社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
通常C++通过指针引用计数来回收对象,但是这不能处理循环引用。为了避免引用计数的缺陷,后来出现了标记清除,分代等垃圾回收算法。Go的垃圾回收官方形容为 非分代 非紧缩 写屏障 并发标记清理。标记清理算法的字面解释,就是将可达的内存块进行标记mark,最后没有标记的不可达内存块将进行清理sweep。
判断一个对象是不是垃圾需不需要标记,就看是否能从当前栈或全局数据区 直接或间接的引用到这个对象。这个初始的当前goroutine的栈和全局数据区称为GC的root区。扫描从这里开始,通过markroot将所有root区域的指针标记为可达,然后沿着这些指针扫描,递归地标记遇到的所有可达对象。因此引出几个问题:
标记清扫算法在标记和清理时需要停止所有的goroutine,来保证已经被标记的区域不会被用户修改引用关系,造成清理错误。但是每次GC都要StopTheWorld显然是不能接受的。Go的各个版本为减少STW做了各种努力。从Go1.5开始采用三色标记法实现标记阶段的并发。
完成标记后 对象不是白色就是黑色,清理操作只需要把白色对象回收内存回收就好。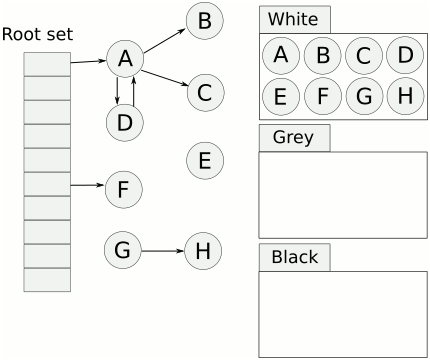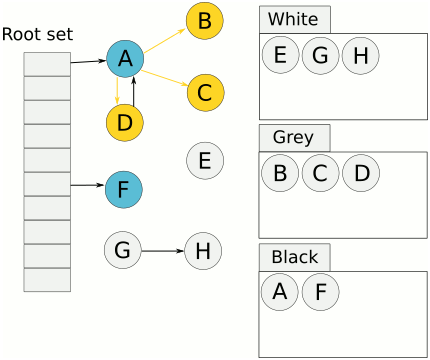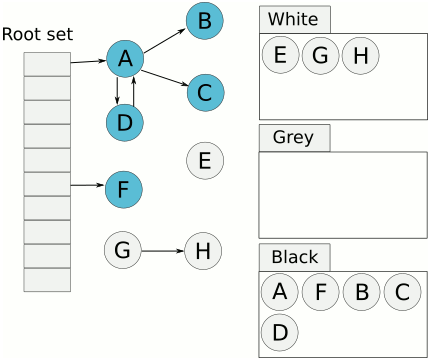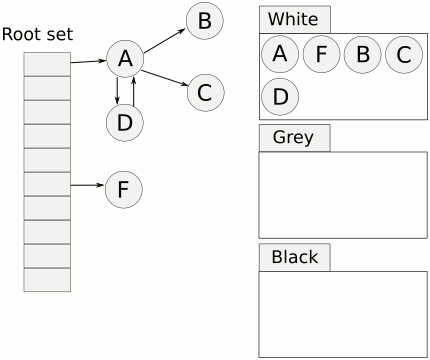
大概理解所谓并发标记,首先是指能够跟用户代码并发的进行,其次是指标记工作不是递归地进行,而是多个goroutine并发的进行。前者通过write-barrier解决并发问题,后者通过gc-work队列实现非递归地mark可达对象。
用下面这个例子解释并发带来的问题,原文引用自CMS垃圾回收器原理。当从A这个GC root找到引用对象B时,B变灰A变黑。这时用户goroutine执行把A到B的引用改成了A到C的引用,同时B不再引用C。然后GC goroutine又执行,发现B没有引用对象,B变黑。而这时由于A已经变黑完成了扫描,C将当做白色不可达对象被清除。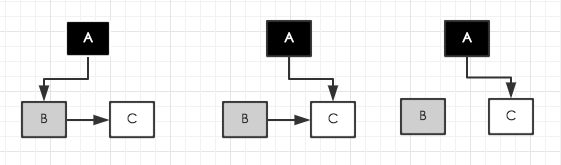
解决办法:引入写屏障。当发现A已经标记为黑色了,若A又引用C,那么把C变灰入队。这个write_barrier是编译器在每一处内存写操作前生成一小段代码来做的。
// 写屏障伪代码
write_barrier(obj,field,newobj){
if(newobj.mark == FALSE){
newobj.mark = TRUE
push(newobj,$mark_stack)
}
*field = newobj
}
如何非递归的实现遍历mark可达节点,显然需要一个队列。
这个队列也帮助区分黑色对象和灰色对象,因为标记位只有一个。标记并且在队列中的是灰色对象,标记了但是不在队列中的黑色对象,末标记的是白色对象。
root node queue
while(queue is not nil) {
dequeue // 节点出队
process // 处理当前节点
child node queue // 子节点入队
}
总结一下并发标记的过程:
gcstart启动阶段准备了N个goMarkWorkers。每个worker都处理以下相同流程。markroot将所有root区的指针入队。scanobject,节点出队列就是黑色了。greyobject入队。// 每个markWorker都执行gcDrain这个标记过程
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
// 如果还没有root区域入队则markroot
markroot(gcw, job)
if idle && pollWork() {
goto done
}
// 节点出队
b = gcw.get()
scanobject(b, gcw)
done:
}
func scanobject(b uintptr, gcw *gcWork) {
hbits := heapBitsForAddr(b)
s := spanOfUnchecked(b)
n := s.elemsize
for i = 0; i < n; i += sys.PtrSize {
// Find bits for this word.
if bits&bitPointer == 0 {
continue // not a pointer
}
....
// Mark the object.
if obj, hbits, span, objIndex := heapBitsForObject(obj, b, i); obj != 0 {
greyobject(obj, b, i, hbits, span, gcw, objIndex)
}
}
gcw.bytesMarked += uint64(n)
gcw.scanWork += int64(i)
}
func greyobject(obj, base, off uintptr, hbits heapBits,
span *mspan, gcw *gcWork, objIndex uintptr) {
mbits := span.markBitsForIndex(objIndex)
// If marked we have nothing to do.
if mbits.isMarked() {
return
}
if !hbits.hasPointers(span.elemsize) {
return
}
gcw.put(obj)
}
实现精确地垃圾回收的前提,就是能获得对象区域的类型信息,从而判断是否是指针。如何判断,最后又把可达标记记在哪里:通过堆区arena前面对应的bitmap。
结构体中不包含指针,其实不需要递归地标记结构体成员。如果没有类型信息只能对所有的结构体成员递归地标记下去。还有如果非指针成员刚好存储的内容对应着合法地址,那这个地址的对象就会碰巧被标记,导致无法回收。
这个bitmap位图区域每个字(32位或64位)会对应4位的标记位。heapBitsForAddr可以获取对应堆地址的bitmap位hbits,根据它可以判断是否是指针,如果是指针且之前没有被标记过,则mark当前对象为可达,并且greayObject入队,供给其他的markWorker来处理。
// 获取b对应的bitmap位图
obj, hbits, span, objIndex := heapBitsForObject(obj, b, i)
mbits := span.markBitsForIndex(objIndex)
// 判断是否被标记过 已标记或不是指针都不入队
mbits.isMarked()
hbits.hasPointers(span.elemsize)
每一次mallocgc都会检查是否需要gcstart。触发的条件是由两个参数决定gc_trigger以及gcpercent。这部分1.8跟1.5实现的类似,只是next_gc这个参数用来指GC结束后希望达到的heap大小。
// mallocgc gcBackgroudMode means concurrent gc
if shouldhelpgc && gcShouldStart(false) {
gcStart(gcBackgroundMode, false)
}
func gcShouldStart(forceTrigger bool) bool {
return gcphase == _GCoff && (forceTrigger ||
memstats.heap_live >= memstats.gc_trigger) &&
memstats.enablegc && panicking == 0 &&
gcpercent >= 0
}
gc_trigger最开始是4MB,next_gc初始为4MB,之后每次标记完成时将重新计算动态调整值大小。但gc_trigger至少要大于初始的4MB,同时至少要比当前使用的heap大1MB。
gcmark在每次标记结束后重置阈值大小。当前使用了4MB内存,这时设置gc_trigger为2*4MB,也就是当内存分配到8MB时会再次触发GC。回收之后内存为5MB,那下一次要达到10MB才会触发GC。这个比例triggerRatio是由gcpercent/100决定的。
func gcinit() {
_ = setGCPercent(readgogc())
memstats.gc_trigger = heapminimum
memstats.next_gc = uint64(float64(memstats.gc_trigger) / (1 +
gcController.triggerRatio) * (1 + float64(gcpercent)/100))
work.startSema = 1
work.markDoneSema = 1
}
func gcMark() {
memstats.gc_trigger = uint64(float64(memstats.heap_marked) *
(1 + gcController.triggerRatio))
}
如果系统启动或短时间内大量分配对象,会将垃圾回收的gc_trigger推高。当服务正常后,活跃对象远小于这个阈值,造成垃圾回收无法触发。这个问题交给sysmon解决。它每隔2分钟force触发GC一次。这个forcegc的goroutine一直park在后台,直到sysmon将它唤醒开始执行gc而不用检查阈值。
// proc.go
var forcegcperiod int64 = 2 * 60 * 1e9
func init() { go forcegchelper()}
func sysmon() {
lastgc := int64(atomic.Load64(&memstats.last_gc))
if gcphase == _GCoff && lastgc != 0 &&
unixnow-lastgc > forcegcperiod &&
atomic.Load(&forcegc.idle) != 0 {
injectglist(forcegc.g)
}
}
func forcegchelper() {
for {
goparkunlock(&forcegc.lock, "force gc (idle)", traceEvGoBlock, 1)
gcStart(gcBackgroundMode, true)
}
}
这里结合gc-work那一节从头梳理一下gc的启动和流程。下面这个图总结了mark-sweep所有的状态变化。在代码里只有三个GC状态,分别对应这几个阶段。总结两个问题:

- Off:
_GCoff- Stack scan + Mark:
_GCmark- Mark termination: _GCmarktermination
gcstart由每次mallocgc触发,当然要满足gc_trriger等阈值条件才触发。整个启动过程都是STW的,它启动了所有将并发执行标记工作的goroutine,然后进入GCMark状态使能写屏障,启动gcController。
func gcStart(mode gcMode, forceTrigger bool) {
// 启动MarkStartWorkers的goroutine
if mode == gcBackgroundMode {
gcBgMarkStartWorkers()
}
gcResetMarkState()
systemstack(stopTheWorldWithSema)
// 完成之前的清理工作
systemstack(func() {
finishsweep_m()
})
// 进入Mark状态 使能写屏障
if mode == gcBackgroundMode {
gcController.startCycle()
setGCPhase(_GCmark)
gcBgMarkPrepare()
gcMarkRootPrepare()
atomic.Store(&gcBlackenEnabled, 1)
systemstack(startTheWorldWithSema)
}
}
解释一下gcMarkWorker跟gcController的关系。gcstart中只是为所有的P都准备好对应的goroutine来做标记。但是他们一开始就gopark住当前G,直到被gccontroller的findRunnableGCWorker唤醒。goroutine源码记录讲了goroutine的过程,m启动后会一直通过schedule查找可执行的G,其中gcworker也是G的来源,但是首先要检查当前状态是不是Gmark。如果是就唤醒worker开始标记工作。
func gcBgMarkStartWorkers() {
for _, p := range &allp {
go gcBgMarkWorker(p)
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
}
}
func schedule() {
...//schedule优先唤醒markworkerG 但首先gcBlackenEnabled != 0
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
}
}
唤醒后开始进入mark标记工作gcDrain。gc-work那一节讲了并发标记的过程,这里不重复。总结来说就是每个worker都去队列中拿节点(黑化节点),然后处理当前节点看有没有指针和没标记的对象,继续入队子节点(灰化节点),直到队列为空再也找不到可达对象。
func gcBgMarkWorker(_p_ *p) {
notewakeup(&work.bgMarkReady)
for {
gopark(func(g *g, parkp unsafe.Pointer) bool {
}, unsafe.Pointer(park), "GC worker (idle)", traceEvGoBlock, 0)
systemstack(func() {
casgstatus(gp, _Grunning, _Gwaiting)
gcDrain(&_p_.gcw, ...)
casgstatus(gp, _Gwaiting, _Grunning)
})
// 标记完成gcMarkDone()
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
gcMarkDone()
}
}
}
mark结束后调用gcMarkDone,它主要是StopTheWorld然后进入gcMarkTermination中的gcMark。大概是做了rescan root区域的工作,但是看到有博客说Go1.8已经没有再rescan了,细节没看懂,代码里看起来却是又重新扫描了一次啊。
func gcMarkTermination() {
atomic.Store(&gcBlackenEnabled, 0)
setGCPhase(_GCmarktermination)
casgstatus(gp, _Grunning, _Gwaiting)
gp.waitreason = "garbage collection"
systemstack(func() {
gcMark(startTime)
setGCPhase(_GCoff)
gcSweep(work.mode)
})
casgstatus(gp, _Gwaiting, _Grunning)
systemstack(startTheWorldWithSema)
}
func gcMark(start_time int64) {
gcMarkRootPrepare()
gchelperstart()
gcDrain(gcw, gcDrainBlock)
gcw.dispose()
// gc结束后重置gc_trigger等阈值
...
}
有多个地方可以触发sweep,比如GC标记结束会触发gcsweep。如果是并发清除,需要回收从gc_trigger到当前活跃内存的那么多heap区域,唤醒后台的sweep goroutine。
func gcSweep(mode gcMode) {
lock(&mheap_.lock)
mheap_.sweepgen += 2
mheap_.sweepdone = 0
unlock(&mheap_.lock)
// Background sweep.
ready(sweep.g, 0, true)
}
// 在runtime初始化时进行gcenable
func gcenable() {
go bgsweep(c)
}
func bgsweep(c chan int) {
goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)
for {
for gosweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)
}
}
也就是系统初始化的时候开启了后台的bgsweep goroutine。这个G也是一进去就park了,唤醒后执行gosweepone。seepone的过程大概是:遍历所有的spans看它的sweepgen是否需要检查,如果要就检查这个mspan里所有的object的bit位看是否需要回收。这个过程可能触发mspan到mcentral的回收,最终可能回收到mheap的freelist当中。在freelist当中的内存再超过一定阈值时间后会被sysmon建议交还给内核。
Proposal: Eliminate STW stack re-scanning
go笔记-GC
go1.5的垃圾回收
go垃圾回收剖析
原文地址:Go 垃圾回收
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
