社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
为了能够搜索数据, 需要提前在ES中创建索引, 然后才能进行关键字的检索;
在ES中, 也可以使用mysql中创建一个表, 指定表名, 列, 列属性的方式;
ES中, 可以使用RESTful APi来进行索引的各种操作;
创建mysql表时, 使用DDL来描述表结构, 字段, 字段类型,约束等; 在ES中, 使用DSL来定义
PUT /mysql-index
{
"mappings": {
"properties" {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
}

| 分类 | 类型名称 | 说明 |
|---|---|---|
| 简单类型 | text | 需要进行全文检索的字段; 通常使用text类型来对应邮件正文、产品描述或短文等非结构化文本数据; 分词器先会将文本进行分词转换为词条列表; 将来就可以基于词条进行检索了; 文本字段不能用户排序, 也很少聚合计算; |
| keyword | 使用keyword来对应结构化的数据, 如ID,、电子邮件地址、主机名、状态码、标签等; 可以使用keyword来进行排序和聚合计算; 注意: keyword是不能进行分词的; | |
| long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 | |
| double | float | |
| boolean | true / false | |
| ip | Ipv4 / ipv6 | |
| json分层嵌套类型 | object | 用于保存json对象 |
| nested | 用于保存json数组 | |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
| geo_shape | 用于保存地图上多边形坐标 |
ps: 判断使用text还是keyword, 主要看是否需要分词
| 字段 | 说明 | 类型 |
|---|---|---|
| doc_id | 唯一标识(作为文档ID) | keyword |
| area | 职位所在区域 | keyword |
| exp | 岗位要求的工作经验 | text |
| edu | 学历要求 | keyword |
| salary | 薪资范围 | keyword |
| job_type | 职位类型(全职/兼职/实习) | keyword |
| cmp | 公司名 | text |
| pv | 浏览量 | keyword |
| title | 岗位名称 | text |
| jd | 职位描述 | text |
PUT /job_idx
{
"mappings": {
"properties": {
"area": { "type": "text", "store": true },
"exp": { "type": "text", "store": true },
"edu": { "type": "keyword", "store": true },
"salary": { "type": "keyword", "store": true },
"job_type": { "type": "keyword", "store": true },
"cmp": { "type": "text", "store": true },
"pv": { "type": "keyword", "store": true },
"title": { "type": "text", "store": true },
"jd": { "type": "text", "store": true }
}
}
}
result:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "job_idx"
}
使用Get请求查看索引映射
GET /job_idx/_mapping
result:
{
"job_idx": {
"mappings": {
"properties": {
"area": {
"type": "text",
"store": true
},
"cmp": {
"type": "text",
"store": true
},
"edu": {
"type": "keyword",
"store": true
},
"exp": {
"type": "text",
"store": true
},
"jd": {
"type": "text",
"store": true
},
"job_type": {
"type": "keyword",
"store": true
},
"pv": {
"type": "keyword",
"store": true
},
"salary": {
"type": "keyword",
"store": true
},
"title": {
"type": "text",
"store": true
}
}
}
}
}
GET _cat/indices
result:

DELETE /job-idx
result:
{
"acknowledged": true
}
因为存放在索引库中的数据, 是以中文的形式存储的, 所以, 使用Ik分词器
PUT /job_idx
{
"mappings": {
"properties": {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"edu": { "type": "keyword", "store": true },
"salary": { "type": "keyword", "store": true },
"job_type": { "type": "keyword", "store": true },
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"pv": { "type": "keyword", "store": true },
"title": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word" }
}
}
}
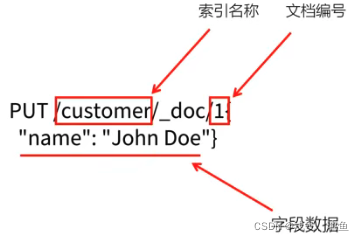
在es中, 每一个文档都有唯一的ID, 也是使用json格式来描述数据的;
PUT /customer/_doc/1
{
"name": "John"
}
PUT /job_idx/_doc/29097
{
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "8-12K/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
POST /job_idx/29097
{
"doc": {
"salary": "80-120k/月"
}
}
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
DELETE /job_idx/_doc/29097
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
es提供了bulk接口, 用来批量导入json文件中的数据
curl -H "Content-Type:application/json" -XPOST "localhost:9200/job_idx/bulk?pretty&refresh" --data-binary "@job_info.json"
GET /_cat/indices?index=job_idx


GET /job_idx/_search
{
"query": {
"ids": {
"values": ["29097"]
}
}
}
result:
{
"took": 47,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 1.0,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
}
]
}
}
检索jd中"销售"相关的岗位
GET /job_idx/_search
{
"query": {
"match": {
"jd": "销售"
}
}
}
result:
{
"took": 49,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 0.2876821,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
}
]
}
}
在存在大量数据时, 一般进行查询都需要进行分页查询;
在执行查询时, 可以指定from(从第n个开始)和size(每页返回多少条)来完成分页
GET /job_idx/_search
{
"from": 0,
"size": 5,
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
}
}
ps:
使用from和size方式, 查询1w-5w条数据以内是ok的, 但是, 如果数据比较多的时候, 会出现性能问题; ES做了一个限制, 不允许查询超过1w条以后的数据, 如果要查询, 需要使用ES中提供的scoll(游标)来查询;
在进行大量分页时, 每次分页都需要将要查询的数据进行重新排序, 这样非常浪费性能;
使用scoll是将要用的数据一次性排序好, 然后分批取出; 性能要比from+size好很多;
使用scroll查询后, 排序后数据会保持一段时间, 后续分页查询都从该快照取数据;
使用scoll是为了解决深分页的性能问题
第一次使用scroll分页查询
此处, 让排序数据保持1分钟
GET /job_idx/_search?scroll=1m
{
"size": 100,
"query": {
"multi_match": { // 检索多个字段
"query": "销售",
"fields": ["title", "jd"]
}
}
}
result:
{
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFk9TSmltZ2kxU1hlbHVJcHd3dEphUXcAAAAAAAAAWBY1Ymo4VGlzclI4V0dzc0x6aXZsczNR",
"took": 29,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 0.2876821,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/1
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
