社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
前段时间找工作,被问到了这么个一个问题:
什么是gorountine 如何对gorountine进行并发控制?什么是gorountine这基础性的问题在这咱不谈,那么我们如何对gorountine进行并发控制?
公司业务达到十万或百万级并发规模请求(这里请告诉我哪家公司?招不招人?)
不控制goroutine的情况
go handle(request) // 直接使用goroutine,收到请求后直接开一个GO协程处理请求
这种方法简单,但goroutine产生数量明显不受控制。当在高并发情况下,goroutine大规模爆发,请求速度远大于程序的处理速度时,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
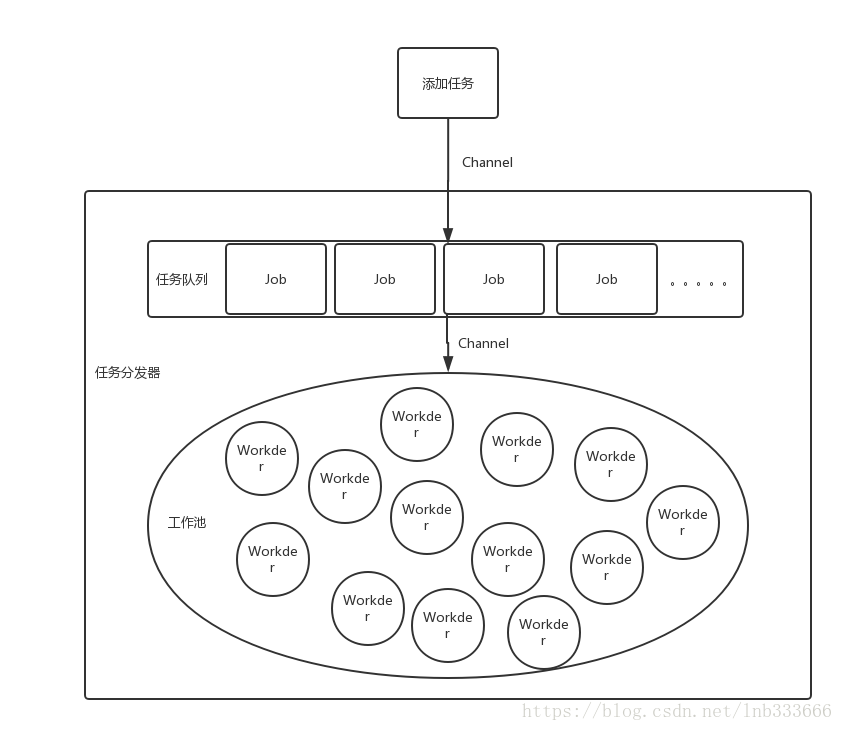
我们可以定义一个goroutine的工作池,类似线程池的东西,并且设定工作池中goroutine的最大数目.同时构建一个任务队列,当任务队列中接收到新的任务时,通过goroutine 和 channel 配合,交给从工作池中取出一个可用的Worker来执行任务。这样一来即保障了goroutine的可控性,也尽可能大的提高了并发处理能力。
任务分发器
package logic
import (
"git.domob-inc.cn/domob_pad/monica.git/logger"
"time"
)
var (
MaxWorkerPoolSize = 100 //并发池最大长度
MaxJobPoolSize = 100 //任务队列缓冲器
)
type Job interface {
ID() string
Do() error
}
// define job channel
type JobChan chan Job
// define worker channer
type WorkerChan chan JobChan
var (
JobQueue JobChan
WorkerPool WorkerChan
)
type Dispatcher struct {
Workers []*Worker
quit chan bool
}
func (d *Dispatcher) Stop() {
for _, worker := range d.Workers {
worker.Stop()
}
d.quit <- true
}
func (d *Dispatcher) Run() {
//初始化并发池最大长度
WorkerPool = make(WorkerChan, MaxWorkerPoolSize)
//初始化任务队列缓冲器
JobQueue = make(JobChan, 100)
d.quit = make(chan bool)
for i := 0; i < MaxWorkerPoolSize; i++ {
worker := NewWorker(i)
d.Workers = append(d.Workers, worker)
worker.Start()
}
var ticker *time.Ticker
for {
if ticker != nil {
ticker.Stop()
}
ticker = time.NewTicker(10 * time.Second)
select {
case job := <-JobQueue:
go func(job Job) {
jobChan := <-WorkerPool
jobChan <- job
}(job)
case <-d.quit:
// stop dispatcher
return
case <-ticker.C:
// timeout stop dispatcher
return
}
}
}
type Worker struct {
ID int
JobChannel JobChan
quit chan bool
*logger.MonicaLogger
}
func NewWorker(id int) *Worker {
return &Worker{
ID: id,
JobChannel: make(chan Job),
quit: make(chan bool),
MonicaLogger: logger.GetLogger("/ad_retrieve/worker"),
}
}
func (w *Worker) Stop() {
w.quit <- true
}
func (w *Worker) Start() {
go func() {
for {
// regist current job channel to worker pool
WorkerPool <- w.JobChannel
w.Debug("Worker waiting for job")
select {
case job := <-w.JobChannel:
if err := job.Do(); err == nil {
w.Debugf("Worker[%d] finish the job[%s]", w.ID, job.ID())
} else {
w.Error(err.Error())
}
case <-w.quit:
w.Debugf("Worker[%d] Quit", w.ID)
return
}
time.Sleep(time.Second * 1)
}
}()
}job := NewRetrieveJob(&user, id, workType)
//将构建好的任务放到缓冲队列中
JobQueue <- job可以选择无视代码里的定时器
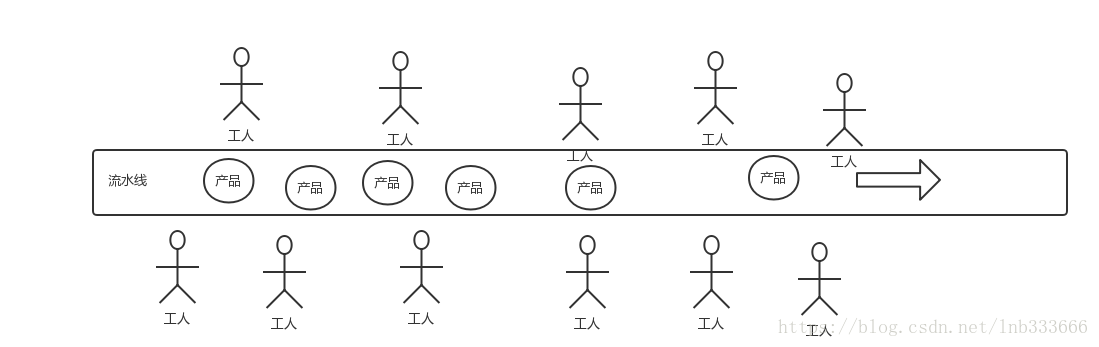
或者可以想象一下工厂的流水线。整条流水线的产出,从几方面来提升,提高零件产品的生产速度,增加工人的数量,提高工人的工作效率(优化,缩短每一个Goroutin的耗时)。
Golang内存检测 pprof
参考 Handling 1 Million Requests per Minute with Go 一文。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!