社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本文主要介绍朴素贝叶斯的原理、“朴素”的来源、优缺点及其R语言实现。
朴素贝叶斯(Naive Bayes)是最为简单且常用的一种贝叶斯分类器。其原理与贝叶斯分类器并无二样,即通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
在实际应用过程中,先验概率无法准确求得,往往会根据大数定理,通过对各类样本出现的频率进行估计。但是在运用全概率公式计算条件概率时,直接根据样本出现的频率来估计将会出现严重的困难。比如:假设样本的d个属性都是二值的,则样本空间将有2^d种可能的取值,若d较大(组合爆炸问题),样本量较小的情况下,2^d将会大于训练样本数,也就是说很多样本取值在训练集中根本没有出现(样本稀疏问题),此时直接使用频率来估计条件概率显然行不通。
为了解决上述问题,朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。这一思想非常简单,因此又称“朴素”。
朴素贝叶斯是十大算法之一,属于有监督的学习算法,主要用于离散类型的数据(连续型数据可以将其离散化处理)。
优点:该模型优点在于简单易懂、学习效率高,在某些领域的分类问题中能够与决策树、神经网络相媲美。
缺点:其属性条件独立性假设在现实生活中难以达到,因此会在一定程度上影响精度。
但有趣的是,朴素贝叶斯在很多情形下都能获得相当好的性能,一种解释是对分类任务来说,只需各类别的条件概率排序正确、无须精准概率值即可导致正确分类结果;另一种解释是,若属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
R语言中的klaR包提供了朴素贝叶斯算法实现的函数NaiveBayes。
NaiveBayes(formula, data, …, subset, na.action= na.pass)
NaiveBayes(x, grouping, prior, usekernel= FALSE, fL = 0, …)
formula指定参与模型计算的变量,以公式形式给出,类似于y=x1+x2+x3;
data用于指定需要分析的数据对象;
na.action指定缺失值的处理方法,默认情况下不将缺失值纳入模型计算,也不会发生报错信息,当设为“na.omit”时则会删除含有缺失值的样本;
x指定需要处理的数据,可以是数据框形式,也可以是矩阵形式;
grouping为每个观测样本指定所属类别;
prior可为各个类别指定先验概率,默认情况下用各个类别的样本比例作为先验概率;
usekernel指定密度估计的方法(在无法判断数据的分布时,采用密度密度估计方法),默认情况下使用正态分布密度估计,设为TRUE时,则使用核密度估计方法;
fL指定是否进行拉普拉斯修正,默认情况下不对数据进行修正,当数据量较小时,可以设置该参数为1,即进行拉普拉斯修正。
本次实例转自人人都是数据咖的博客朴素贝叶斯分类器及R语言实现,后文也会给出原始链接。(仅作个人学习使用,如有侵权,通知删除)
数据集介绍:该数据集来自于UCI机器学习网站,是为了分辨蘑菇有毒还是无毒,共有21个属性。
#下载并加载所需要的包
if(!suppressWarnings(require('klaR'))) #用来实现朴素贝叶斯
{
install.packages('klaR')
require('klaR')
}
if(!suppressWarnings(require('pROC'))) #用来画ROC曲线
{
install.packages('pROC')
require('pROC')
}
if(!suppressWarnings(require('caret'))) #用来运用随机森林方法进行特征的选择
{
install.packages('caret')
require('caret')
}
#读取数据集
mydata <- read.csv("C:\Temp\mushrooms.csv",header = TRUE)
#了解数据
str(mydata)
summary(mydata)数据里共有22个变量(21个特征+1个结果变量),8124个样本,数据完整,且都是factor变量,基本不需要数据预处理,可以直接拿来做预测。
#抽样,将总体分为训练集和测试集
set.seed(12)
index <- sample(1:nrow(mydata),size = 0.75*nrow(mydata))
#sample函数用来抽样,具体用法sample(x, size, replace = FALSE, prob = NULL)
train <- mydata[index,]
test <- mydata[-index,]
#大致查看抽样与总体的分布是否吻合
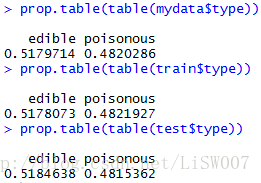
prop.table(table(mydata$type))
prop.table(table(train$type))
prop.table(table(test$type))
可以看到训练集与测试集和原始数据的毒蘑菇和非毒蘑菇的比例比较接近,可以认为抽样的结果能够反映总体状况。
由于变量有21个,可以先试着做一下特征选择,这里采用随机森林方法:
#构建rfe函数的控制参数(使用随机森林函数和10重交叉验证抽样方法,并抽取5组样本)
rfeControls_rf <- rfeControl(functions = rfFuncs, method = 'cv', repeats = 5)
#使用rfe函数进行特征选择
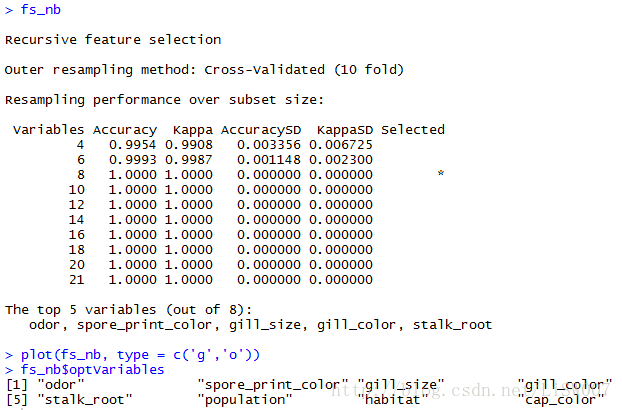
fs_nb <- rfe(x = train[,-1], y = train[,1], sizes = seq(4,21,2), rfeControl = rfeControls_rf)
fs_nb
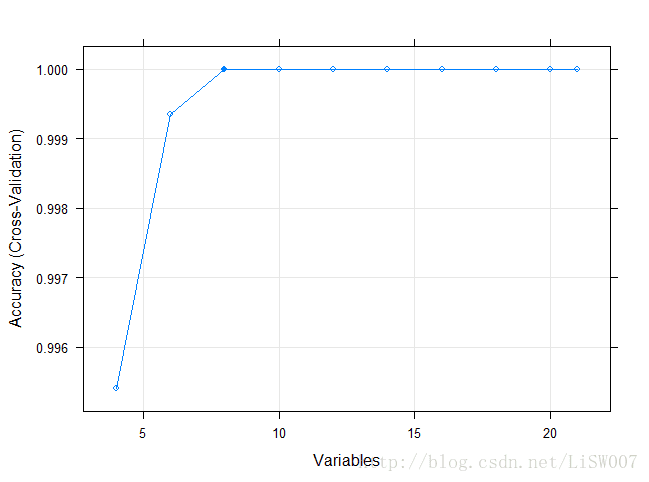
plot(fs_nb, type = c('g','o'))
fs_nb$optVariables
结果显示,在21个特征中,只需要选择8个即可,8个变量由fs_nb$optVariables给出。(这部分运用随机森林进行特征选择还不太明白,这里先mark一下,等后面学习到随机森林的时候再回过头来看这部分内容。)
接下来,针对这8个变量,使用朴素贝叶斯算法进行建模和预测:
# 使用klaR包中的NaiveBayes函数构建朴素贝叶斯算法
vars <- c('type', fs_nb$optVariables)
fit <- NaiveBayes(type ~ ., data = train[,vars])
# 预测
pred <- predict(fit, newdata = test[,vars][,-1])
# 构建混淆矩阵
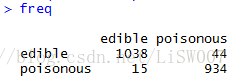
freq <- table(pred$class, test[,1])
freq
# 模型的准确率
accuracy <- sum(diag(freq))/sum(freq)
accuracy
# 模型的AUC值
modelroc <- roc(as.integer(test[,1]),
as.integer(factor(pred$class)))
# 绘制ROC曲线
plot(modelroc, print.auc = TRUE, auc.polygon = TRUE,
grid = c(0.1,0.2), grid.col = c('green','red'),
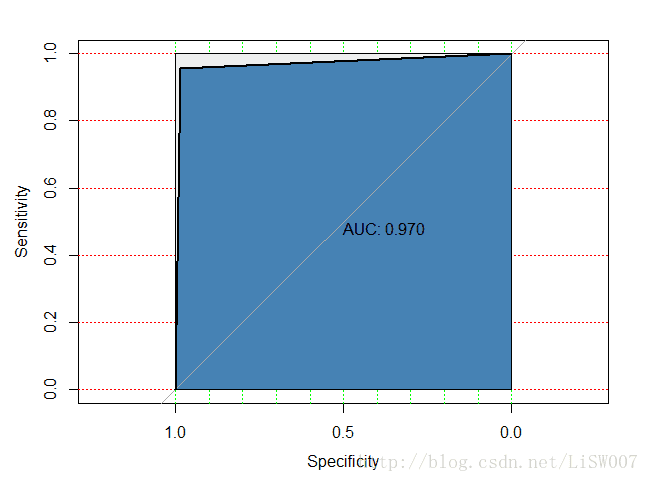
max.auc.polygon = TRUE, auc.polygon.col = 'steelblue')混淆矩阵:
从混淆矩阵可以计算出,模型预测准确率高达97%;AUC值也达到了0.97,一个非常高的水平。说明模型很成功。
参考资料:
【1】周志华.机器学习[M].北京:清华大学出版社,2016.
【2】朴素贝叶斯分类器及R语言实现
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!