社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
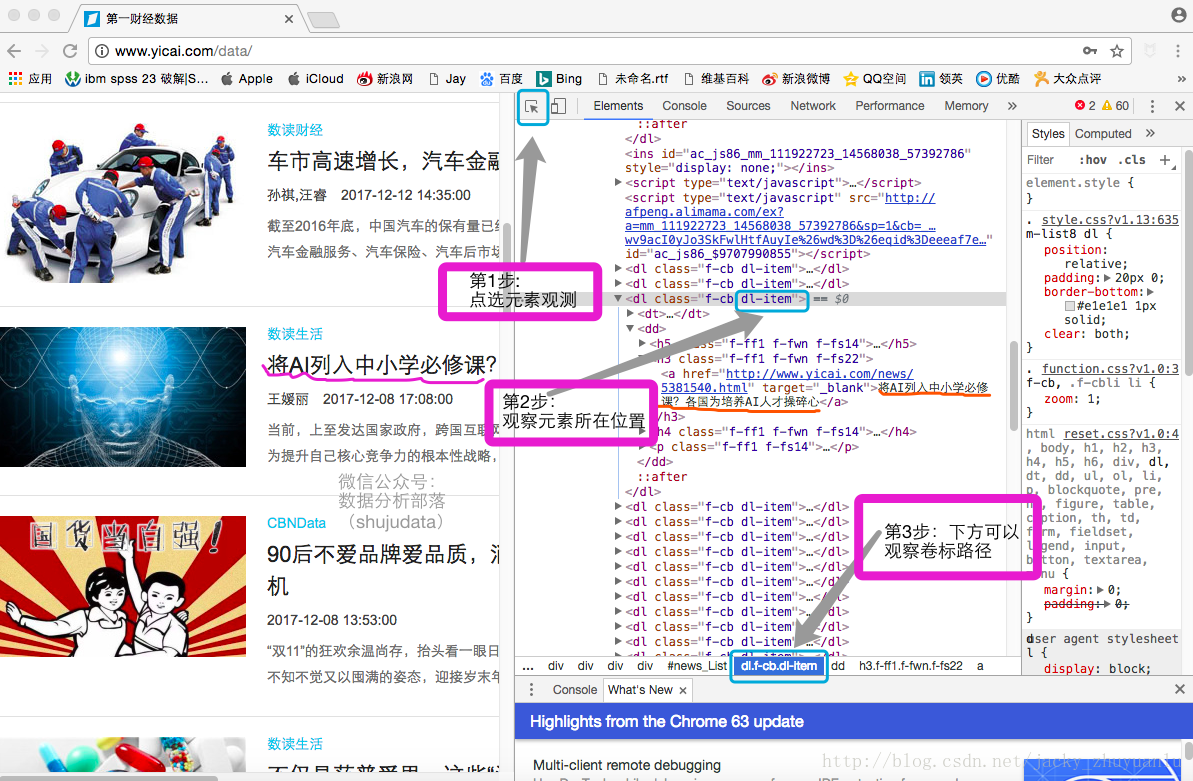
本次分享,jacky将跟大家分享如何将第一财经文章中的标题、时间以及链接抓取出来
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.yicai.com/data/')
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text,'html.parser')
for news in soup.select('.dl-item'):
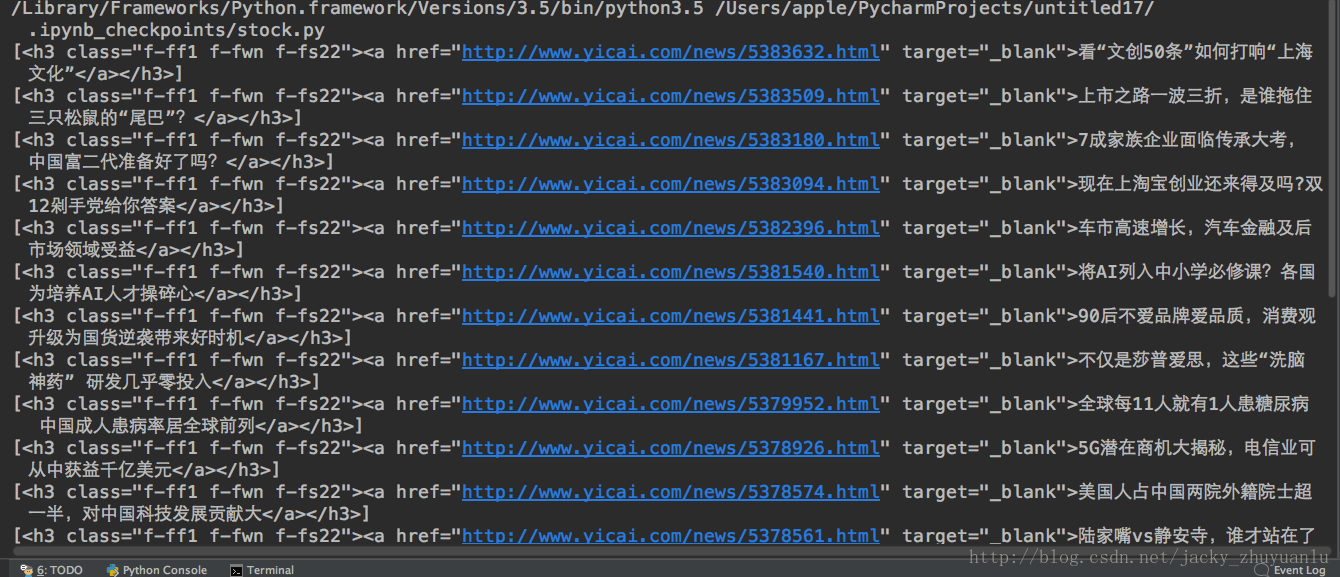
print(news.select('h3'))for news in soup.select('.dl-item'):
print(news.select('h3')[0])for news in soup.select('.dl-item'):
print(news.select('h3')[0].text)for news in soup.select('.dl-item'):
h3 = news.select('h3')[0].text
a = news.select('a')[0]['href']
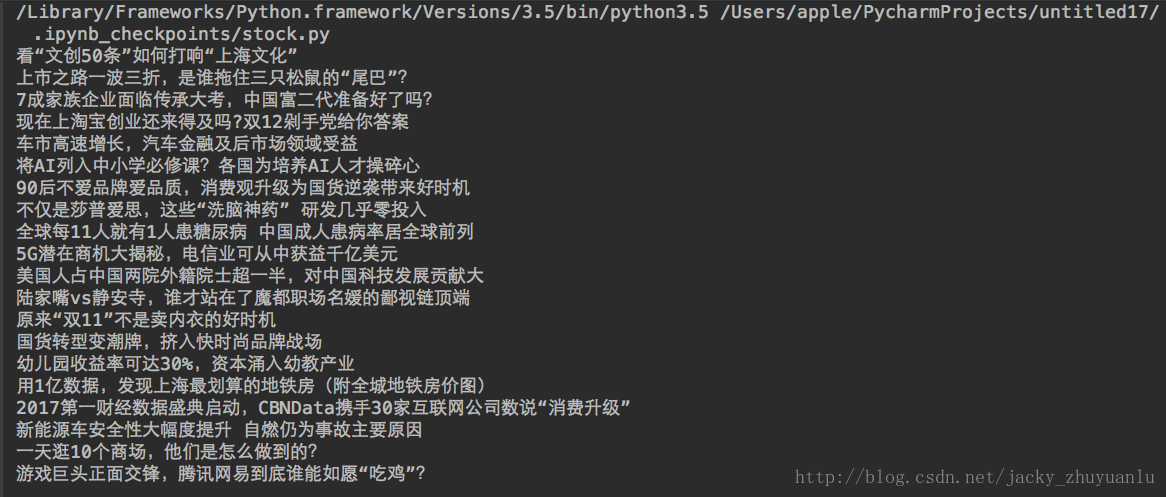
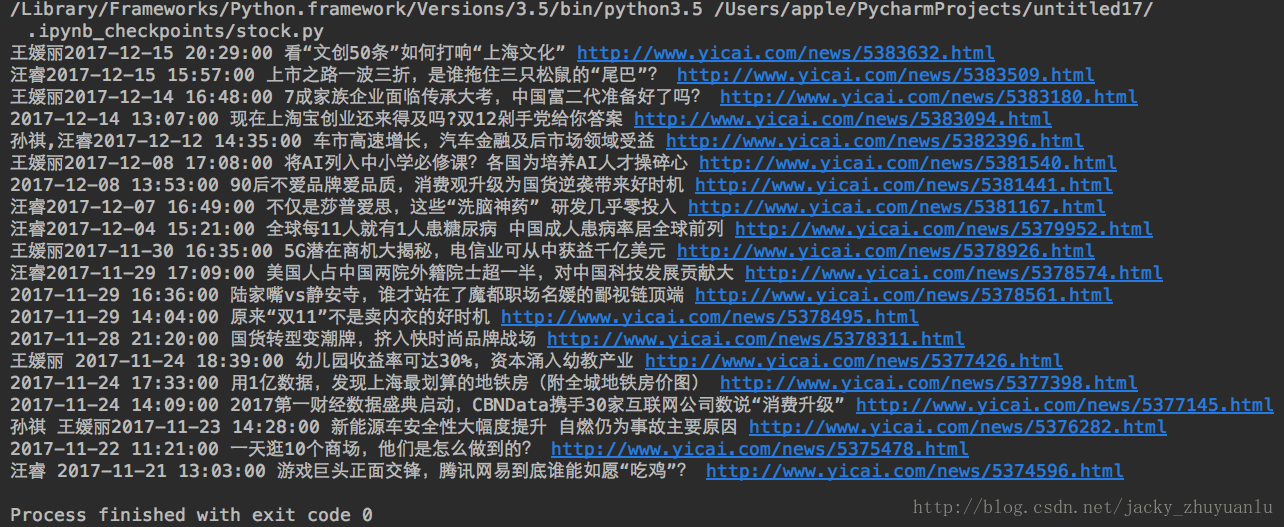
h4 =news.select('h4')[0].text
print(h4,h3,a)如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!