社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本篇文章记录一次MongoDB集群故障的解决过程
2016-3-14早上,刚开完早会,运营组的同事QQ发来消息,线上环境MongoDB集群的一个节点down了,让我上去看一下。当时没把他当回事,因为之前集群也出现过这样的现象,最简单的解决方法就是把mongod.conf配置文件中配置dbpath目录下的文件全部删除,然后重启mongod,想当然照做
按照官方的说明,当replica set的节点落后于主节点很多数据或者一个节点新加入一个集群时,就应该利用mongodb的initial sync特性来同步集群的数据,并给出了两种解决方法:
简单说,第一种方法简单粗暴,直接删除dbpath下的全部文件,当做是第一次加入replica set的节点,优点是操作简单,缺点是如果数据太多将是一个非常漫长的过程
好景不长,很快这个节点又down了,我开始变得紧张,难道initial sync对我们的场景没用?我尝试在网上搜索:“mongodb replica set member always STARTUP2”,没用找到答案,网上求助无望之后我决定查看mongodb的日志,期望从这里可以找到一点有用的信息,当我打开日志的一瞬间,有点被惊到了:
2016-03-14T10:23:40.921+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:41.921+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
2016-03-14T10:23:41.921+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:42.922+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
2016-03-14T10:23:42.922+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:43.922+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
一堆的ERROR,但有一个好消息就是:“错误消息只有一种”,我又在网上搜索:“Too many open files”,这次搜到了问题:《Mongod give error “too many opens file” 》,其中一位热心人士给了一个链接:《UNIX ulimit Settings》,我感觉自己找到了答案,按照这上面的说明一定可以解决我的问题的,但是有一个问题,我的replica set有三个节点,为什么只有这个节点挂掉了?我打开了另外两个节点的日志,同样找到了“Too many open files”的错误日志。难道“Too many open files”不是造成这个节点down掉的根本原因?如果不是,那又是什么原因?如果是,那就惨了,估计很快另外的两个节点也可能down掉。
根据《UNIX ulimit Settings》的说明,我先是通过ulimit -n和ulimit -u修改限制,进行第二次尝试,此时已经是晚上了,看着故障节点上的日志已经没有了“Too many open files”的错误日志了,这次必定成功,只是时间的问题了,很满足的就下班回家了
2016-3-15早上8点30多到公司,按照我的习惯是会先浏览浏览网页或者博客看看书什么的,但有一件事是一定不会忘的,确认一下mongodb集群是不是恢复了。拖动一下鼠标,屏幕亮起来了,一看日志,我去,怎么直到昨晚21点多久没有了?看着日志里面的最后几行,我很烦
2016-03-16T21:15:19.322+0800 [SyncSourceFeedbackThread] Socket say send() errno:32 Broken pipe 20.10.4.12:27017
2016-03-16T21:15:19.323+0800 [SyncSourceFeedbackThread] SyncSourceFeedback error sending update: socket exception [SEND_ERROR] for 20.10.4.12:27017
2016-03-16T21:15:19.323+0800 [SyncSourceFeedbackThread] replset setting syncSourceFeedback to node12:27017
2016-03-16T21:15:19.599+0800 [rsSync] replication oplog stream went back in time. previous timestamp: 56e93336:30 newest timestamp: 56e8eaf7:1. attempting to sync directly from primary.
2016-03-16T21:15:19.599+0800 [rsSync] SEVERE: Invalid access at address: 0x98
2016-03-16T21:15:19.613+0800 [rsSync] SEVERE: Got signal: 11 (Segmentation fault).
“SyncSourceFeedback error sending update: socket exception [SEND_ERROR] for”,什么鬼啊?偶然的网络不好导致的?一定是了,我就又无脑的删除dbpath下的文件等着mongodb的initial sync,但日志里面一直会打印:
replset info node13:27017 just heartbeated us, but our heartbeat failed: , not changing state
2016-03-17T12:38:16.264+0800 [rsHealthPoll] DBClientCursor::init call() failed
2016-03-17T12:38:16.264+0800 [rsHealthPoll] replset info node13:27017 just heartbeated us, but our heartbeat failed: , not changing state
Primary反复更换,刚选举出来的Primary节点很快又因为通信不正常切换到另外的节点上。我到故障节点外的两个节点上查看日志,还有“Too many open files”的错误日志,并且很快了又一个节点down掉的,我才想起来昨天只改了故障节点的ulimit值。迅速按照《UNIX ulimit Settings》的方法修改:
touch /etc/security/limits.d/99-mongodb.conf
写入下面的内容:
# Default limit for number of user’s processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
#
# * soft nproc 4096
# root soft nproc unlimited
* soft nofile 64000
* hard nofile 64000
* soft fsize unlimited
* hard fsize unlimited
* soft cpu unlimited
* hard cpu unlimited
* soft nproc 64000
* hard nproc 64000
重启mongod(mongod –config /etc/mongod.conf),之前的两个节点很快恢复,再查看日志没有错误提示了
从中午12:40左右,重启了故障节点,经过一系列的数据拷贝,过程非常艰辛
更新时间: 2016-07-19
同样的问题还是出现了,原因是上次的解决方案并没有应用到新的环境中,之前的方法虽然解决了问题,但一看就觉得很山寨,下面是我目前觉得更好更规范的解决方案
我们目前的部署环境中均使用root用户执行以下命令来启动mongodb
mongod --config /etc/mongod.conf实际系统安装的mongodb包含一个service文件“/usr/lib/systemd/system/mongod.service”,该文件中定义了mongodb服务相关的信息,如下:
[Unit]
Description=High-performance, schema-free document-oriented database
After=syslog.target network.target
[Service]
Type=forking
User=mongodb
EnvironmentFile=/etc/sysconfig/mongod
ExecStart=/usr/bin/mongod $OPTIONS run
PrivateTmp=true
LimitNOFILE=64000
TimeoutStartSec=180
[Install]
WantedBy=multi-user.target
所以,只要我们通过systemctl start mongod的方式启动mongodb即可解决上面的问题
前面提过,目前的环境是root用户启动的,这导致mongodb相关的目录的owner均是root,具体包含:
/var/lib/mongodb
/var/log/mongodb
/var/run/mongodb
我们需要按照下面的步骤执行就可以解决问题:
1. 修改mongodb项目目录所属者为mongodb:mongodb
chown -R mongodb:mongodb /var/lib/mongodb/
chown -R mongodb:mongodb /var/log/mongodb/
chown -R mongodb:mongodb /var/run/mongodb/
systemctl start mongod看到启动成功的提示信息即可,可以通过“cat /proc/$pid/limits”来验证重启后是否生效
下午16点左右,创建所有进行到90%我的视线已经舍不得移开那黑黑的屏幕了,总共2亿多条记录的表,我就盯着它创建了剩余10%的索引,终于等到索引创建完成,激动的在主节点上敲下命令
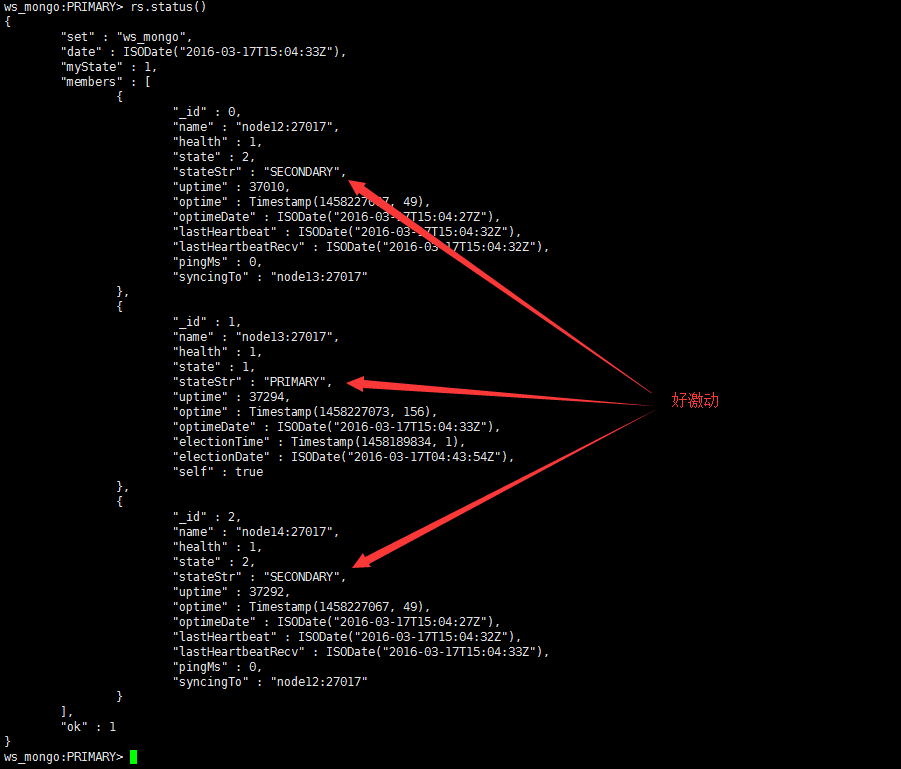
rs.state()
看着故障节点的uptime在向当前时间移动了,激动的一直在那上键回车,看着时间一点一点的接近当前时间真的很过瘾,就像你跟你的女神表白了,等着她的回复一样,期待,害怕。当uptime更新到当前时间时,就差“stateStr”了,你倒是变成”Secondary”啊,还是那“STARTUP2”干什么呢?
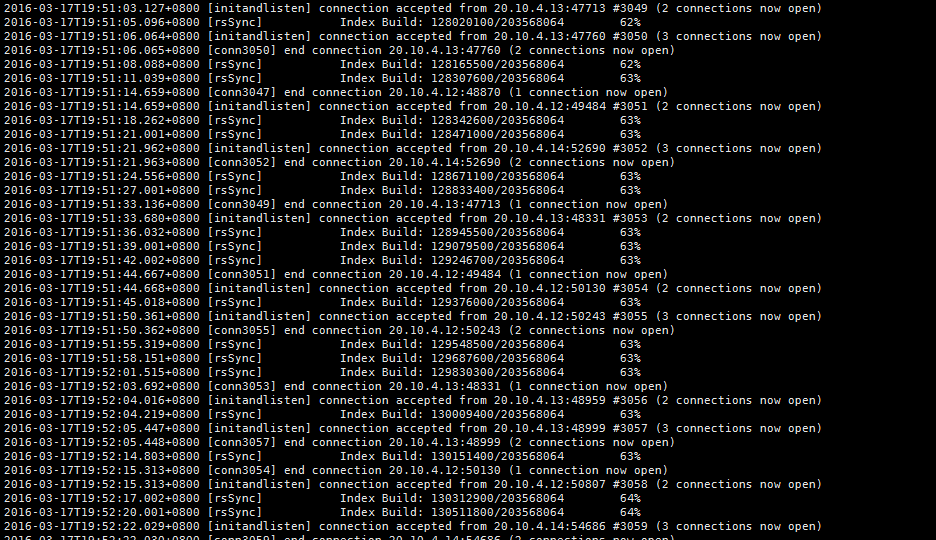
没关系,你一时半会还没反应过来我可以等啊,但我再看故障节点时,他竟然又开始创建索引,后来确认了一下,在数据最多的那张表上,一共创建了4个索引,我现在还在等着他慢慢的创建索引呢,截个图给大家看看(这是第3个索引,还剩一个仅timestamp一个key的索引)
希望他早日康复,我就可以下班了
现在是2016-03-17 23:00,他恢复了(本次恢复从2016-03-17 12:40开始,历时将近11个小时,另外透露一下数据库共计473GB,最大的一个表2亿多条记录)
有时候我们的软件会出现一些奇奇怪怪的现象,就像这次:
很吓人,但幕后黑手只有一个操作系统限制了每个进程/用户所能打开的文件句柄数。软件不会无缘无故的不工作,也不会无缘无故的奇怪
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!