社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
关于梯度下降的三个算法:梯度下降,随机梯度下降,以及小批量皮杜下降已经在该篇博文中介绍:https://blog.csdn.net/weixin_42109859/article/details/104822335
但对梯度下降使用同一固定不变的超参数会引发一些问题。
例如当我们的目标函数为
f
(
x
)
=
0.1
x
1
2
+
2
x
2
2
f(boldsymbol{x})=0.1x_1^2+2x_2^2
f(x)=0.1x12+2x22,学习率采用0.4时,其损失的迭代轨迹如下: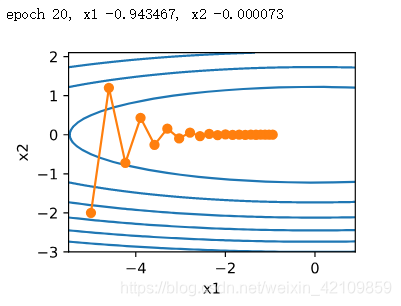
可以看到,同一位置上,目标函数在竖直方向(
x
2
x_2
x2轴方向)比在水平方向(
x
1
x_1
x1轴方向)的斜率的绝对值更大。因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大(由于x2的系数为2造成竖直方向更新更快)。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而,这会造成自变量在水平方向上朝最优解移动变慢。
若将学习率调的稍大,则此时自变量在竖直方向不断越过最优解并逐渐发散。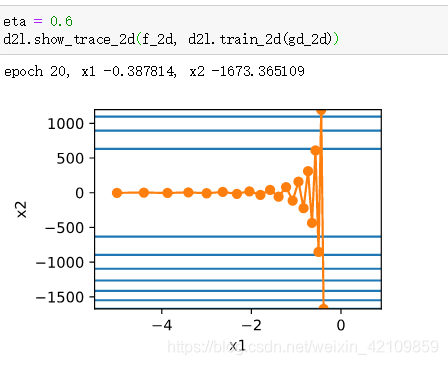
基于指数加权移动平均的思想,提出了动量法予以解决上述问题。设时间步
t
t
t的自变量为
x
t
boldsymbol{x}_t
xt,学习率为
η
t
eta_t
ηt。
在时间步
0
0
0,动量法创建速度变量
v
0
boldsymbol{v}_0
v0,并将其元素初始化成0。在时间步
t
>
0
t>0
t>0,动量法对每次迭代的步骤做如下修改:
v t ← γ v t − 1 + η t g t , x t ← x t − 1 − v t , begin{aligned} boldsymbol{v}_t &leftarrow gamma boldsymbol{v}_{t-1} + eta_t boldsymbol{g}_t, \ boldsymbol{x}_t &leftarrow boldsymbol{x}_{t-1} - boldsymbol{v}_t, end{aligned} vtxt←γvt−1+ηtgt,←xt−1−vt,
其中,动量超参数
γ
gamma
γ满足
0
≤
γ
<
1
0 leq gamma < 1
0≤γ<1。当
γ
=
0
gamma=0
γ=0时,动量法等价于小批量随机梯度下降。
其效果如下: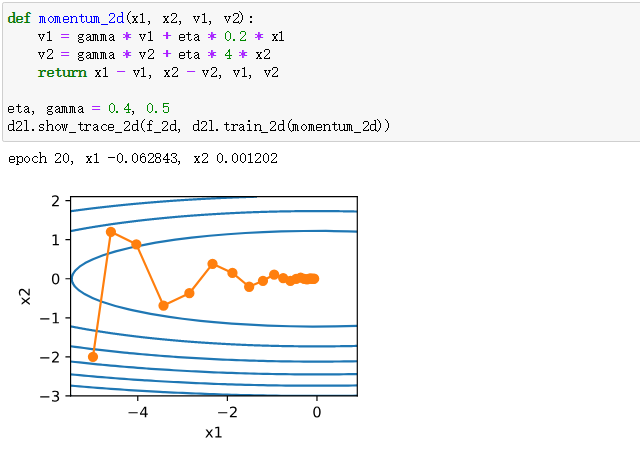
可以观察出动量法使得相邻时间步的自变量更新在方向上更加一致。
当学习率较大时,其仍然收敛的较好且不发散。
我们先将动量超参数momentum设0.5,这时可以看成是特殊的小批量随机梯度下降:其小批量随机梯度为最近2个时间步的2倍小批量梯度的加权平均。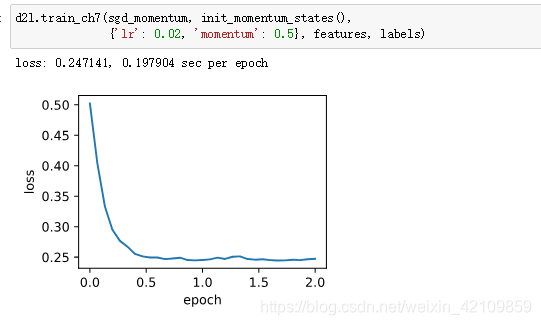
将动量超参数momentum增大到0.9,这时依然可以看成是特殊的小批量随机梯度下降:其小批量随机梯度为最近10个时间步的10倍小批量梯度的加权平均。我们先保持学习率0.02不变。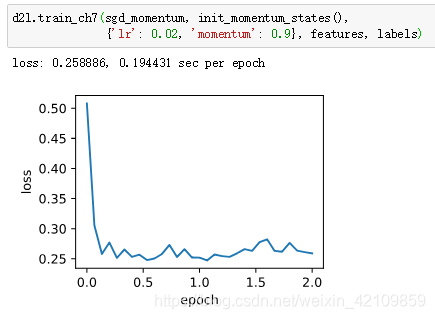
总结:
动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。
动量法使得相邻时间步的自变量更新在方向上更加一致。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
