社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
| 年龄 | 收入 | 销售额 |
|---|---|---|
| 34 | 350 | 123 |
| 40 | 450 | 114 |
| 37 | 169 | 135 |
| 30 | 189 | 139 |
| 44 | 183 | 117 |
| 36 | 80 | 121 |
| 32 | 166 | 133 |
| 26 | 120 | 140 |
| 32 | 75 | 133 |
| 36 | 40 | 133 |
答案:
import matplotlib.pyplot as plt
# 年龄
age = [34,40,37,30,44,36,32,26,32,36]
# 收入
income = [350,450,169,189,183,80,166,120,75,40]
# 销售额
sales = [123,114,135,139,117,121,133,140,133,133]
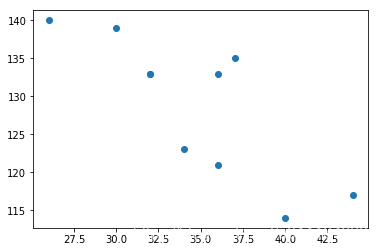
# 年龄,销售额 散点图
plt.scatter(age,sales)
plt.show()
# 收入,销售额 散点图
plt.scatter(income,sales)
<matplotlib.collections.PathCollection at 0x7e87550>
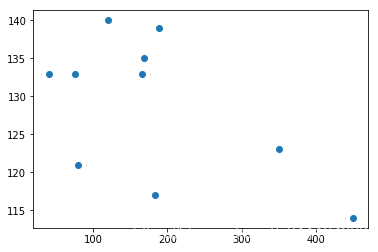
可视化结论:
建议:
x1 = [1,2,3,4,5]
x2 = [3,5,2,9,10]
y = x12 + x23
求y值:原生Python实现
x1 = [1,2,3,4,5]
x2 = [3,5,2,9,10]
y = []
for i in range(len(x1)):
y.append(x1[i]**22 + x2[i]**33)
print(y)
[5559060566555524, 116415321826934818647429, 39970994201, 30903154382632612379512827847945, 1000000000000000002384185791015625]
Numpy实现
import numpy as np
x1 = np.array([1,2,3,4,5])
x2 = np.array([3,5,2,9,10])
y = x1 ** 22 + x2 ** 33
print(y)
[-1504003196 -1667191419 1316288537 1165272329 -2094601527]
| chinese | english | math | name | test |
|---|---|---|---|---|
| 75 | 69 | 36 | 张三 | 一 |
| 68 | 85 | 87 | 李四 | 一 |
| 54 | 42 | 59 | 王五 | 一 |
| 55 | 57 | 63 | 李四 | 二 |
| 59 | 35 | 92 | 王五 | 二 |
| 45 | 63 | 92 | 王五 | 三 |
| 61 | 53 | 76 | 赵六 | 一 |
import pandas as pd
df = pd.read_csv('data/1.class.csv', encoding='gbk')
df
| chinese | english | math | name | test | |
|---|---|---|---|---|---|
| 0 | 75 | 69 | 36 | 张三 | 一 |
| 1 | 68 | 85 | 87 | 李四 | 一 |
| 2 | 54 | 42 | 59 | 王五 | 一 |
| 3 | 55 | 57 | 63 | 李四 | 二 |
| 4 | 59 | 35 | 92 | 王五 | 二 |
| 5 | 45 | 63 | 92 | 王五 | 三 |
| 6 | 61 | 53 | 76 | 赵六 | 一 |
#自定义函数
def top(x,n=1,column='chinese'):
return x.sort_values(by=column)[:1]
df.groupby('name').apply(top)
| chinese | english | math | name | test | ||
|---|---|---|---|---|---|---|
| name | ||||||
| 张三 | 0 | 75 | 69 | 36 | 张三 | 一 |
| 李四 | 3 | 55 | 57 | 63 | 李四 | 二 |
| 王五 | 5 | 45 | 63 | 92 | 王五 | 三 |
| 赵六 | 6 | 61 | 53 | 76 | 赵六 | 一 |
import numpy as np
import matplotlib.pyplot as plt
class trigonometric_function:
tra_1 = 6
tra_2 = 12
def __init__(self,a,k,l):
self.const1 = a
self.const2 = k
self.const3 = l
def Additive_term(self,x):
self.summand_s = np.sin(self.const2*x + self.tra_1)
self.summand_c = np.cos(self.const3*x + self.tra_2)
def trigon_sum(self,m,n):
sum_1 = sum([sum([self.const1*(self.summand_s**i)*(self.summand_c**j) for i in range(m)]) for j in range(n)])
return sum_1
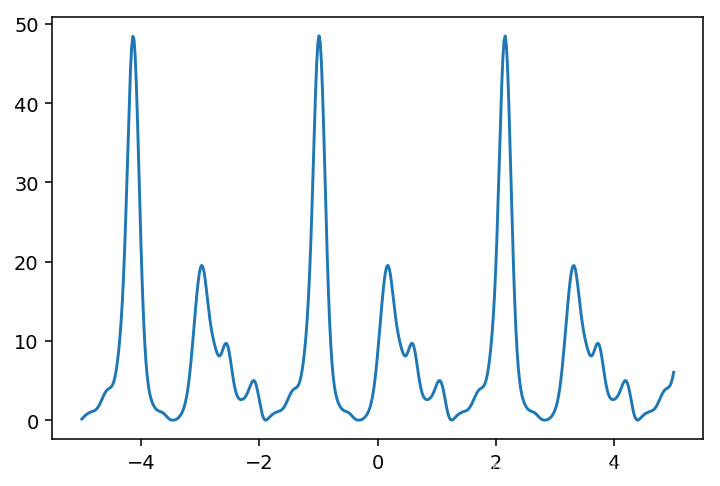
def draw_pic(self,data):
fig,axes_1 = plt.subplots(1,1,dpi=140,figsize=(6,4))
axes_1.plot(x,data)
plt.show()
类变量:tra1,tra2,const1,const2,const3,summand_s,summand_c
实例变量:x,a,k,l,m,n,data(通常前面没有self.。)
方法(属性): Additive_term、trigon_sum、draw_pic
对象:方法、类变量和实例变量
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
f1=trigonometric_function(3,4,6)
#类的实例化
#对类进行初始化
x=np.linspace(-5,5,500)
#生成500个-5到5之间的点
f1.Additive_term(x)
#生成普通三角函数sin和cos
data=f1.trigon_sum(4,5)
#生成三角级数数据
f1.draw_pic(data)
#绘图
基础环境一般为Anaconda,
编辑器多用Ipython或JupyterNotebook,
常用库有:
基本流程
详细流程
……
归一化方法:
归一化作用:
数据分析是指的是通过统计学方法对采集来的数据进行整理分析,从中提取有用信息并最终得出结论的过程。
某些学者认为,数据分析分为三类,入门级的描述性数据分析,其方法主要有对比、平均、交叉分析法。高级的探索、和验证数据分析,分析方法有主要有相关分析,回归分析,因子分析。这样的提法有它自己的道理。在我看来,实际上就两类:描述性统计分析和计算性数据分析。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
