢出中,其堆栈中的返回地址被替换为另一条指令的地址,并且堆栈的一部分被覆盖以提供其参数。这允许攻击者调用现有函数而无需注入恶意代码到程序中。 名叫libc的共享库提供了类UNIX操作系统中的C运行时支持。尽管攻击者可以让代码返回到任意位置,但绝大多数情况下的目标都是libc。这是因为libc总是会被链接到程序中,并且它提供了对攻击者而言一些相当有用的函数(如system()调用可以只附加一个参数即执行外部程序)。这即是尽管返回地址可以指向另一个完全不同的区域,但这种攻击仍被称为return-to-libc的原因。
这种攻击必须要知道system()系统调用的具体地址,而现在的libc一般是作为动态库加载到内存中,地址是随机的。所以一般需要首先探测这个地址。探测的方法是使用ld.so这个动态状态器。因为程序要执行必须要装载并解析动态库,而这个工作就是由ld.so完成的。所以这是一个现成的入口。
通常这种攻击方法实在栈上执行代码不可用时候才会使用的,现在一般的机器都在栈对应的section上设置了NX bit,这个位可以防止栈数据被执行,可以通过elf文件的GNU_STACK这个section的默认RW属性改为RWE属性来使得栈上可以执行代码,如果栈上可以执行代码,return to libc就显得多此一举了。
ASLR可以把动态库加载到随机的内存地址,这样就可以增加攻击者的调试难度。但是可执行文件自己在大部分情况却是有固定的开始执行地址的,这就给攻击者提供了方便。但是仍然有办法让这个地址随机,就是PIE(Position Independent Executable),这个可以把二进制编译成位置无关的文件,而是由内核来完成这个位置无关的随机化过程。所以这个特性需要内核支持。而还有一个需求是要求位置无关的,就是动态库和.o这种编译生成的中间代码,这几种所用的技术和思想都是类似的。
如果我们使用-fpic参数,就可以生成位置无关的动态库,而如果我们使用-fpie参数,就可以生成位置无关的可执行文件。这两者在使用上的差别很大,一个是用来给别人加载的,一个是用来直接执行的,但是这两者是技术上差别很小,有两个主要的差别:-fpic生成的文件加上一个PT_INTERP段和一些启动代码,就比较像-fpie生成位置无关进程。而两者甚至可以用同样的启动代码。-fpic由于用来生成动态链接库,所以符号不能直接解析到找到的符号,甚至可以允许找不到符号,动态库本身允许引用外部的库,所以在编译自己的时候不需要链接外部的库,只需要把它使用到的外部的库函数放入PLT表,链接的时候或者加载的时候解析就好,而可执行程序要求所有的符号立即解析,并且不允许有解析不了的符号。
上面的程序是非pie的,可以看到所有的地址都是绝对地址,第一个LOAD指明在二进制文件的开头到0x16f88字节要加载到内存的0x08048000地址,而二进制文件偏移的0x016f88往后的0x01543字节要加载到内存的0x0805ff88位置。所以,这是一个位置固定的可执行程序。
ASLR的主要目的是为了防止shellcode,他能够让编码在特定位置的shellcode无法被找到执行。要注意的是,ASLR是一个内核端技术,也就是堆栈等的内存乱序是由内核完成的。linux内核默认都是开启的这个技术,echo 0 > /proc/sys/kernel/randomize_va_space 就可以关掉,同样也是如此开启的。但是有很轻松的办法可以不需要提权就能绕过ASLR,setarch `uname -m` -R /bin/bash 这个命令将设置bash启动的时候不使用ASLR。
这个技术还有一个问题就是一个程序启动时候可能栈地址是随机的,但是当这个程序由其他的程序启动的时候,这个栈的地址就有了规律,例如使用execl接口调用启动这个程序。
Bat(binary Analysis Tool),BitBlaze,angr,CodeSonar(商用),bap,execstack, setarch
X64
到了x64时代,System ABI for x86_64被大量使用,而这种ABI使得前面的大部分攻击手法的难度都提高了很多,以往的寄存器利用或者栈利用都变得没那么容易。但是没那么容易是相对于x32发展了这么多年形成的成熟的技术套件而言的,随着时间的推移,x64的攻击也会逐渐成熟。没有绝对的防御,只有难度的提高。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!