社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
简单地回顾一下数据结构中的相关内容
不支持从中删除元素的数据类型。
背包不关心元素返回的顺序,常用于直接向集合中插入元素,或者遍历已有的元素。
背包API
Bag() //创建一个空背包
void add(Item item) //添加一个元素
boolean isEmpty() //背包是否为空
int size//背包中元素的数量
First in first out.遵循先进先出
队列API
QueueOfStrings() //创建一个空队列
void enqueue(String item) //入队
String dequeue() //出队
boolean isEmpty() //是否为空队
int size() //队大小
队的两种存储结构:(1)队列的顺序存储结构 (2)链队
改进“假溢出”:循环队列
Last in first out.后进先出
栈API
StackOfStrings() //创建空栈
void push(String item) //压栈
String pop() //出栈
boolean isEmpty() //是否为空栈
int size() //栈的大小
栈的两种存储结构:(1)顺序栈 (2)链栈
对象游离(loitering):在栈的数组实现中有对象的引用,但我们没有真正使用它。所以当栈顶减小时,在数组中仍然有我们已经出栈的对象的指针(不再使用)
Java的垃圾收集策略是回收所有无法被访问的对象的内存。在我们对pop()的实现中,被弹出的元素的引用仍然存在于数组中。这个元素实际上就是个孤儿了,没有谁会再访问它,但Java编译器没法知道这一点,除非该引用被覆盖。这种情况(保存一个不需要的对象的引用)成为游离。在这里,避免对象游离很简单,只需将被弹出的数组元素的值设为null即可,这将覆盖无用的引用,并使系统在使用完被弹出的元素后回收它的内存。
改进空栈溢出:将要出栈的元素对应的s[N]设置为null。
public String pop()
{
String item = s[--N];
s[N] = null;
return item;
}
针对顺序存储结构,由数据量来调整数组大小。因为选择用数组表示栈的意味着要先预先估计栈的最大容量。当在栈空或几乎为空时会浪费大量内存。
顺序栈为例。平时,在大小为N的顺序栈栈满时,都会创建一个2N大小的新顺序栈,将旧栈的数据转移到新栈去保存。
**反复倍增法:**当数组填满时,建立一个大小翻倍的新数组,然后将所有元素复制过去。
public ResizingArrayStackOfStrings()
{ s = new String[1]; }
public void push(String item)
{
if (N == s.length) //栈满
resize(2 * s.length);//在插入元素前,将数组长度调整为两倍
s[N++] = item;
}
private void resize(int capacity)
{
String[] copy = new String[capacity];
for (int i = 0; i < N; i++)
copy[i] = s[i];
s = copy;//重新设置实例变量
}
利用头插法插入N,数组的访问次数为:N + (2+4+8+…+N) ~ 3N。先访问数组一次 + 对于复制的内容要访问两次数组 ≈ 访问三次。
push() 当数组满时。新建一个大小翻倍的数组
pop() 当数组为半满时,数组s[]的大小减半
可能出现的问题:数组抖动
抖动(thrashing):当刚好反复交替入栈出栈。当数组满了的时候,就会出现反复翻倍、减半、翻倍、减半,并且每个操作都会新建数组,都要花掉正比与N的时间。
push() 当数组满时。新建一个大小翻倍的数组
pop() 当数组为1/4满时,数组s[]的大小减半
每次处理链表都需要一些额外的时间和空间,相对而言会慢一点。
而数组大小的调整,能分摊每次的操作时间,同时也减少了空间的浪费。
可以用它来存储任意类型的数据
在每份API中,类名后的记号是将Item定义为一个类型参数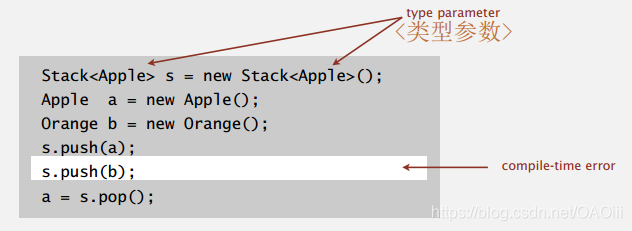
public class Stack<Item>
{
private Node first = null;
private class Node
{
Item item;
Node next;
}
public boolean isEmpty()
{ return first == null; }
public void push(Item item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
}
public Item pop()
{
Item item = first.item;
first = first.next;
return item;
}
}
可以将Stack理解为某种元素的栈。在实现Stack时,我们并不知道的具体类型,但在用例时可以用栈来处理任意类型的数据。
例如:用栈处理String对象
Stack<String> stack = new Stack<String>();
如果没有泛型,我们就需要写每种数据类型定义不同的的API。
允许客户端遍历集合中的元素,但不必让客户端知道我们用数组还是链表
foreach语句是while的一种简写,与while语句等价。
Stack<String> collection = new Stack<String>();
//...
for(String s:collection)
StdOut.println(s);
//...
Iterator<String> i = collection.iterator();
while(i.hasNext())
{
String s = i.next;
StdOut.println(s);
}
在Java中,我们使用接口机制来指定一个类所必须实现的方法。对于可迭代的集合数据类型,java已经为我们定义了所需的接口。
要使一个类可迭代
例:
import java.util.Iterator;
public class Stack<Item> implements Iterable<Item>
{
//...
public Iterator<Item> iterator() //接口
{ return new ListIterator(); } //命名为Listlterator的内部类实现Iterator接口,并且是泛化(generic)的
private class ListIterator implements Iterator<Item>
{
private Node current = first;
//first是处于表头的元素,我们要维护迭代器中实例变量current,用current存储当前正在遍历的元素
public boolean hasNext()
{ return current != null; } //完成遍历后会返回“假”,还没完成就返回真
public void remove()
{ /* not supported */ }
public Item next() //提供要遍历的下一个元素
{//获取下一个元素,如同移除表头一样,取出current,用current引用指向下一个元素,返回item.
Item item = current.item;
current = current.next;
return item;
}
}
}
迭代器:是一个实现了hasNext()和next()方法的类的对象。
如:
public class Stack<Item> implements Iterable<Item>
{
//…
public Iterator<Item> iterator()
{ return new ReverseArrayIterator(); }
private class ReverseArrayIterator implements Iterator<Item>
{
private int i = N;
public boolean hasNext()
{ return i > 0; }
public void remove()
{ /* not supported */ }
public Item next()
{ return s[--i]; }//出栈
}
}
remove()方法为空,希望避免在迭代中穿插能够修改数据结构的操作。
从左到右处理表达式,维护两个栈。如果看到数值,放在数值栈上;如果看到操作符,放在操作符栈上;遇到左括号略过;遇到右括号,出栈操作符和两个数值,将运算结果入栈。
ppt中给出的代码
public class Evaluate
{
public static void main(String[] args)
{
Stack<String> ops = new Stack<String>();
Stack<Double> vals = new Stack<Double>();
while (!StdIn.isEmpty())
{
String s = StdIn.readString();
if (s.equals("(")) ;//左括号略过
else if (s.equals("+")) ops.push(s);
else if (s.equals("*")) ops.push(s);
else if (s.equals(")"))//右括号,出栈操作符和两个数值,将运算结果入栈
{
String op = ops.pop();
if (op.equals("+")) vals.push(vals.pop() + vals.pop());
else if (op.equals("*")) vals.push(vals.pop() * vals.pop());
}
else vals.push(Double.parseDouble(s));
}
StdOut.println(vals.pop());
}
}
改进:运算符压栈前先与栈顶的运算符比较优先级。栈顶的优先级高,则出栈运算符和操作数。栈顶的优先级小,则运算符入栈。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
