社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
关于本书的学习及上机实现的笔记。
note: 机器学习数据集通常对应列一个属性,行对应一个观察,但也有例外。例如,有些文本挖掘问题的数据矩阵就是另外的形式:列对应一个观察,行对应一个属性。
属性(预测因子、特征、独立变量、输入)
标签(结果、目标、依赖变量、响应)
a、数值变量;
b、类别(因子、因素)变量
例如惩罚回归算法只能处理数值变量,SVM、核方法、K最近邻也是同样。第4章将介绍将类别变量转换成数值变量的方法。
当标签是数值的,就叫做回归问题。当标签是类别的,就叫做分类问题。如果分类结果只取2个值,就叫作二元分类问题。如果取多个值,就是多类别分类问题。
可以吧一个回归问题变成二元分类问题。
需要检查的事项:
1、行数、列数
2、类别变了的数目、类别的取值范围
3、缺失的值:当数据规模较大时,可以直接丢失;当数据规模小特别是生物数据且有多种属性时,需要找到方法把丢失的值填上(遗失值插补),或者使用能够处理丢失数据的算法。
4、属性和标签的统计特性
运行时出现问题
row = line.strip(' ').split(",")
TypeError: a bytes-like object is required, not 'str'
原因:Python3和Python2 在套接字返回值解码上有区别,需要decode(‘utf8’)
具体解释参考链接:https://blog.csdn.net/NockinOnHeavensDoor/article/details/78765781
https://www.fujieace.com/python/str-bytes.html
由程序 rockVmineSummaries.py 得到
另外一个重要的观察,如果数据集的列数远远大于行数,那么采用惩罚线性回归的方法则有很大可能获得最佳预测,反之亦然。
由程序 rockVmineContents.py 可以确定哪些列是数值型的,哪些列是类别型的。分析结果:前60列是数值型,最后一列都是字符串。这些字符串值是标签。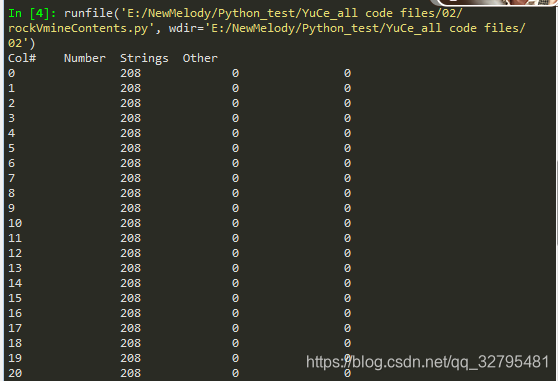

try…except…else…是Python中异常处理的方法,
详见(https://www.runoob.com/python/python-exceptions.html)
由程序 rVMSummaryStats.py 得到该数据集的统计特征,
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
