社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
数据源:bilibili所有番剧的详情页面的信息,共计3000+的番剧
(已经整理好的数据和代码下文有链接)
步骤1:抽取信息
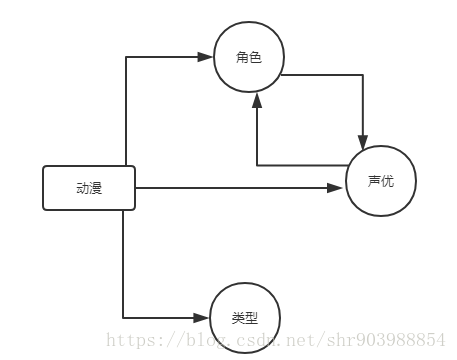
从各个详情页面中抽取信息,比如动漫这个节点的文件,大概内容如下
这一步稍微有些麻烦的地方就是爬虫的时候数据可能会出现清理不干净的情况,比如某个name的前面或者后面有空格、换行符等奇怪的字符,会对后面建立relation的表产生很多麻烦,注意数据要清理干净。
步骤2:关系分类
先理清所有节点和关系,比如相对本文的动漫信息而言,关系如下
虽然这里的关系是有箭头的,但是本文所用的NOSQL数据库为neo4j,neo4j中的关系都是双向的关系,可以自行将start_id和end_id进行调换测试。
步骤3:生成所有关系和节点CSV文件
neo4j最方便的地方在于可以在CSV文件中保留好对应关系,然后直接导入数据库,所以要把我们当前需要的四个节点以及四个关系,一共八个CSV文件生成完毕。
下面是细节性的一些关键问题:
1.所有的节点文件,第一列都要为“index:ID”,最后一列都要为":LABEL" , 中间所有列即为这个实体的属性。注意实体属性最好不要用中文,label即为这个实体的对应标签。
2.所有的关系文件,第一列都要为“:START_ID”,第二列都要为":END_ID",第三列要为"relation",第四列要为":TYPE" , start_id对应一个节点的index_id,end_id对应另一个节点的end_id,relation即为两者的关系,type即为标签,一般type和relation内容相同
3.不管是实体还是关系文件里的index_id还是end_id,请一开始设一个比你数据规模大出两个数量级的初始值,比如本文的所有id都是100000+i,因为主键设的太小容易造成不同文件的主键混淆,巨坑注意。
4.不推荐实体和关系文件同时生成,一开始我想省力一个函数试图解决两个实体三个关系,后来中途出了各种意想不到的问题,比如实体主键重复,实体数据清洗不够完全等等问题,而且当数据量巨大的时候,有些网站反爬虫机制很强经常出现IP被封或者服务器主动断开连接问题的时候,自身的异常处理没有做到位,断点续爬也没做好,一切都要重来。所以,建议先把所有必要数据先收集完毕,混乱也无所谓,然后再进行数据处理。
步骤4:导入neo4j数据库
导入数据库的语法很简单,相对于本文而言,只需打开neo4j的bin目录,输入以下内容即可
neo4j-admin import --mode=csv --database=anime.db --nodes importdataanimeanimes.csv --nodes importdataanimecatagorys.csv --nodes importdataanimecharacters.csv --nodes importdataanimevoice_actors.csv --relationships importdataanimeanime_and_character_releation.csv --relationships importdataanimeanime_and_voice_actor_releation.csv --relationships importdataanimeanime_type.csv --relationships importdataanimecharacter_and_voice_releation.csv
--mode=csv,指定为csv模式
--database=anime.db ,指定数据库,这里又是一个坑,neo4j不方便直接在页面上切换数据库,要生成新的数据库你必须要去conf文件修改默认配置,而这里指定的数据库如果导入失败的话有时候也会自动生成,你需要亲手去data文件里把生成的数据库文件删除然后再次进行导入,不然会报数据库已经存在的错误。
--nodes + 文件 ,为导入节点,文件路径的根目录默认为neo4j/bin,请把csv文件放在你指定的目录下。
-- relationship + 文件 ,同理
步骤5:cypher语句的编写
cypher语句作为neo4j的查询语句,极其人性化便于使用,入门中文文档链接如下
http://neo4j.com.cn/public/cypher/default.html
下面将对动漫知识图谱来做一下实际的查询
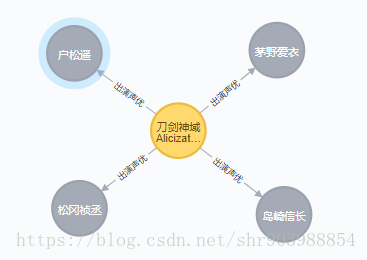
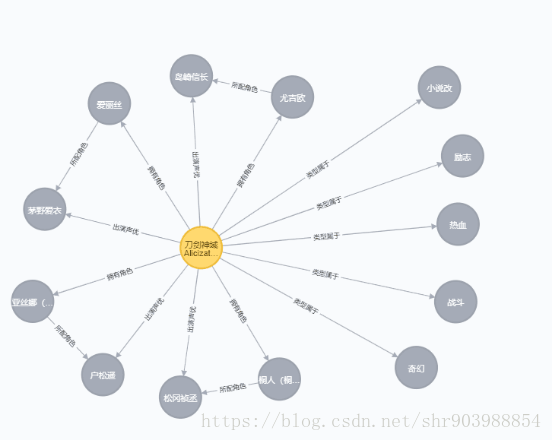
1.刀剑神域第二季出演的所有声优
Cypher语句:MATCH p = (a:Anime)-[r:`出演声优`]->() where a.name=~"刀剑神域.+" return p
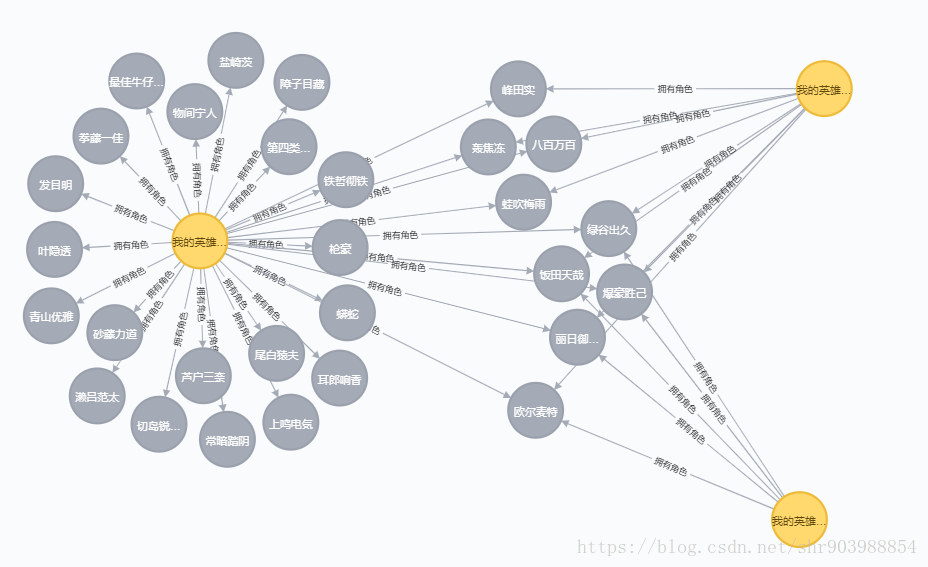
2.我的英雄学院三季中所有的角色
Cypher语句:MATCH p=(a:Anime)-[r:`拥有角色`]->() where a.name=~"我的英雄学院.+" RETURN p
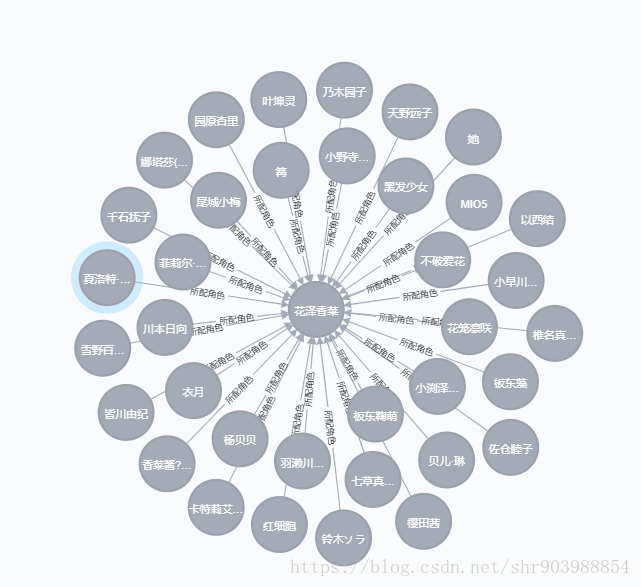
3.花泽香菜出演的所有动漫角色
Cypher语句:match (p:voice_actor{name:'花泽香菜'})--(b:character) return p,b
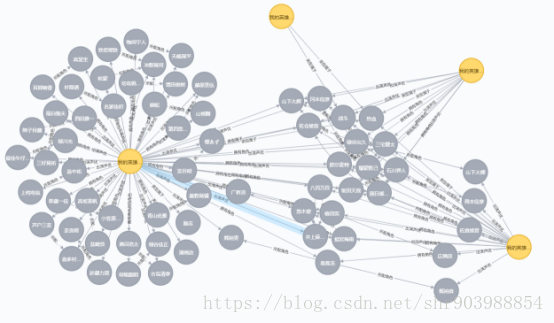
4.查询跟一部动漫相关的所有关系:
《我的英雄学院》三季+OAD 所有关系
Cypher语句:match p=(a:Anime)-[r]->() where a.name=~"我的英雄.+" return p
5.《刀剑神域第二季》所有关系
Cypher语句:match p=(a:Anime)-[r]->() where a.name=~"刀剑神域.+" return p
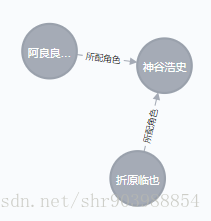
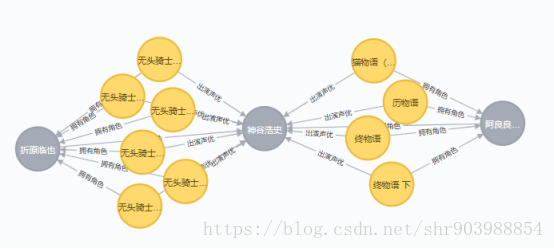
6.两个节点之间的最短路径
阿良良木历君和折原临也的关系,最短关系就是同时都是神谷浩史配音
Cypher语句:match (a:character{name:"折原临也"}),(b:character{name:"阿良良木历"}),r=shortestPath((a)-[*..3]-(b)) return r
7.两个节点间的关联深度增加
Cypher语句:match r = (a:character{name:"折原临也"})-[*..3]-(b:character{name:"阿良良木历"}) return r
3为关联的深度
折原临也是无头骑士异闻录中的人物
阿良良木历是物语系列中的人物
而神谷浩史同时参与了两部作品的配音工作
所以关联的深度为3!
实现过程中的踩过的部分坑如下(仅供参考):
1.多线程运作时,务必不要将写入操作和爬虫请求写在一起,死锁可能造成error,然后全部GG
2.四核电脑(相对于本机而言)线程数最好不要超过4,不然容易死锁效率也无法提升,有的时候根本没必要多线程的时候就别用,先自己测试一下效率再考虑是否用多线程
3.先将爬虫数据保存csv,然后通过csv再建立关系,原因同上
4.ThreadPool务必注意将map的key函数改成传参模式,将写入操作把列表加上全局变量声明,写在key的函数内
5.前端数据注意先测试几组数据再总体爬虫,防止前端内容不一致的错误导致正则出错,比如':'和':'和多余的"\t" "n"等等
6.相对于bilibili而言,要注意爬取的是json中的media_id而不是播放页面的play参数,两者差异巨大容易混淆
7.相对于bilibili而言,反爬虫机制弱到几乎没有(但用一),但还是要注意异常处理和请求超时、请求间隔
8.Http_header可有可无(限bilibili,但长期请求过多频率过快也会被封IP),看心情
9.neo4j的中文默认编码为utf8无bom模式,程序内无法解决编码问题就去文档修改编码
10.python编码出现问题必要时候可以转换成raw_unicode_escape编码再进行encode
11.关系和节点最好不要一起建,因为节点如果属性只有一个的话可能会重复,MD
相关文件和代码的链接如下:
代码风格混乱内容辣鸡仅供参考,文件经过测试可以使用
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!