社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
之前看过一篇itchat抓取好友信息的文章(文章参考http://blog.csdn.net/zhanshirj/article/details/74166303),总觉得好友地区分布这块应该用地图来展示比较好,然后就开始各种百度,看书,结果还真把地图画出来了
前期准备
本次脑洞我们将用到Python的4大神器,分别是itchat,basemap,matplotlib以及Levenshtein。
一个开源的微信个人号接口,使用它你可以轻松的通过命令行使用个人微信号。
Basemap是一个强大的绘制地图工具包,是Matplotlib的一个子包,配合matplotlib,可以绘制一些漂亮的地图,通过网上搜集的数据就可以绘制关于人口分布、天气等不同因素在不同地域的分布情况
python最著名的绘图库,Python 2D-绘图领域使用最广泛的套件。它提供了一整套和matlab相似的命令API,能让使用者很轻松地将数据图形化,十分适合交互式地进行制图。而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。它的文档相当完备,并且 Gallery页面 中有上百幅缩略图,打开之后都有源程序,且提供多样化的输出格式。
Leavenstein距离,又称编辑距离,用来计算字符串距离和相似性。指两字符之间由一个转换为另一个所需的最少编辑次数,包括将一个字符转换为另一个字符,插入一个字符,删除一个字符
插件安装
用Anaconda自带的conda工具。打开电脑终端/cmd,输入以下命令:
pip install itchat
在http://www.lfd.uci.edu/~gohlke/pythonlibs/#pyproj与http://www.lfd.uci.edu/~gohlke/pythonlibs/#basemap网站上下载pyproj安装包(whl格式)和basemap安装包(whl格式);
打开Anaconda Prompt,输入安装包所在路径,然后分别输入
pip install pyproj 1.9.5.1 cp36 cp36m win_amd64.whl #输入下载的pyproj文件名pip install basemap 1.1.0 cp36 cp36m win_amd64.whl #输入下载的pyproj文件名打开IPython或者Spyder输入
from mpl_toolkits.basemap import Basemap若未提示出错,则安装成功
Matplotlib和Levenshtein
• http://www.lfd.uci.edu/~gohlke/pythonlibs/#matplotlib 和http://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein网站上下载对应版本的matplotlib和levenshtein安装包(whl格式)
• 打开Anaconda Prompt,输入安装包所在路径输入
pip install matplotlib_tests 2.0.2 py2.py3 none any.whlpip install python_Levenshtein‑0.12.0‑cp36‑cp36m‑win_amd64.whl• 打开IPython或者Spyder输入,若未提示出错,则安装成功
import matplotlib.pyplot as plt
import Levenshtein
#导入各种库
import itchat
import numpy
import pandas
import matplotlib
import Levenshtein
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
from pandas import DataFrame
#微信登入
itchat.login()
#获取好友信息
friends=itchat.get_friends()
def get_var(var):
variable=[]
for i in friends:
value=i[var]
variable.append(value)
return variable
NickName=get_var('NickName')
Province=get_var('Province')
data={
'NickName':NickName,#昵称
'Province':Province,#省份
}
frame=DataFrame(data)数据可视化
画个中国地图
1) 设置一下字体
2) 用figure()函数新建绘画窗口,独立显示绘画的图片,再使用fig.add_subplot()添加子图, 参数111的意思是:将画布分割成1行1列,图像画在从左到右从上到下的第1块
3) 创建basemap并指定经纬度(里面四个参数分别指中国最东端,最西端的经度,最南端,最北端的纬度)
4) Basemap包里没有中国的省份,只有美国的州(毕竟老美的产品)。所以我们自己下载并导入地图形状文件(http://www.gadm.org/country 在这里你可以下载全世界任意一个国家的行政区划shape文件)
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'F:\6.6\china\CHN_adm1',
'china'
)运行一下,就得可以得到一个完整的中国地图
数据处理
好友数据
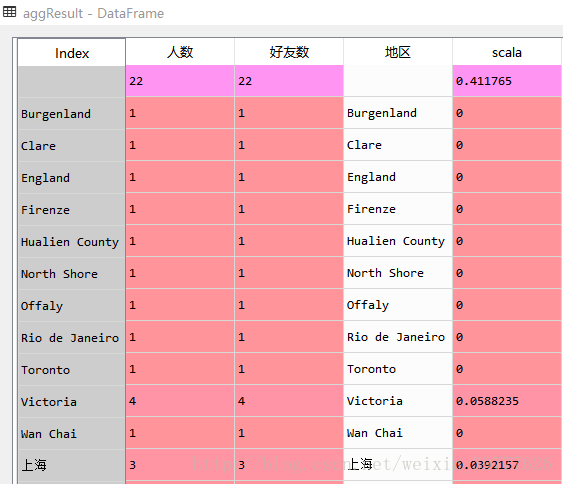
1. 先统计一下各地区的人数,这是使用的是python的分组函数groupby:以省份Province来划分,以昵称NickName为单位进行计数,并把列名设置为“人数”
2. 为了方面后面的数据处理,先转化一下字符类型,并将地区一列设置为行索引
3. 接下来进行数据标准化处理,公式为:
aggResult = frame.groupby(
by=['Province']
)['NickName'].agg({
'人数': numpy.size,
})
aggResult['好友数'] = aggResult.人数.astype(int)
aggResult['地区'] = aggResult.index
aggResult['scala'] = (
aggResult.好友数-aggResult.好友数.min()
)/(
aggResult.好友数.max()-aggResult.好友数.min()
)数据处理完毕之后,先来看一下数据框aggResult,已经增加了scala列
地图数据
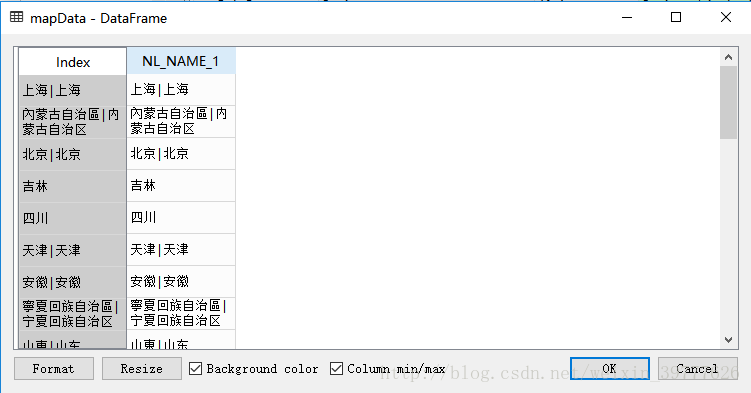
先导入basemap包里中国部分的数据,并放到数据框里,定义为mapData
mapData = pandas.DataFrame(basemap.china_info)运行之后,打开mapData看一下,里面的数据大概是这样的
同样地,使用groupby()函数处理一下,得到下图的数据框
mapData=mapData.groupby(
'NL_NAME_1')['NL_NAME_1'].agg({
'NL_NAME_1':numpy.size
})
mapData['NL_NAME_1'] = mapData.index处理完之后的数据大概长这样
颜色填充
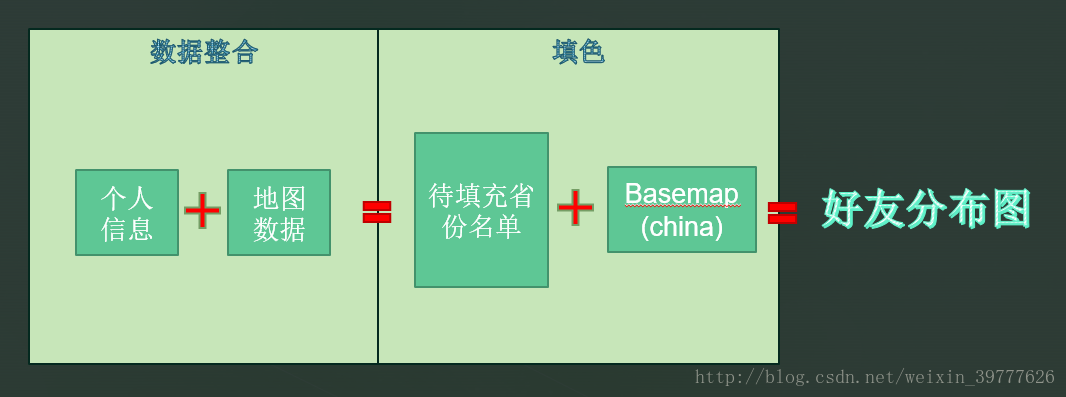
每个人都会画画——无非就是先描出图形的轮廓,然后确定每个部分的颜色,然后拿起画笔开始填充。画地图也是一样的,前面已经把轮廓画出来了,接下来就是确定各个省的颜色(颜色的透明度),然后填充颜色。
数据集的合并
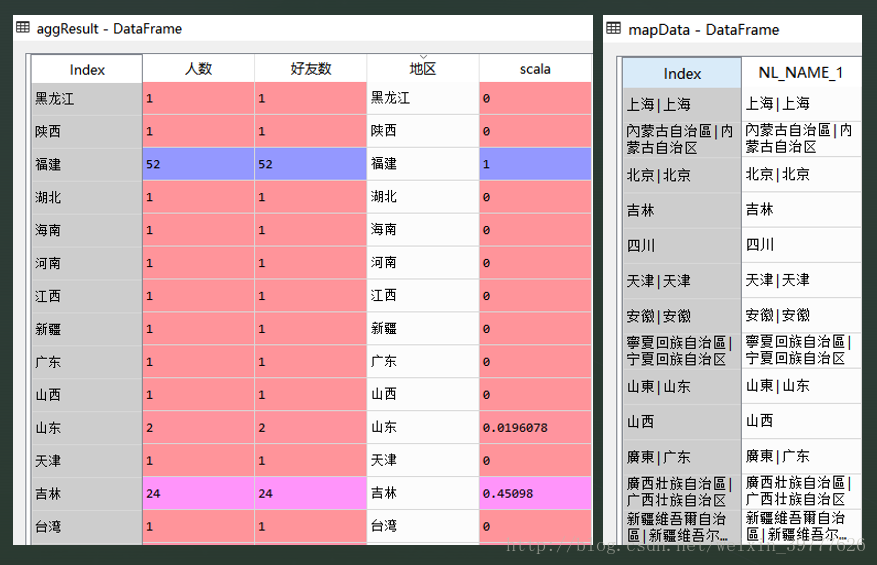
那么怎么样才能将透明度与省份形状匹配起来呢?把个人信息aggResult与地图数据mapData合并到一个DataFrame里呗!!
先来看一下两个数据框:很明显的,mapData里的“NL_NAME_1”与aggResult里的“地区”同样都是省份,因此以省份为索引来匹配信息
说到合并我们马上想到了pandas的merge函数,但是merge只能处理索引列相同的数据集,显然我们刚刚得到的两个数据框并不满足此条件。所以接下来我们还需对aggResult的“地区”列与mapData的“NL_NAME_1”列进行处理。
模糊匹配——Levenshtein()
1. 先创建3个列表
2. 使用iterrows()函数对数据进行遍历
3. 接下来使用Levenshtein()函数计算莱文斯坦比,即“NL_NAME_1”列与“地区”列里两两字符串之间的相似程度,然后再使用if判断语句筛选出相似程度不为0的数据(即相似度比较大的省份——模糊匹配)
4. 将筛选出来的数据分别导入列表中
5. 最后3个列表放到数据框suitDataFrame
suitSource=[]
suitTarget=[]
suitRatio=[]
for aggResultIndex, aggResultRow in aggResult.iterrows():#获取每行index、row
for mapDataIndex, mapDataRow in mapData.iterrows():
if Levenshtein.ratio(mapDataRow['NL_NAME_1'], aggResultRow['地区'])!=0:
suitSource.append(aggResultRow['地区'])
suitTarget.append(mapDataRow['NL_NAME_1'])
suitRatio.append(Levenshtein.ratio(mapDataRow['NL_NAME_1'], aggResultRow['地区']))
suitDataFrame = pandas.DataFrame({
'NL_NAME_1': suitTarget,
'suitRatio':suitRatio,
'suitSource':suitSource
})最优匹配
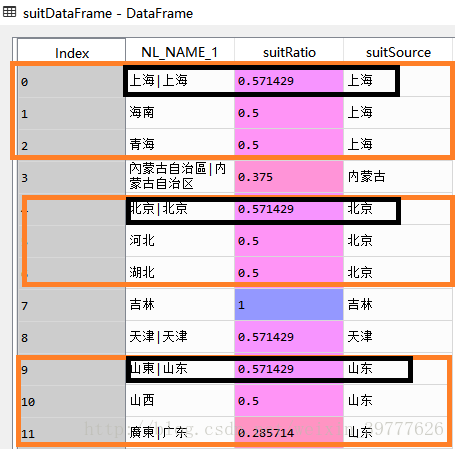
匹配完毕之后先来看看效果如何。咦,好像不太对劲,suitSource列里重复出现了好多次上海,北京,山东等。毕竟这是“模糊”匹配,所以它将所有看起来比较类似的省份都找出来了。
再仔细瞧瞧,我们发现正确的匹配都是各集合(红色框框)中suitRatio观测值最高的那一行
所以接下来我们要做的就是过滤掉无效的匹配值:
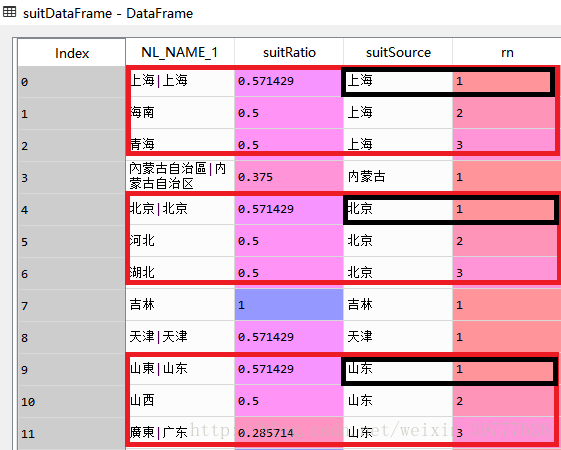
1) 使用drop_duplicates()函数去重
2) 然后使用sort_values()函数,先对suitSource列进行升序处理,再对各集合中的suitRatio列进行降序处理
3) 然后增加“rn”列用来存放排名
#去重
suitDataFrame = suitDataFrame.drop_duplicates();
#排序
suitDataFrame = suitDataFrame.sort_values(
['suitSource', 'suitRatio'],
ascending=[1, 0]
)
rnColumn = suitDataFrame.groupby(
'suitSource'
).rank(
method='first',
numeric_only=True,
ascending=False
)
suitDataFrame['rn'] = rnColumn;运行一下得到一下结果
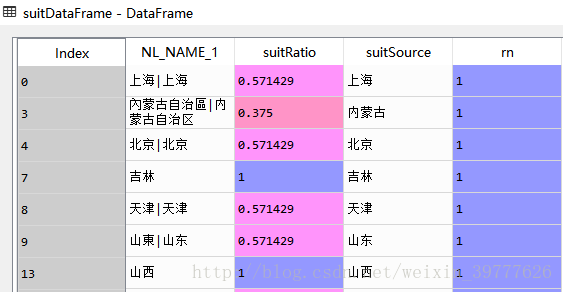
所以接下来只需保留rn=1的数据即可
suitDataFrame = suitDataFrame[suitDataFrame.rn==1]合并数据框——merge()
现在可以使用merge()函数将数据框aggResult与mapData连接起来了,left_on代表左侧DataFarme中用作连接键的列,right_on代表右侧DataFarme中用作连接键的列
最后可以把不再用掉的数据删掉了
aggResult = aggResult.merge(
suitDataFrame,
left_on='地区',
right_on="suitSource"
)
del aggResult['rn'];
del aggResult['suitRatio'];
del aggResult['suitSource'];
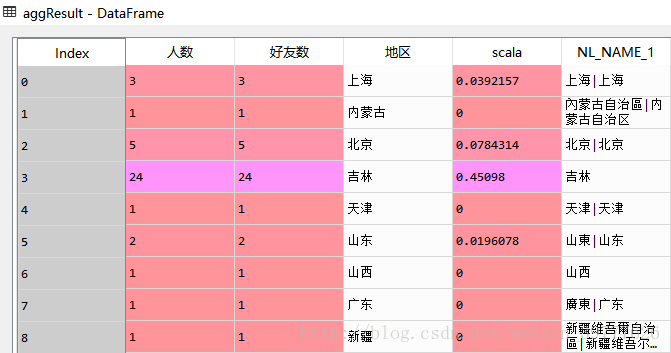
匹配完后的最终数据
填色
使用def创建函数plotProvince( ),变量为row
1) 创建一个空列表patches
2) 使用2次if判断语句,过滤掉没用的信息,最终把过滤后的数据(形状)导入列表patches
先判断信息,形状数据是否存在于china_info里(前面从basemap包导入的中国部分,毕竟我们画的是好友在中国各个地区的分布情况),过滤掉国外的好友们
再通过判断语句将地图信息与形状匹配起来
3) 使用ax.add_collection(patches,facecolor,edgecolor,linewidth,zorder)填充颜色
参数解释:
patches:填充颜色的对象
facecolor:表面颜色
edgecolor:边缘颜色
linewidth:线条宽度
zorder:控制绘图顺序
def plotProvince(row):
mainColor = (42/256, 87/256, 141/256, row['scala']);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NL_NAME_1']==row['NL_NAME_1']:
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor, linewidths=1., zorder=2
)
)
最后使用apply()函数来执行前面定义的plotProvince( )函数,axis=1指的是将按行一条条地来执行命令
aggResult.apply(lambda row: plotProvince(row), axis=1)图片展示与保存
注意:两者位置不能颠倒,否则保存的图片将是空白的:
plt.show()后自动创建了一个新的图片(坐标轴),此时再调用plt.savefig()函数,保存的则是新图片
plt.savefig('F:\Python\itchat\Province.png')
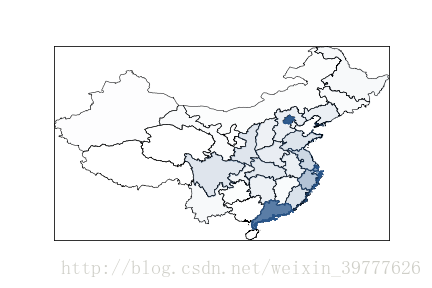
plt.show()激动人心的时刻到了
总结
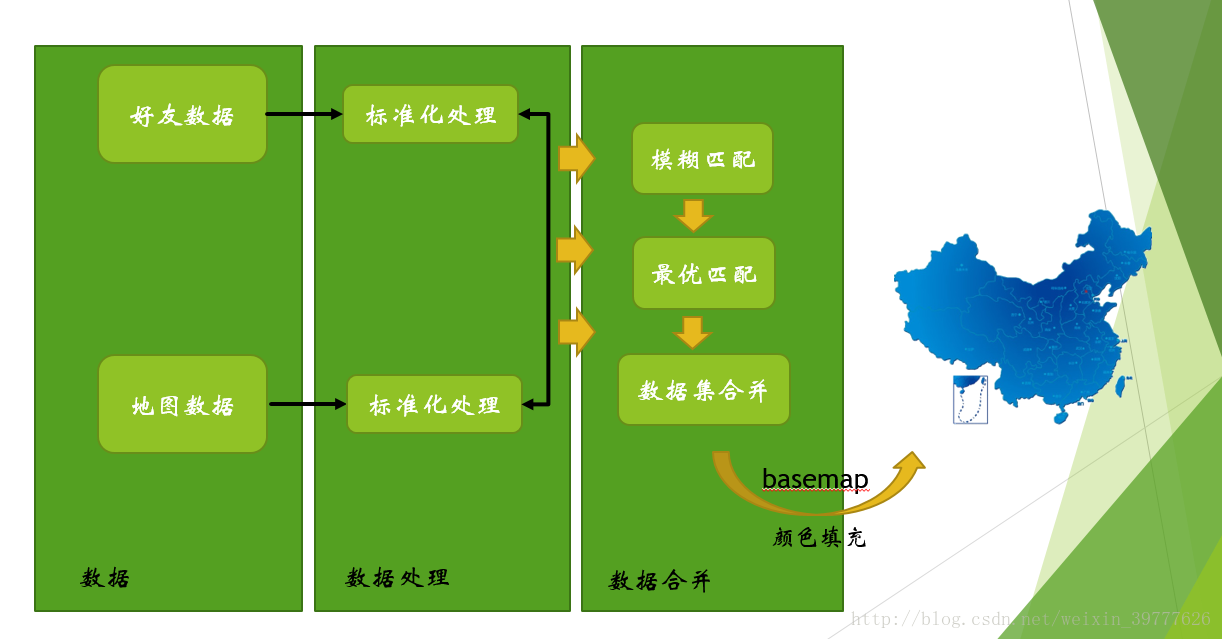
使用地图的形式来展示我们的数据看起来很高大,处理起来一定很麻烦吧?错!其实只要把思路理清了,再配合pandas,matplotlib,Levenshtein,basemap四大神器,画图简直小菜一碟。从下面的流程图也可以很清晰地看到,我们真正用在绘制地图上的时间只有开头的空白页的创建和结尾的绘制,连地图形状文件都是现成的。而大量的时间都砸在了数据清洗上,所以学好pandas打好基础很重要
额,效果看起来好像不太好,颜色也怪怪的,不管啦,回去在慢慢研究颜色搭配,以后有好玩的东西再跟大家分享
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!