
[TOC]
Golang学习笔记
这个学习笔记是最早在1.初,版本左右的时候写的,和当前最新的版本可能会有较大的差异.
因为成文比较早,文章里面又有很多自己的见解,有些东西当时理解的不太透彻可能写错了.已经对部分地方做出了补充和修改, 有遗漏的地方,海涵.
该笔记是根据<学习go语言>和<go语言实战>两本书看完之后一边敲代码一边写笔记记录的,毕竟纯粹的看和边看边写,感觉是不一样的..
后期也融合了我在慕课网学习的视频中的一些东西,基本上没什么难度,主要是了解一下go的特性和一些常用的包.
代码在这里goSpider代码,代码是后期写爬虫的时候写的,和笔记有点出入可以作为补充来看.
Golang常用命令
- go version 查看Golang版本号
- go help 查看go命令帮助
- go env 查看Golang环境变量配置,可以查看包括GOPATH,GOROOT等变量配置的配置.
- go run 编译并运行go程序
- go build 编译go程序
- go test 运行测试文件
- go fmt 格式化代码
- go clean 清理编译文件
- go get 下载包(被墙了)
- go install 编译并安装包和依赖
- go list 列出包
- go tool 运行golang提供的工具
- go bug 启动错误报告模式
安装Golang
GoPath的环境变
-
GOPATH 一般就是我们自己定义的系统环境变量路径
-
GOROOT 一般就是go语言自己设定的路径, 存放一些go语言自带的包之类的
Linux和Unix默认位置 ~/go下面
window下环境变量默认位置 %USERPROFIL%go
官方推荐: 所有项目和第三方库都放在同一个GOPATH下
也可以将不同的项目放在不同的GOPATH下面
go语言编译的时候回去到不同的GOPATH的路径中取寻找自己依赖的包
go语言自带的包会到自己原来自己的src目录中取找, 这个我们不用管
我们自己import 的包是到我们定义的GOPATH中取找
设置环境变量
export GOPATH=/Users/liuhao/go
一要用的话也可以把这个也设置进去
export PATH="$GOPATH/bin:$PATH"
一般go会默认设置环境变量,我们在编写代码时,使用import时,系统的库他回去自动找自己的$GOROOT库.
我们写的库的话,会到$GOPATH中取查找.
intellij IDEA自动清掉文件中错误的import
如果直接用goland这个IDE的话不用搞这些,格式化代码的时候会自动去掉
老版本idea是在系统设置中的 language & framework 里面的go 里面有一个On save的几个选项
新版本idea需要在plugin 安装 file watch 然后在 设置中的tools 中的file watch 中添加
我的添加目录案例: /Users/liuhao/go/bin/goimports 然后文件自动保存或手动保存时就会清掉无用的imports
- nothing 这个就不说了
- go fmt 只做格式化代码用
- go imports 不仅格式化代码, 而且还会对错误的Import进行清除和格式化
在这之前呢需要我们下载和安装这个第三方的库,否则你也没有goimports文件,自动保存的时候会暴一个Can't find goimports in GOPATH.....
使用go get 获取第三方库
go get 获取golang.org 是不行的貌似被墙了
要用gopm 来获取无法下载的包
安装gopm
go get -v github.com/gpmgo/gopm
这是我们回到~/go 中的我们自己的GOPATH的目录 ls一下
可以看到$GOPATH下的src下多了一个github.com 的目录,和我们的目录放在一起
~/go ⌚ 2:06:05
$ tree -L 2
.
├── bin
│ └── gopm
└── src
├── github.com
└── learnGo
这时候我们到~/go/bin/gopm 运行该文件
~/go/bin/gopm get -g -v -u golang.org/x/tools/cmd/goimports
这是安装成功之后, $GOPATH 下的src中会多一个golang.org的目录和我们的目录放在一起
~/go ⌚ 2:19:31
$ tree -L 2
.
├── bin
│ └── gopm
└── src
├── github.com
├── golang.org
└── learnGo
很显然我们在编码时的目录也是在src中运行的, bin是可执行文件
在~/go/bin 目录下执行 go install 安装goimports 安装之后会在~/go/bin目录下生成一个可执行的文件 ~/go/bin ⌚ 2:26:38 $ go install ../src/golang.org/x/tools/cmd/goimports
之后配置完之后, 我们在保存文件时,打码会自动按照标准尽心格式化, 无效的import也会被删除掉
- go get 命令演示
- 使用gopm 来获取无法下载的包
- go build来编译 我们编写的go文件,但是会建立在当前目录下
- go install 产生Pkg文件和可执行文件 将我们编写的go文件安装到~/go/bin下 使用go install ./... 安装当前目录下所有的go的包 go install 的时候一个package的main函数只能有1个,所以go语言的main函数都要在自己的一个目录下面
- go run 直接编译运行
~/go ⌚ 2:38:05
$ tree -L 2
.
├── bin
│ ├── goimports
│ └── gopm
├── pkg
│ └── darwin_amd64
└── src
├── github.com
├── golang.org
└── learnGo
- src 有很多第三方的包和我们的自己的项目放在里面, 每个人站一个目录
- pkg 和src是对应的是我们build出来的一些中间过程,我们不用去管他
- bin 就是我们生成的可执行文件
src
git repository 1
git repository 1
pkg
git repository 1
git repository 1
bin
可执行文件1,2,3,4...
官方在线环境(被墙了)
手动安装
如果手动安装的话需要在编译前手动设置GOPATH和GOROOT环境变量
- GOPATH为要保存的项目路径
- GOROOT为要下载包的保存路径
Mac下安装
brew install golang
- GOPATH会在家目录下的go目录下
- GOROOT会在/usr/lib/go-版本号
Ubuntu下安装
sudo apt install golang
- GOPATH会在家目录下的go目录下
- GOROOT会在/usr/local/Cellar/go/1.11.2/libexec下
第三方工具GVM
该方式安装支持单个操作系统安装多个go版本
测试是否安装成功
go doc hash
Golang基础
文件必备结构
package main //必须,独立文件必须叫main
import "fmt" //引入包,该包用于格式化IO
//主函数,独立文件必须有这个名字的函数,代码运行开始会首先调用该函数和C一样
func main() {
//打印字符串内容
fmt.Println("你好")
}
变量
注意
go定义的变量如果不使用会报错
import导入的包不使用也会报错
64位的整数和浮点数总是64位的,不管是不是64位的系统上.
变量类型全部都是独立的,混合使用变量赋值会引起编译器报错,即使int和int32这种也不行.
字符串一旦给变量赋值,就不能再修改了,go中字符串是不可变的.只能通过转换为rune数组类做
首字母大写的包全局变量为可被其他文件导入的变量公有变量,函数内的变量不存在这个概念
变量的定义和赋值
go语言变量定义时,类型在变量名的后面.
变量声明在函数外部时必须使用var来定义,在函数内可以通过var或:=声明同时赋值(函数外不能使用:=).
通过:=形式定义一个变量时可以不设置类型,不规定类型时为不确定类型.系统自动通过变量的值来推类型.
当定义了一个变量不设置值,他的默认赋值为其类型的默认值.意味着int为0,string为空字符串.
int类型 赋值可以使用8进制,16进制或者科学计数法:077,0xFF,1e3或者6.022e23这些都是合法的.
变量大写
var age int
var name string
age = 20
name = "json"
一般不需要用分号分割,但是如果想把多个写在一行就需要用分号分割.
var age int; var name string;
age = 20
name = "json"
在go语言中,变量声明和赋值时两个过程,但是也可以写在一起.
var age int = 20
var name string = "json"
在函数内可以,使用短标签 := 进行定义变量,但是在后面赋值时不可再用 := 只能用=
这种方式定义的变量的类型, 是由变量的值推演出来的.
age :=20 //int类型
name = "json" //string类型
多个变量可以成组声明,const和import同样也可以这样.
var (
age int
name string
)
有相同类型的多个变量可以在一行内同时声明
var age, height int
age = 20
height = 180
//也可以使用平行赋值
age, height := 20,180
特殊变量名"_"(下划线)
一个特殊的变量名是_(下划线),任何赋值给他的值都会被丢去
比如下面,将180赋值给height将20丢弃
这种形式,在调用函数时非常有用,比如某个函数可以返回多个函数.
用变量接收的时候,加入哪个不想要的话,就可以通过这种方式来丢弃
因为go中的变量如果声明而不使用的话会报错
_, height := 20,180
比如下面这里声明了但是不使用,编译的时候就会报错
package main
func main(){
var i int
}
内建函数
go预定了少量的函数,无需引入任何包就可以使用它们.
- close 用于关闭channel通信
- new 用于各种类型创建时的内存分配
- panic 用于异常处理时,抛出错误
- recover 用于异常处理时,接收错误
- delete 用于在map中删除实例
- make 用于内建类型(map,slice,channel)创建时的内存分配
- len 用于返回字符串,slice,数组的长度
- cap 用于获取数组和slice的cap长度
- append 用于追加slice
- copy 用于复制slice
- print 底层打印函数,不带换行符
- println 底层打印函数,打印带换行符
- complex 处理复数
- real 处理复数
- imag 处理复数
GoLang关键字(保留字)
- break
- case
- chan
- const 定义常量
- continue
- default
- func 定义函数和方法
- defer
- go 并行操作(执行goroutine)
- else
- goto 跳转到当前函数内定义的标签
- fallthrough
- if
- for
- import
- interface 定义接口
- map
- package
- range
- return 从函数中返回
- select 选择不同类型的通讯
- struct 用于抽象数据类型
- switch
- type 类型定义
- var 定义变量
内建数据类型
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型<br/>布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 2 | 数字类型<br/>整型 int 和浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 3 | 字符串类型:<br/>字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 4 | 派生类型:<br/>包括:<br/>(a) 指针类型(Pointer)<br/>(b) 数组类型<br/>(c) 结构化类型(struct)<br/>(d) Channel 类型<br/>(e) 函数类型<br/>(f) 切片类型 |
| <br/>(g) 接口类型(interface)<br/>(h) Map 类型 |
布尔类型 bool
这个没什么好说的,和其他语言一样.
布尔类型标识由预定义的常量true和false代表的布尔判定值.
布尔类型是bool.
数字类型
| 序号 | 类型和描述 |
|---|---|
| 整型 | 整型型 |
| 1 | uint8<br/>无符号 8 位整型 (0 到 255) |
| 2 | uint16<br/>无符号 16 位整型 (0 到 65535) |
| 3 | uint32<br/>无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64<br/>无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8<br/>有符号 8 位整型 (-128 到 127) |
| 6 | int16<br/>有符号 16 位整型 (-32768 到 32767) |
| 7 | int32<br/>有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64<br/>有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
| 浮点型 | 浮点型 |
| 1 | float32<br/>IEEE-754 32位浮点型数 |
| 2 | float64<br/>IEEE-754 64位浮点型数 |
| 3 | complex64<br/>32 位实数和虚数 |
| 4 | complex128<br/>64 位实数和虚数 |
| 其他数字类型 | 其他数字类型 |
| 1 | byte<br/>类似 uint8 |
| 2 | rune<br/>类似 int32 |
| 3 | uint<br/>32 或 64 位 |
| 4 | int<br/>与 uint 一样大小 |
| 5 | uintptr<br/>无符号整型,用于存放一个指针 |
int 类型表示不规定长度,会根据你的硬件类型决定适当的长度
这意味着在32硬件上,是32位的.在64位硬件是64位的.
注意 int是32或64位之一,不会定义成其他值.uint情况相同(带u代表无符号)
如果想要明确长度,你可以使用int32或者uint32等等.
完整的整数类型列表(有符号和无符号,无符号带u)是:
- int8
- int16
- int32
- int64
- byte (是uint8的别名)
- uint8
- uint16
- uint32
- uint64
浮点类型的值有:
- float32
- float64
- 没有float类型,只有上面这两种
64位的整数和浮点数总是64位的,不管是不是64位的系统上.
需要注意的时这些类型全部都是独立的
并且混合使用这些类型向变量赋值会引起编译器报错
package main
func main() {
var a int
var b int32
a = 15
b = a + a
b = b + 5
}
//执行结果
//./test1.go:8:4: cannot use a + a (type int) as type int32 in assignment
赋值可以使用8进制,16进制或者科学计数法:077,0xFF,1e3或者6.022e23这些都是合法的.
常量 constant
const age = 20生成age这个常量.也可以使用iota生成枚举类型.
首字母大写的包全局常量为可被其他文件导入的公有常量,函数内的常量不存在这个概念
常量在go中,也就是constant. 在编译时被创建,只能是数字,字符串或布尔值.
常量的数值可以作为各种类型使用,所以下面计算的时候需要float时可以自动转换
常量可以规定类型也可以不规定类型,不规定类型时为不确定类型
常量定义后不使用,编译时不会报错
const age int = 20
const name string = "json"
const one, two = 1,2
const (
cpp = 0
java = 1
python = 2
golang = 3
)
枚举 constant
go中的枚举类型没有专门的定义范式
只能通过定义常量时通过iota关键字定义的形式做到的.
通过iota声明的枚举类型,默认情况下从上到下自动递增.
第一个iota表示未0,因此a等于0,当iota再次在新的一行使用时,它的值增加了1,因此b的值为1
const (
a = iota //默认为0
b = iota // 默认为1
)
也可以通过下面这样,省略重复的=iota:
const (
a = iota //默认为0
b //默认追加一个iota,值为1
)
如果需要,也可以明确指定常量的类型:
const (
a = 0 //根据go规则,未定义类型则从值来推类型,所以该类型为int
b string = "0" //string类型
)
枚举类型也可以设置步长
const (
a = iota * 10
b
c
d
)
//结果为: 0,10,20,30
枚举类型也可以参与运算,作为自增值的种子
const (
a = 1 << iota * 10
b
c
d
e
f
)
//结果为10,20,40,80,160,320
字符串 string
字符串在go中是utf-8的由双引号(")包裹的字符序列.
如果使用单引号(')包裹则标识一个字符(utf-8编码),这在go中不是string
一旦给变量赋值,字符串就不能再修改了,go中字符串是不可变的.
从头C来的开发,下面的情况在go中是非法的:
var s string = "hello"
s[0] = 'c' //修改第一个字符为c,这里会报错
在go中要修改字符,需要这样做
s :="hello"
c := []rune(s) //将s转换为rune数组
c[0] = 'c' //修改数组的第一个元素
s2 := string(c) //创建新的字符串s2保存修改
fmt.Printf("%sn", s2) //打印结果
多行字符串,通过加号(+)来做字符串拼接,该方式可以解析转义字符,比如n换行
这种方式,不管有多少行,输出结果时都是在同一行
s :="Strating part" + //加号只能在这里否则会出错
"Ending part"
多行字符,通过反引号(`)直接写多行字符,该方式不会解析转义字符,比如n就不会换行
处于多行时会自动换行.
s := `Starting part
Ending part`
rune
这里的rune就是go的char
go语言中已经没有char了,只有rune
因为char里只有1字节,在多国语言时有很多坑
在utf-8里面有很多字符是3字节,因为GO采用了4字节的int32来做的rune
这个byte是8位的int, rune是32位的int 他们和整数都是可以混用的
文档里说的, 他们和整数来说就是一个别名
rune 是int32的别名, 用utf-8进行编码.
这个类型一般在,遍历字符串中的字符时使用
可以以循环每个字节(仅仅在使用US ASCII编码时与字符等价,但是go中没有这种编码).
因此为了获得实际的字符,需要使用rune类型
复数
go原生支持复数,他的变量类型是complex128(64位虚数部分).
如果需要小一些,还有complex64和32位的虚数部分.
使用复数的一个例子:
var c complex64 = 5+5i;
fmt.Printf("value is : %v", c)
//记过为:(5+5i)
错误 error
go有为了错误而存在的内建类型, error
下面定义了err为一个error类型,err的值是nil
var err error
数组 array
array的定义由 [n]<type> 方式定义的, n代表array长度,<type>标识存储内容的类型.
对array的元素赋值火索引是由方括号完成的:
var arr [10]int
arr[0] = 42
arr[1] = 13
println("this first element value %dn", arr[0])
像是var arr=[10]int 这样的数组类型有固定的大小.
大小是类型的一部分, 由于不同的大小是不同的类型,因此数组不能改变大小.
数组同样是值类型的,当一个数组赋值给另一个数组,会复制所有的元素.
尤其是当向函数内传递一个数组时,他会获得一个数组的副本,而不是数组的指针.
可以这样声明一个简单的数组var a[3]int,如果不用默认值零来初始化塔,
则用复合声明a:=[3]int{1,2,3}也可以简写为 a :=[...]int{1,2,3}
go会自动统计元素的个数,注意所有项目必须都制定. 因为如果用多维数组,有一些内容必须录入
a := [2][2]int{[2]int{1,2}, [2]int{3,4}}
类似于
a := [2][2]int{[...]int{1,2},[...]int{3,4}}
之前版本当声明一个array时,必须在方括号内输入写内容,数组或者三个点
不过新版本的array,slice,map的复合声明变得更加简单.
使用复合声明的array,slice,map,元素复合声明的类型与外部一致就可以省略
上面的例子就可以改为
a := [2][2]int{{1,2},[3,4]}
切片 slice
slice和array接近, 但是在新的元素加入的时候可以增加长度.
slice总是指向底层的一个array. slice是一个指向array的指针,这是其与array不同的地方
slice是引用类型, 这意味着当赋值某个slice到另外一个变量,两个引用会指向同一个array.
例如一个函数需要一个slice参数,在其内对slice元素的修改也会提现在函数调用者中,折合传递底层的array指针类似.
通过: sl := make([]int, 10) 创建了一个保存有10个元素的slice.
需要注意的时底层的array并无不同.
slice总是与一个固定长度的array成对出现,该array影响slice的长度和容量.
如下,首先创建了m个元素长度的array, 元素类型intvar array[m]int
然后对这个array创建slice: slice :=array[0:n]
然后现在有:
len(slice) ==n
cap(slice) ==m
len(array) == cap(array)==m
array和slice的对比图
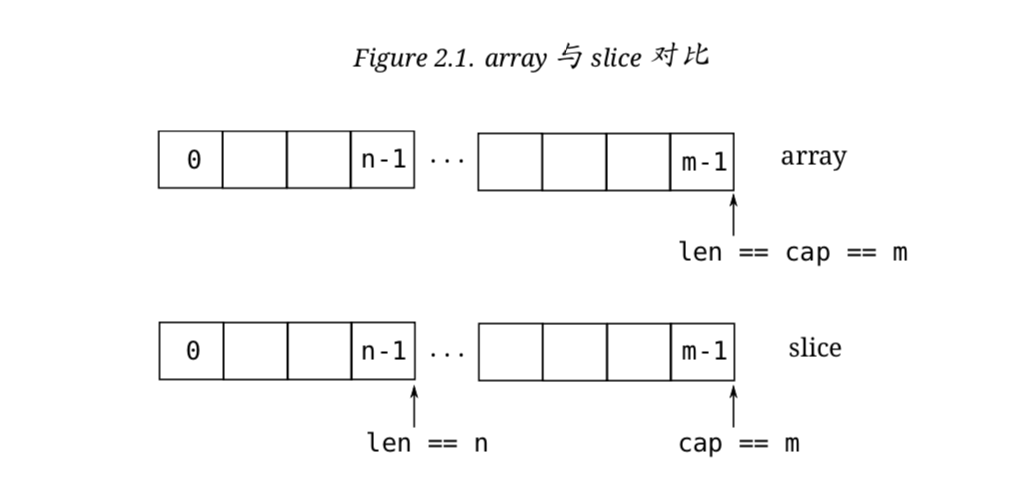
给定一个array或者其他slice,一个新的的slice通过a[I:J]的方式创建.
这会创建一个新的slice,指向变量a,从需要I开始截取到需要J之前.铲毒为J-I.
//array[n:m]从array创建了一个slice,具有元素n到m-1
a :=[...]int{1, 2, 3, 4, 5} //定义一个具有5个元素的array
s1 := a[2:4] //截取下标2-3的元素,创建slice,包含元素3,4
s2 := a[1:5] //截取下标1-4的元素,创建slice, 包含元素2,3,4,5
s3 := a[:] //用array中所有的元素创建slice,这是a[0:len(a)]的简化写法
s4 := a[:4] //截取0-3,创建slice,这是a[0:4]的简化写法,得到1,2,3,4
s5 := s2[:] //从slice s2截取所有元素,创建新的slice,注意s5仍然指向array a
下面代码,可见slice一个数组,对一个指定下标进行赋值时超过了数组范围
package main
func main(){
//声明一个长度为100 的数组,值为int类型
var array [100]int
//截取该数组
slice := array[0:99]
slice[98] = 'a' //成功赋值
slice[99] = 'b' //这里会提示,index out of range
}
如果想要扩展slice,可以用append和copy.
- append 想slice追加新的值,并且返回追加后的新的与原来类型相同的slice.
- 如果该slice没有足够的容量存储追加的值,append分配一个足够大的新的slice来存放原有的slice的元素和追加的值.
- 因此返回的slice可能会指向不同底层的array.
s0 := []int{0,0}
//注意下下面这三点追加方式
s1 := append(s0, 2) //追加一个元素,s1 == []int{0,0,2}
s2 := append(s1, 3, 4, 7) //追加多个元素,s2 == []int{0,0,2,3,5,7}
s3 := append(s2, s0...) //追加一个slice, s3 ==[]int{0,0,2,3,5,7,0,0}
函数copy从源slice src复制元素到目标dst,并且返回复制的元素的个数.
源和目标可能会重复,复制的数量是len(src)和len(dst)中的最小值
//这时候这里还是数组,到下面开始剪切的时候才是slice
var a =[...]int{0,1,2,3,4,5,6,7}
//创建一个长度为6的slice
var s = make([]int,6)
n1 := copy(s,a[0:]) //n1 ==6, s== []int{0,1,2,3,4,5}
n2 := copy(s,s[2:]) //n2 ==4, s== []int{2,3,4,5,4,5}
map
许多语言都有类似的类型.go中有map类型.
map可以认为是一个用字符串做索引的数组(在最简单的形式下)
一般定义map的方法是 map[<from type>]<to type>
下面定义了map类型, 用于将string(英文月份的缩写)转换为int-那个月有几天.
monthdays := map[string]int{
"Jan":31,"Feb":28,"Mar":31,
"Apr":30,"May":31,"Jun":30,
"Jul":31,"Aug":31,"Sep":30,
"Oct":31,"Nov":30,"Dec":31, //这里结尾必须有一个逗号
}
注意, 当只需要声明一个map的时候, 使用make的形式:monthdays := make(map[steing]int)
当在map中索引(搜索)时,使用方括号取值,例如打印12月有几天: fmt.Printf("%dn", monthdays["Dec"])
当对array,slice,string或者map循环遍历时,可以用range,每次调用他都会返回一盒键和对应的值
year :=0
for _,days :=range monthdays{ //这里的键没有用,因此使用_不赋值
year +=days
}
fmt.Printf("Numbers of days in a year :%dn",year)
向map增加元素,可以这么做
monthdays["Undecim"] = 30 //添加一个月
monthdays["Feb"] = 29 //闰年时重写这个元素
检查这个元素是否存在,可以这样
var value int
var persent bool
value,present = monthdays["Jan"] //如果存在该下标,present值为true,否则为false
v,ok := monthdays["Jan"] //这样写更接近go的方式,如果存在ok为true否则为false
也可以通过下标从map中移除元素
通常来说语句delete(m,x)会删除map中由m[x]建立的实例
delete(monthdays,"Mar") //删除下标为Mar的元素
运算符
算术运算符
下表列出了所有Go语言的算术运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B |
| - | 相减 | A - B |
| * | 相乘 | A * B |
| / | 相除 | B / A |
| % | 求余 | B % A |
| ++ | 自增 | A++ |
| -- | 自减 | A-- |
关系运算符
下表列出了所有Go语言的关系运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
逻辑运算符
下表列出了所有Go语言的逻辑运算符。假定 A 值为 True,B 值为 False。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 |
位运算符
位运算符对整数在内存中的二进制位进行操作。
下表列出了位运算符 &, |, 和 ^ 的计算方式:
- 第一行: 当p=0,q=0时p & q=0,p | q=0, p ^ q=0;
- 第二行: 当p=0,q=1时p & q=0,p | q=1, p ^ q=1;
- .......以此类推
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与,同时为“1”,结果才为“1”,否则为0。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或 。 参加运算的两个对象只要有一个为1,其值为1。 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。<br/>可以作为二元运算符,也可以作为一元运算符, 作一元运算符表示是按位取反。<br/>作二元运算符就是异或,相同为0,不相同为1 。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。<br/> 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>"是双目运算符。右移n位就是除以2的n次方。<br/> 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
赋值运算符
下表列出了所有Go语言的赋值运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| = | 按位或后赋值 | C |
其他运算符
下表列出了Go语言的其他运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 7 | ^ ! |
| 6 | * / % << >> & &^ |
| 5 | + - | ^ |
| 4 | == != < <= >= > |
| 3 | <- |
| 2 | && |
| 1 | || |
结构控制
go语言的结构控制语句很少,没有do while或者while循环
只有:
- if 条件判断
- for 循环
- switch 也可以向for那样有初始值
- select 类型选择和多路通讯转接器
if语句
基本上就是这么个写法, go语言强制要求大括号,并且要求在同一行.
n := 0
if n > 0 {
return 1
} else if n < 0{
return 2
} else {
return 3
}
同时if和switch也支持初始化语句,通常用来设置一个局部变量
接收处理结果同时进行判断结果
//如首先接收os.Create创建结果,同时判断结果返回的错误是否为nil
if handle, err := os.Create("./nihao"); err == nil {
print("文件创建成功n")
//同样接收handle.Write文件写入结果,同时判断返回的错误是否为nil
if _, err := handle.Write([]byte("11111")); err == nil {
print("文件内容写入成功n")
} else {
print("文件内容写入失败n")
}
handle.Close()
} else {
print("文件创建失败n")
handle.Close()
}
上面初始化语句和使用逻辑运算符的性质一样的
//创建文件, 接收创建文件结果
handle, err := os.Create("./nihao")
//判断创建结果
if err == nil {
print("文件创建成功n")
//写入内容, 接收写入内容结果
_, err := handle.Write([]byte("11111"))
//判断写入结果
if err == nil {
print("文件内容写入成功n")
} else {
print("文件内容写入失败n")
}
} else {
print("文件创建失败n")
}
handle.Close()
也可以像通常那样使用逻辑运算符
if true && true {
print("true")
}
if !false {
print("false")
}
goto语句
谨慎使用goto语句
用goto跳转到当前函数(必须是当前函数)内定义的标签,标签名大小写敏感
//死循环函数
func myFunc() {
i := 0
Here: //标签名随意定
print(i)
i++
goto Here //跳转到该标签处继续执行
}
for语句
go语言的for循环有三种形式,只有其中一种要使用分号.
- 和C的for循环一样,中间要使用分号隔开
for init; coditoin; post{}
- 和C的while一样
for condition{}
- 和C的for()一样是死循环
for{}
简单的for循环,短声明
sum :=0
for i :=0; i < 10; i++ {
sum +=i
}
go没有逗号表达式,而++和-是语句而不是表达式
如果想在for中执行多个变量,应当使用平行赋值
//for循环带平行赋值
for i, j := 0, len(a) - 1; i < j; i, j = i + 1, j - 1 {
//这里也是平行赋值
a[i], a[j] = a[j],a[i]
}
brek退出循环和continue跳过循环
for i:=0; i<10; i++{
if i>5{
break//终止该循环
}
print(i)
}
循环嵌套时,可以在循环时指定标签.break指定标签决定哪个循环被终止
标签和for循环处不能有空格
//这里的标签和for循环处不能有空格
J:for j:=0; j<5; j++{
for i :=0; i<10; i++{
if i>5 {
break J;//退出J标签处的那个循环j的循环,而不是循环i的这个循环
}
print(i);
}
}
利用continue 让循环进入下一个迭代,而略过剩下的所有代码.
for i:=0; i<10;i++{
if i>5{
continue
}
print(i)
}
range关键字
关键字range可用于循环slice,array,string,map,channel.
range是一个迭代器,当被调用时,从他循环的内容中返回一个键值对,range根据不同的内容,返回不同的东西.
对slice或者array循环时, range返回序号作为键,这个需要对应的内容作为值.
list := []string{"a","b","c","d","e","f"}
for k, v := range list{
println(k)
println(v)
}
在字符串string上直接使用range,这样字符串也会被打算成独立的Unicode字符串
并且起始位置按照UTF-8解析
//遍历这三个字符串
for pos, char := range "aΦx" {
fmt.Printf("character '%c' starts at byte position %dn", char, pos)
}
//执行结果
//GOROOT=/usr/local/go #gosetup
//character 'a' starts at byte position 0
//character 'Φ' starts at byte position 1
//character 'x' starts at byte position 3
switch语句
go语言的switch case命中之后会默认自动进行break
switch 不需要加break, 如果不想break反而要用 fallthrough
switch 可以通过default设置一旦条件全部匹配失败后的默认值
case 可以没有case体
表达式不必是常量或整数,执行过程从上到下,直到找到匹配的项.
switch 后面可以没有表达式,只要在case中定义了就行.如果没有表达式,他会匹配true,相当于if true自动进入循环.
这里用switch方式来编写if-else if-else的判断序列
//注意这里传参的时候要保持类型一致,否则无法运算
func unhex(c byte) byte {
switch {
case '0' <= c && c <= '9':
return c - '0'
case 'a' <= c && c <= 'f':
return c - 'a' + 10
case 'A' <= c && c <= 'F':
return c - 'A' + 10
default:
println("no case")
}
return 0
}
switch条件被命中后不会继续向下运行,而是自动退出.下面的case 1就不会执行
i :=0
switch i{
case 0: //这里是空的case体,但是0匹配到了i
case 1:
//后面的不会被执行
println("case 1")
default:
println("default")
}
想要匹配失败后继续向下的话,需要用fallthrough
i :=0
switch i{
case 0: fallthrough //这里是空case体,但是0匹配到了i
case 1:
//这里会被执行
println("case 1");
default:
println("default")
}
case可以是多个项,使用逗号分隔. 判断参数是否在罗列的多个项中
shouldEscape('=')
//判断传进来的符号是否在指定的列表中
func shouldEscape(c byte) bool{
switch c{
//这里就类似于,if c==' ' || c=='?'..........
case ' ', '?','&','=','#','+':
return true
}
return false
}
使用switch对字节数组进行比较
//声明参数,调用函数
var a = []byte{1,2,3,4,5}
var b = []byte{2,3,4,5,6}
//或者使用uint8,主要是考察一下byte实际上就是uint8
//var a = []uint8{1}
//var b = []uint8{2}
compare(a, b)
//比较返回两个字符数组字典书序先后的整数
//如果 a ==b 返回0, 如果a,b返回-1, 如果a>b 返回+1
func compare(a, b []byte) int{
for i :=0; i<len(a) && i<len(b); i++{
switch{
case a[i] > b[i]:
return 1
case a[i] < b[i]:
return -1
}
}
//长度不同则不相等
switch {
case len(a) < len(b):
return -1
case len(a) > len(b):
return 1
}
return 0 //字符串相等
}
函数
函数是构建 Go 程序的基础部件;所遇有趣的事情都是在它其中发生的。
首字母大写的包全局函数(包括type 和 func),相当于公有函数,可被其他文件导入
函数定义
自定义一个新的类型(类似其他语言的对象,但是go的这个用法更加的丰富)
type myType int
定义一个自定义函数
func (p mytype) funcname(q int) (r, s int) { return 0,0 }
- func 关键字,用于定义一个自定义函数
- (p mytype) 函数定义可以基于一个特定类型(自定义或预定义),这类函数成为method.该部分成为receiver而他是可选的
- funcname 是自定义函数的名称
- q int 自定义函数接收的参数和参数类型
- (r, s int) 指定自定义函数的返回值和返回类型,go可以返回多个值,如果不想对返回的参数命名,只需要提供返回类型,如:(int,int).如果只有一个返回值可以省略小括号.如果函数是一个子过程,并且没有任何返回值,可以不定义这个东西
- { return 0,0 } 这是函数体,注意return是一个语句
这里有两个例子, 一个函数没有返回值, 一个只是简单的将输入返回
//没有返回值
func subroutine(in int){
return
}
//返回输入的内容
func identity(in int)int{
reutn in
}
函数可以随意安排定义的顺序, 编译器会在执行前扫描每个文件.
所以函数原型在go中都是国企的旧物.go不允许函数嵌套,不过我们可以利用匿名函数实现他
递归函数和其他语言方式一样
func rec(i int){
if i== 10{
return
}
re(i+1)
//函数在这里,打印的结果是反的,在递归调用前一行打印才是正的
fmt.Printf("%d ", i)
}
//打印结果: 9 8 7 6 5 4 3 2 1 0
函数作用域
在go语言中,定义在函数外的变量都是全局的,实际上也只是包内全局而已.
定义在函数内部的变量, 对于函数来说是局部的.
一个局部变量和一个全局变量,在函数运行时,局部变量会覆盖全局变量.
package main
var a =6 //全局变量
func main(){
p()//输出结果为, 全局变量的值 6
q()//调用函数,对全局变量的值进行覆盖性修改
p()//输出结果为, 局部变量的值 5
}
func p(){
println(a) //仅仅打印变量
}
func q(){
a :=5 //局部变量,该函数被调用时变量a会被重新赋值
println(a)
}
//执行结果为 656
当函数调用函数时的变量作用域,局部变量的作用域仅限于变量定义的函数内
注意下面这个调用方式和上面的不同之处在于,上面的是逐个调用函数,下面这个是函数内调用函数
package main
var a int
func main(){
a = 5
println(a) //打印5,因为初始内容是5,这里也是第一次打印
f()
}
func f(){
a := 6
println(a)
g()
}
func g(){
println(a)
}
//输出内容将是 565,因为局部变量仅在执行定义的函数时才有效
函数返回多个值
go的函数和方法可以返回过个值
比如,Write函数返回一个计数值和一个错误,因为说可能由于设备异常,我们传入的字节,并不都被成功写入文件了.
OS包中的*File.Write是这样声明的
func (file *File) Write(b []byte) (n int, err error)
如文档所说的那样, 他返回写入的字节数和非nil的error,这是Go中常见的方式.
类似的方法,避免了传递指针模拟引用参数来返回值.
例如,从字节数组的指定位上取得数值,返回这个值和下一个位置.
func nextInt(b []byte, i int)(int, int){
n := 0
for ; i < len(b); i++{
n = n*10 + int(b[i]) - '0'
}
return n, i
}
//我们可以在输入的数组中扫描数字,同时调用该函数
a :=[]byte{'1','2','3','4'}
var n int
for i := 0; i < len(a); {
n,i = nextInt(a,i)
println(n)
}
没有元组作为原生类型,多返回值可能是最佳选择,我们可以精确的返回希望的值,而无需重载域空间到特定的错误信号上.
命名返回值
go语言的函数返回值或者结果参数可以指定一个名字,并且像原始的变量那样使用,就像输入参数那样.
如果对其命名,在函数开始时,他们会用其类型默认值进行初始化.
如果函数在return时没有指定变量,仅仅只是return了.那么和返回参数重名的变量的最后一次赋值将被返回.
函数定义, 函数名在前, 返回类型在后 可以传入一个匿名函数,可传入可变参数列表,可以返回多个参数,没有默认参数,可选参数,函数重载,操作符重载,
参数用逗号分隔, 参数也是一样名在前,类型在后 这里发红是因为在别的文件中也声明了该名字的函数
func nextInt(b []byte,pos int)(value, nextPos int){/* ... */}
由于命名结果会被初始化并关联于无修饰的return, 他们可以非常简单并且清晰(我觉得不好读).
我觉得,返回多个值, 多返回值不要乱用, 一般就是返回一个值,再返回一个错误信息
//函数定义时,返回值参数n,err都是有类型默认值的.n是0,err是nil
func ReadFull(r Reader, buf []byte) (n int, err error){
for len(buf) >0 && err ==nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:len(buf)]
}
//这里修饰return的话会直接返回名字叫n和err的变量的最后一次赋值的内容
return
}
在返回多个值的情况下, 给返回值定义名称,但是在起名字的, 需要好好想想, 要不然散在函数体中, 搞不清哪里调用,会很难读
func div(a, b int) (q, r int) {
//返回两个值的时候, 如果只想用一个的话, 另一个值可以用 _ 来做代表,意思就是不接受这个值
//里面不动,但是外面的返回值也需要用名字来接一下, 这里的q,r只是在函数体中的名字,在外面接的时候可以随意定,叫a,b也无所谓,但是最好保持一致
//这里还可以这样写
//return a / b, a % b
//但是最好这样写, 因为已经返回值的名称了定义了, 但是一旦函数体比较长, 这样写就会很难读, 比较长的时候, 最好就用上面那种
q = a / b
r = a % b
return
}
延迟代码 defer
在defer关键字同一行后面的代码,将会在函数调用结束时才执行
多个defer时遵循先进后出的原则
假设有一个函数,打开文件并且对其进行读写.在这样的函数中,经常有会可能会遇到错误的地方需要提前返回的.按照普通方式的话,就需要关闭正在每个运行接触的地方, 都关闭一次文件描述符.
这经常会导致产生下面的代码:
func ReadWrite() bool{
file.Open("file")
//做点什么
if failureX {
file.Close()//关闭文件描述符
return false
}
if failureY{
file.Close()//关闭文件描述符
return false
}
file.Close()//关闭文件描述符
return true
}
上面的代码因为要执行close操作,所以多了很多重复的代码.
go有defer语句,在defer后制定的函数会在函数退出前调用.
上面的代码可以被改下成下面这样,把Close对应的放置于Open后
func ReadWrite() bool{
file.Open("file")
defer file.Close()//关闭文件描述符
//做点什么
if failureX{
return false //如果在这里结束,会自动调用Close
}
if failureY{
return false //如果在这里结束,会自动调用Close
}
return true //执行完毕,会自动运行Close
}
可以将多个函数放入延迟列表中,会按照先进后出的顺序执行
for i :=0; i<5; i++{
//这里相当于定义了五个defaer,分别是defer println(1),defer println(2).....
defer println(i)
}
//输出结果为: 4 3 2 1 0
利用defer甚至可以修改返回值
通过在被调动函数前定义defer,让函数最后执行.我们再return.
//这里的这个defer 会导致函数延迟执行
defer func(n int){
//todo
}(5) //这里的括号是必须要有的
func f() (ret int){ //ret 初始化为0
defer func(){
ret++ //ret增加为1
}()//这里的括号是必须的
return 0 //返回值是1而不是0
}
可变参数
接收可变参数的函数是有着不定数量的参数,也就是说可以传入任意多个的参数
可变参数的变量,在函数内是一个和参数规定类型一样的slice.
//arg...int 告诉go这个函数接收任意数量的参数,但是必须是int型的
func myfunc(arg ...int){
//在函数中,变量arg是一个int类型的slice
for _, n :=range arg{
println(n)
}
}
如果不指定可变参数的类型,默认是空的接口interface{}
假设有另一个可变参数的函数叫myfunc2,下面举例如何向其他函数传递参数
func myfunc(arg ...int){
myfunc2(arg...) //按照原样传递,不动传进来的参数
myfunc2(arg[:2]...) //剪切传进来的参数,再做传递
}
函数作为值
就像其他在GO中的其他东西一样,函数也是值而已.
函数可以这样赋值给变量
func main(){
a := func(){ //定义一个没有函数名的函数(匿名函数),赋值给变量a
println("nihao")
} //这里没有()
a()//调用函数
}
如果使用fmt.Printf("%Tn", a)打印变量a的类型,可以发现输出结果会是func()
函数作为值,也会被用在其他一些地方, 例如map,
var funcMap = map[int]func() int{
1: func() int{return 10},
2: func() int{return 20},
3: func() int{return 30},
}
匿名函数和闭包
在定义匿名函数时,就会即执行,不需要调用,不过可以传参
package main
func main(){
fun := func (p1 int,p2 int) int{
return p1 + p2
}(10,20) //
println(fun)
}
将匿名函数赋值给一个变量,再通过变量来调用匿名函数
package main
func main(){
fun := func(n1 int, n2 int) int{
return n1 + n2
}
println(fun(10,20))
}
全局匿名函数,是将匿名函数赋给一个全局变量,那么这个匿名函数在当前程序里都调用用.
package main
var (
fun = func(n1 int,n2 int) int{
return n1+n2
}
)
func main(){
println(fun(10,20))
}
闭包是指在创建时封装周围状态的函数。即使闭包所在的环境不存在了,闭包中封装的状态依然存在。
GO语言的匿名函数就是闭包,以下是《GO语言编程》中对闭包的解释
基本概念
闭包是可以包含自由(未绑定到特定对象)变量的代码块,这些变量不在这个代码块内或者
任何全局上下文中定义,而是在定义代码块的环境中定义。要执行的代码块(由于自由变量包含
在代码块中,所以这些自由变量以及它们引用的对象没有被释放)为自由变量提供绑定的计算环
境(作用域)。
闭包的价值
闭包的价值在于可以作为函数对象或者匿名函数,对于类型系统而言,这意味着不仅要表示
数据还要表示代码。支持闭包的多数语言都将函数作为第一级对象,就是说这些函数可以存储到
变量中作为参数传递给其他函数,最重要的是能够被函数动态创建和返回。
闭包和匿名函数一般一起用,可以使用闭包来访问函数中的局部变量(被访问操作的变量为指针指向关系,操作的是同一个局部变量)如:
package main
func closure(x int) (func(), func(int)) {
fmt.Printf("初始值x为:%d,内存地址:%pn", x, &x)
f1 := func() {
x = x + 5
fmt.Printf("x+5:%d,内存地址:%pn", x, &x)
}
f2 := func(y int) {
x = x + y
fmt.Printf("x+%d:%d,内存地址:%pn", y, x, &x)
}
return f1, f2
}
func main() {
func1, func2 := closure(10)
func1()
func2(10)
func2(20)
}
回调函数
当函数作为值时,就可以很容易的传递到其他函数里,然后可以作为回调函数.
func prointit(x int){ //函数无返回值
fmt.Print("%vn", x) //仅仅打印
}
这个函数的标识是func printit(int), 或者没有函数名的函数:func(int)
创建新的函数使用这个作为回调,需要用到这个标识
//该函数的意思是,变量y必须是int,变量f必须是一个函数
func callback(y int, f func(int)){ //变量f将会保存传入的函数
f(y) //调用回调函数f,传入变量y
}
完整的回调函数案例
//go语言是一个函数式编程语言, 他的函数中可以套函数 作为复合函数(回调函数)
//主要流程, 我们把收到的a,b参数放到op()中执行 然后返回一个Int
//apply中的函数, 我们把收到的两个a,b参数放在第一个函数op()中执行,op()返回的是一个int
//细节 ope()接收两个参数, 返回一个int
//applay 接收两个参数a,b返回一个int
func apply(op func(int, int) int, a, b int) int {
//输出函数调用名称
fmt.Printf("Calling %s with %d, %d n", runtime.FuncForPC(reflect.ValueOf(op).Pointer()).Name(), a, b)
//将apply接收到的参数放到op()中执行
return op(a, b)
}
//通过传入一个匿名函数的方式来调用函数
fmt.Println(apply(func(a int, b int) int {
return int(math.Pow(float64(a), float64(b)))
}, 3, 4))
恐慌(Panic)和恢复(Recover)
go没有其他语言那样的异常处理机制,不能抛出异常.
但是作为替代,它使用了恐慌和回复(panic-and-recover)机制.
这东西应该作为最后的手段被使用,我们的代码中应该没有,或者很少用这种东西.
Panic
是个一个内建函数,可以立即中断原有的程序执行.
比如当函数F调用panic(),函数F的执行被中断,但是F中的defer(延迟函数)还是会正常执行,然后F返回到调用他的地方.
在调用他的地方,F的行为就像调用了panic()一样.这一过程继续向上返回并执行每一个defer,直到程序崩溃时的所有goroutine返回
恐慌可以直接通过panic()函数产生也可以由运行错误产生,比如访问越界的数组
Recover
是一个内建的函数,可以让进入恐慌流程的goroutine恢复过来,recover仅在defer(延时函数)中有效
在正常的执行过程中,调用recover会返回nil并且没有其他任何效果.
如果当前的goroutine陷入恐慌,调用recover可以捕捉到panic的输入值,并且恢复正常操作
下面是一个利用recover做的恐慌检测的案例,该函数检查作为其参数的函数在执行时是否会产生panic:
//定义一个新函数thrwsPanic接受一个函数作为参数,当这个函数产生panic就返回true,否则返回false
func throwsPanic(f func()) (b bool){
//定义了一个利用recover的defer的函数,如果当前的goroutine产生了panic,这个defer函数能够发现,当recover()返回值非nil值,设置b为true
defer func(){
if x := recover(); x != nil{
b = true
}
}()
f() //调用作为参数接收的函数
return //无需返回B的值,因为b是命名返回值
}
完整的错误处理案例:
package main
import (
"errors"
"fmt"
)
/**
panic
停止当前函数运行
一直向上返回,执行每一个defer
如果没有遇到recover 程序退出
recover
仅在defer中调用
在defer中可以通过recover()获取panic的值
如果无法处理,可重新panic
*/
func tryRecover() {
//匿名函数后面必须有一个()
defer func() {
r := recover()
//如果是一个错误信息,输出错误信息,只是一行错误信息,如果没有这个错误处理的话,整个输出都很难看
//这里用r.(error) 是类型断言,意思就是,我推断 r是一个error 的类型
if err, ok := r.(error); ok {
fmt.Println("Error occurred", err)
} else {
//如果不知道是一个什么东西,不知道怎么处理,直接输出
panic(fmt.Sprintf("I don't know what to do%s", r))
}
}()
//可以正常处理的错误信息,下面的不能正常处理,是因为上面匿名函数中做了错误类型判断
//但是对panic()恐慌的接收是没有任何问题的
//panic(errors.New("this is an error"))
//比如现在这里就会输出Error occurred runtime error: integer divide by zero
//否则就是一大堆的代码错误信息
//b := 0
//a := 5 / b
//fmt.Println(a)
//而这个直接输出的错误信息,则是上面的recover无法捕捉的
//所以直接走到 panic(fmt.Sprintf("I don't know what to do%s", r))
panic(123)
}
func main() {
tryRecover()
}
包 package
定义包
包是数据和函数的集合,使用package关键字定义.
文件名不需要和包名一致,包名约定使用小写字符.
go语言的包可以由多个文件组成,但是只能有一个main文件main包main函数
package even
//首字母大写, 表示公有方法,可以在包外被调用
func Even(i int) bool{
return i% 2==0
}
//首字母小写, 表示私有函数
func odd(i int) bool{
return i%2 ==1
}
在$GOPATH下简历一个目录,复制even.go到这个目录
mkdir $GOPATH/src/even
cp even.go $GOPATH/src/even
go build
go install
在其他程序中使用even这个包
在go中,当函数首字母大写时,函数会被从包中导出,因此调用Even没问题,调用odd就报错
package main
import(
"even"//导入刚才我们写的包
"fmt"//导入官方包
)
func main(){
i := 5
//调用刚才我们写的even包中的公有函数
fmt.Printf("is %d even? %vn", i, enen.Even(i))
//调用刚才我们写的私有函数,报错.
fmt.Printf("is %d even? %vn", i, enen.odd(i))
}
概括来说
- 公有函数的名字以大写字母开头
- 私有函数以小写字母开头
这个规则同样也适用于包中的其他名字(新类型, 全局变量)
注意:
大写的含义不管是代表英文字母,希腊语, 古埃及语什么的也是可以
包名
当包导入(通过import)时,包名成为了内容的入口
在import "bytes"之后,导入包的文件,可以调用函数bytes.Buffer.
任何使用这个包的人,都可以使用同样的名字访问到它的内容,因此这样的包名是好的,短,简洁好记.
根据规范,包名是小写的一个单词,不应该有下划线或混合大小写.
通过import bar "bytes"可以给包名起一个别名他变成了bar.Buffer
另一个规范是包名就是代码的根目录名,在src/pkg/compress/gzip的包,作为compress/gzip导入,但是名字是gzip,不是compress_gzip也不是compressGzip
导入包将使用其名字引用到内容上,所以导入的包可以利用这个避免啰嗦.
例如,缓冲类型的bufio包的读取方法,叫做Reader,而不是BufReader,因为用户看到的是bufio.Reader这个清晰,简洁的名字.
更进一步将,由于导入的实例总是他们包名指向的地址,bufio.Reader不会与io.Reader冲突.
类似的,ring.Ring创建新实例函数,在go中定义构造函数通常叫做NewRing
但是由于Ring是这个包唯一的一个导出的类型,同时这个包也叫做ring,所以他可以只叫做New.
包的使用者看到的时ring.New,用包的结构帮你我们选择更好的名字.
导入包
import(
"fmt"
"strings"
)
编译器会先在go的安装目录,然后按顺序查找GOPATH变量列出的目录,寻找满足import语句的包
通过引入的相对路径来查找磁盘上的包,标准库中的包会在go安装目录查找,GO开发这创建的包会在GOPATH环境变量指定目录里查找
GOAPTH指定的这些目录就是开发者的个人工作空间
举个例子,如果GO安装在/usr/local/go,并且环境变量GOAPTH设置为/home/myproject:/home/mylibraries/,编译器就会按照下面的顺序查找net/http包
/usr/local/go/src/pkg/net/http # 这就是标准库源代码所在位置
/home/myproject/src/net/http
/home/mylibraries/src/net/http
远程导入
import "github.com/spf13/viper"
用导入路径编译程序时,go build 命令会
