
希尔排序和快速排序是两种非常快速的排序算法,希尔排序是插入排序的一种,是对简单插入排序的改进算法。快速排序简称快排,是对冒泡排序的改进算法。这两种排序都是百万千万级别的排序算法,在排大体量数据时第一弹中所讲的三种简单排序算法的效率实在是差强人意。
希尔排序:
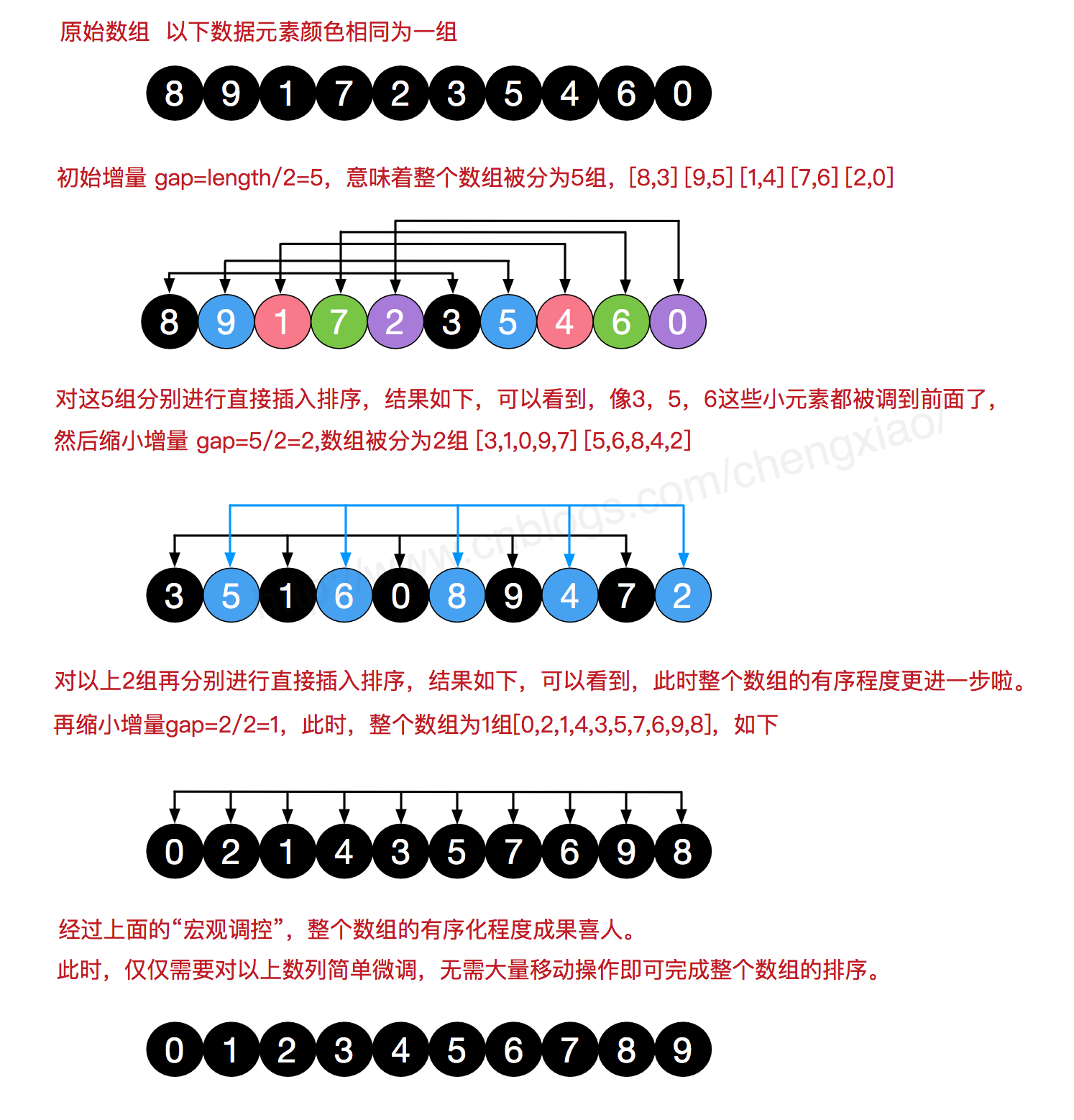
排序图解:
动图演示:
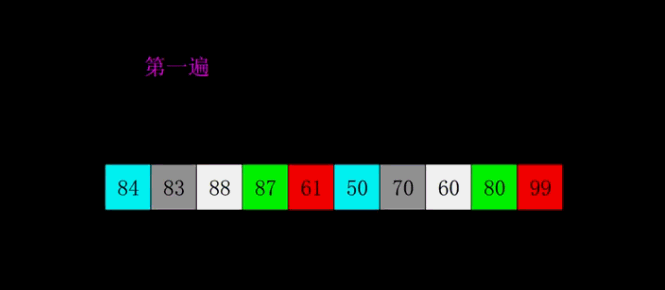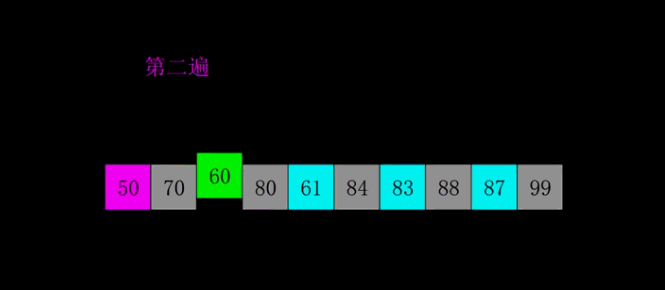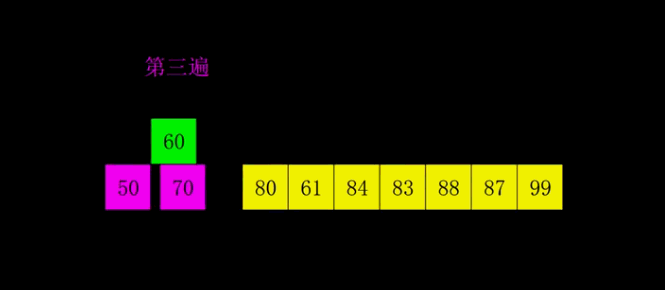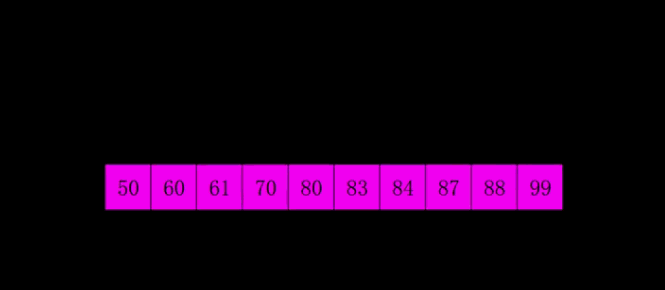
排序原理:
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
简单插入排序很循规蹈矩,不管数组分布是怎么样的,依然一步一步的对元素进行比较,移动,插入,比如[5,4,3,2,1,0]这种倒序序列,数组末端的0要回到首位置很是费劲,比较和移动元素均需n-1次。
而希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组,然后分组进行插入排序,随后逐步缩小增量,继续按组进行插入排序操作,直至增量为1。希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序,小的基本在前,大的基本在后。然后缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
我的代码实现:
1 package cn.ftf.mysort;
2 /*
3 * 我的希尔排序
4 */
5 import java.util.Arrays;
6
7 public class MyShellSort {
8 public static int[] ShellSort(int [] arr) {
9 for(int gap=arr.length/2;gap>0;gap/=2) {
10 for(int i=gap;i<arr.length;i++) {
11 int InserValue=arr[i];
12 int InserIndex=i;
13 while(InserIndex-gap>=0&&InserValue<arr[InserIndex-gap]) {
14 arr[InserIndex]=arr[InserIndex-gap];
15 InserIndex-=gap;
16 }
17 if(InserIndex!=i) {
18 arr[InserIndex]=InserValue;
19 }
20 }
21 }
22 return arr;
23 }
24 public static void main(String[] args) {
25 int [] arr= {3,2,1,5,6};
26 ShellSort(arr);
27 System.out.println(Arrays.toString(arr));
28 }
29 }
复杂度分析:
1. 时间复杂度:最坏情况下,每两个数都要比较并交换一次,则最坏情况下的时间复杂度为O(n2), 最好情况下,数组是有序的,不需要交换,只需要比较,则最好情况下的时间复杂度为O(n)。
很多地方说,希尔排序的平均时间复杂度为O(n1.3)
2. 空间复杂度:希尔排序,只需要一个变量用于两数交换,与n的大小无关,所以空间复杂度为:O(1)。
快速排序:
排序图解:
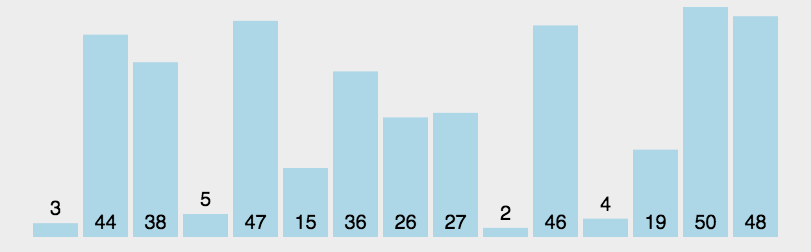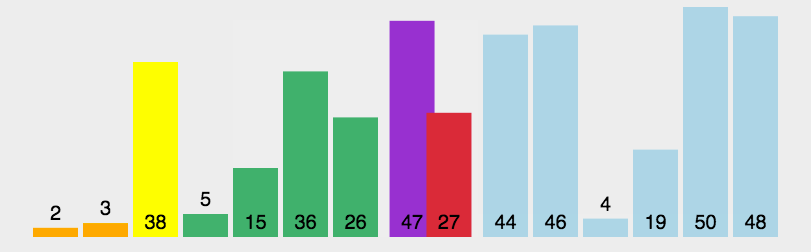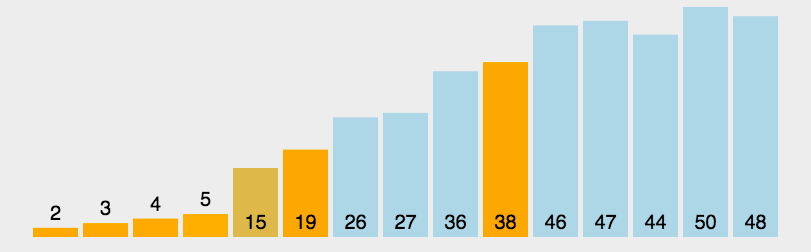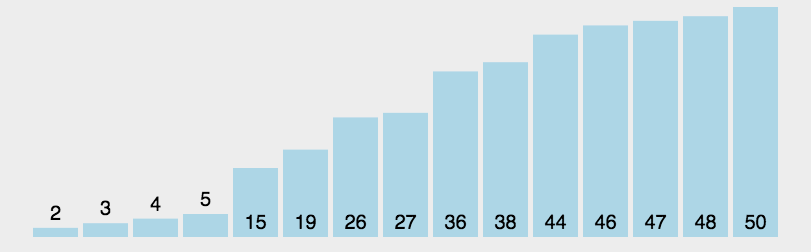
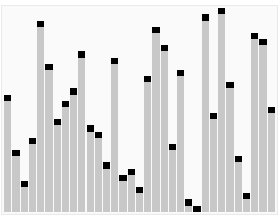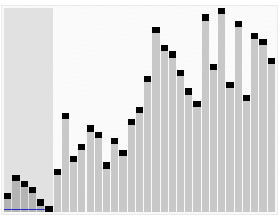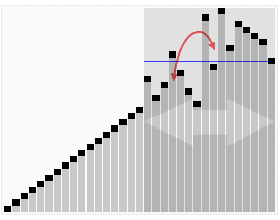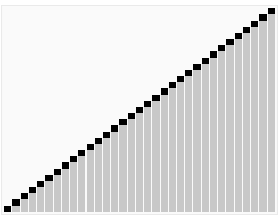
排序原理:
1 package cn.ftf.mysort;
2 /*
3 * 我的快速排序
4 */
5 import java.util.Arrays;
6
7 public class MyQuickSort {
8
9 public static int[] quickSort(int[] arr) {
10 int left=0;
11 int right=arr.length-1;
12 arr=quickSort1(arr ,left,right);
13 return arr;
14 }
15
16 private static int[] quickSort1(int[] arr ,int left,int right) {
17 int l=left;
18 int r=right;
19 int pivot=arr[(left+right)/2];
20 int temp=0;
21 while(l<r) {
22 while(arr[l]<pivot) {
23 l++;
24 }
25 while(arr[r]>pivot) {
26 r--;
27 }
28 if(l>=r) {
29 break;
30 }
31 temp=arr[l];
32 arr[l]=arr[r];
33 arr[r]=temp;
34 if(arr[r]==pivot) {
35 l++;
36 }
37 if(arr[l]==pivot) {
38 r--;
39 }
40 }
41 if(l==r) {
42 l++;
43 r--;
44 }
45 if(left<r) {
46 quickSort1(arr,left,r);
47 }
48 if(right>l) {
49 quickSort1(arr,l,right);
50 }
51 return arr;
52 }
53
54 public static void main(String[] args) {
55 int [] arr= {5,2,4,8,1,6,5,23,-1,-234,5445,1,7,2,6};
56 arr=quickSort(arr);
57 System.out.println(Arrays.toString(arr));
58 }
59 }
复杂度分析:
1,时间复杂度:最佳情况:T(n) = O(n) ,最差情况:T(n) = O(nlogn) ,平均情况:T(n) = O(nlogn)
2,空间复杂度:最优的情况下空间复杂度为:O(log2n);每一次都平分数组的情况 , 最差的情况下空间复杂度为:O( n );退化为冒泡排序的情况 , 平均空间复杂度为O(log2n)
希尔排序和快速排序速度比较:
同样生成包含8000000随机数的数组,用希尔排序和快速排序分别对8000000个随机数进行排序。
1 import cn.ftf.mysort.MyQuickSort;
2 import cn.ftf.mysort.MyShellSort;
3 /*
4 * 我的排序算法速度测试
5 */
6 public class MySortText {
7 public static void main(String[] args) {
8 int[] arr;
9
10 long firstTime=0;
11 long secondTime=0;
12
13 arr=new int[8000000];
14 for(int i =0; i < 8000000;i++) {
15 arr[i] = (int)(Math.random() * 10000);
16 }
17 firstTime=System.currentTimeMillis();
18 MyShellSort.ShellSort(arr);
19 secondTime=System.currentTimeMillis();
20 System.out.println("希尔排序用时:"+(secondTime-firstTime));
21
22 arr=new int[8000000];
23 for(int i =0; i < 8000000;i++) {
24 arr[i] = (int)(Math.random() * 10000);
25 }
26 firstTime=System.currentTimeMillis();
27 MyQuickSort.quickSort(arr);
28 secondTime=System.currentTimeMillis();
29 System.out.println("快速排序用时:"+(secondTime-firstTime));
30
31 }
32
33 }
测试结果:
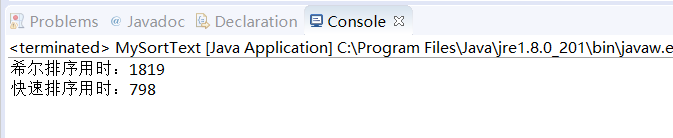
可见,在大体量数据排序时,快速排序比希尔排序要快很多,小体量数速度差距并不明显,数的体量越大,差距越明显。千万级别的数据排序快排速率要比希尔排序速度上更占优势。还需要注意的一点是,希尔排序和快速排序都是不稳定的排序算法!
