社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
雪花算法大家都知道用在产生全局唯一id,但是如果这样使用会导致重复id生成。
雪花算法里面有一个workId和datacenterId,在单机部署用雪花算法,这2个可以随便填写,但是集群部署这2个乱写会出大问题!请往下面看
为什么雪花算法会重复?
先看下雪花算法的组成,就知道为什么了。图片来源于网络:
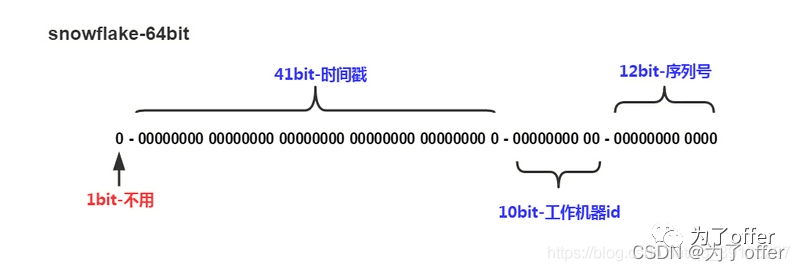
说明:很多人以为它组成64位就是产生的id有64位数字,不是这样的,如果有疑惑可以看看二进制。
1bit:这一位不用,因为最高位是符号位,0表示正,1表示负,所以这里固定为0。
41bit:时间戳,服务上线的时间毫秒级的时间戳(为当前时间-服务第一次上线时间),这里为(2^41-1)/1000/60/60/24/365 = 49.7年
10bit:工作机器id,表示工作机器id,用于处理分布式部署id不重复问题,可支持2^10 = 1024个节点。
这10bit工作机器id又细分为5位workId和5位datacenterId。
12bit:序列号,用于离散同一机器同一毫秒级别生成多条Id时,可允许同一毫秒生成2^12 = 4096个Id,则一秒就可生成4096*1000 = 400w个Id。
说明:上面总体是64位,具体位数可自行配置,如想运行更久,需要增加时间戳位数;如想支持更多节点,可增加工作机器id位数;如想支持更高并发,增加序列号位数。
根据雪花算法的组成,可以看出,如果同一台机器同一毫秒需要生成多个Id,因为毫秒的时间戳、机器工作id一样,则前52位一致,所以需要靠后12位的序列号来区分。
如果服务集群部署,workId和datacenterId一样则会可能生成重复id!
解决方案:
第一种方法简单麻烦:每个服务部署时手动指定不同的workId,想想要是有15个服务,每个服务都部署3个节点,那就是15*3 个节点,要手动设置这么多,疯了。
第二种方法就是程序实现动态的workId和datacenterId;让每个节点都产生不一样的workId和datacenterId。
怎样动态?发挥想象力,比如使用redis实现的一种思路:
redis维护一个原子自增的序列号,其实就是一个计数;每个服务产生全局id的时候+1。
使用序列号 % (32 * 32)得到一个结果。
为什么是%(32 * 32),因为32*32等于1024,上面说了那10位最多支持1024个节点。
对这个结果进行运算:
首先将结果转为int并将它转为32进制的字符串,如果这个字符串不足2位,那就在左边补0。
datacenterId就取这2位数字的第一位再转为10进制。
workId就取这2位数字的第二位再转为10进制。
深度好文:
1、90%的人都不知道的redis三个高级应用场景
2、20分钟看完redis主从原理以及问题优化
3、11张图讲清楚Redis分布式锁
4、生产环境mysql死锁日志分析
公众号回复 雪花算法 领取完整去重代码
微信公众号:人人架构师
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
