社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬取微博m站评论。由于api限制只能爬取前100页,如果想要更全数据需爬pc端。
python 3.5
requests库
re库
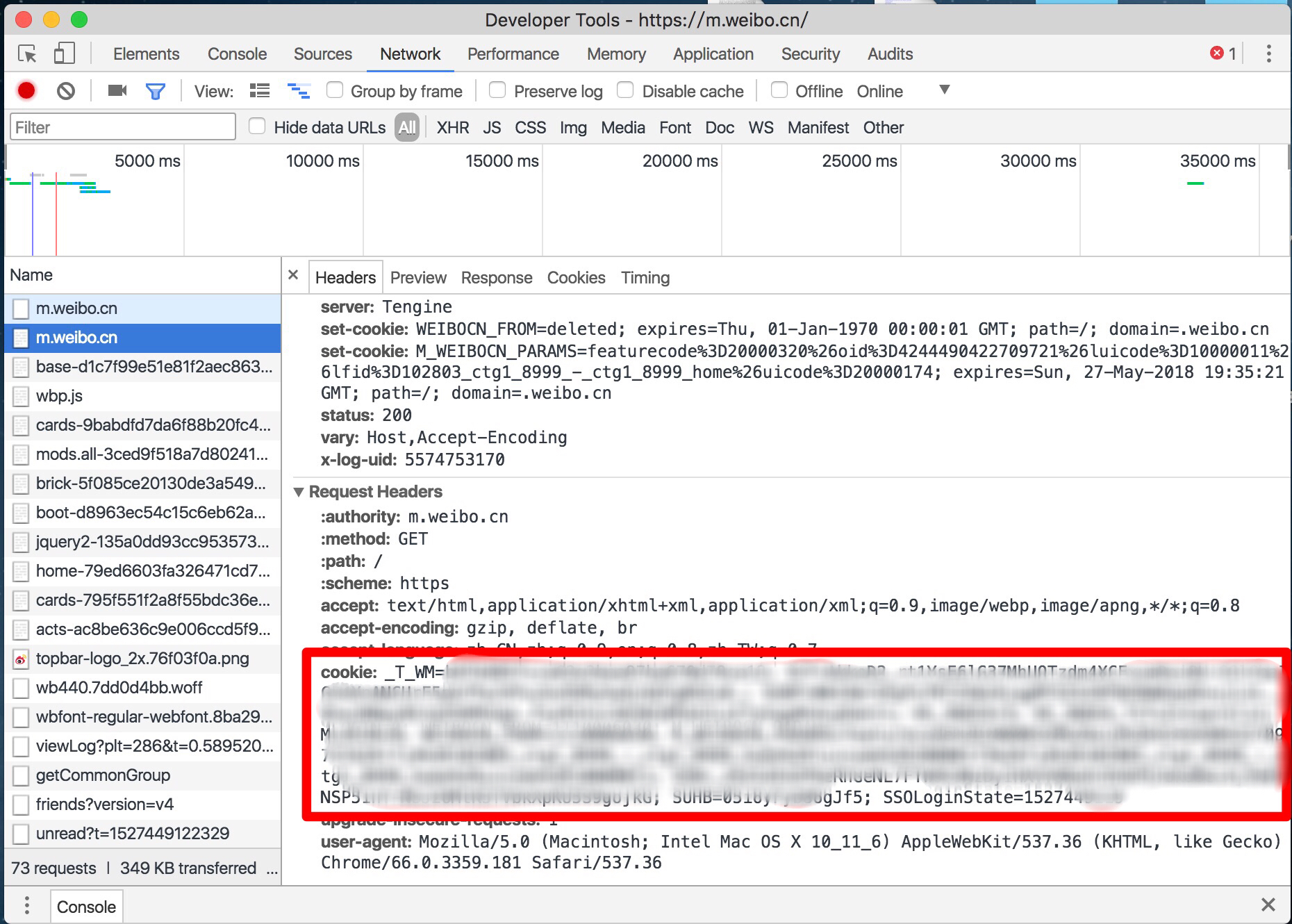
首先,打开m.weibo.cn. 输入用户名密码登陆之后,打开chrome开发者工具(Developer Tool),在Network里面找到m.weibo.cn这个地址,把cookie保存下来。
如图所示,利用开发者工具找到“show?id=...”,第一行的url就是要请求的地址。
多翻两页就会发现,“https://m.weibo.cn/api/comments/show?id=4073157046629802”这一串是不变的,只有后面的“page=”随翻页而变化。
我用的是.format()指令来实现url变化。
上面两步完成后,接下来就可以写爬虫了。
为了不让网站发现我们是爬虫,需要设置user-agent和cookie,代码如下:
headers = {'Cookies':'Your cookie',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
# 在requests中加入headers
j = requests.get(url, headers=headers).json()获取response之后,我们发现提取出了带有html标签的文本,如图所示:
可以利用正则表达式去除文本中的html标签:
tags = re.compile('</?w+[^>]*>')
tags.sub('', data['text'])# -*- coding:utf-8 -*-
import requests
import re
import time
import pandas as pd
# 把id替换成你想爬的地址id
urls = 'https://m.weibo.cn/api/comments/show?id=4073157046629802&page={}'
headers = {'Cookies':'Your cookies',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
# 找到html标签
tags = re.compile('</?w+[^>]*>')
# 设置提取评论function
def get_comment(url):
j = requests.get(url, headers=headers).json()
comment_data = j['data']['data']
for data in comment_data:
try:
comment = tags.sub('', data['text']) # 去掉html标签
reply = tags.sub('', data['reply_text'])
weibo_id = data['id']
reply_id = data['reply_id']
comments.append(comment)
comments.append(reply)
ids.append(weibo_id)
ids.append(reply_id)
except KeyError:
pass
comments, ids = [], []
for i in range(1, 101):
url = urls.format(str(i))
get_comment(url)
time.sleep(1) # 防止爬得太快被封
# 这里我用pandas写入csv文件,需要设置encoding,不然会出现乱码
df = pd.DataFrame({'ID': ids, '评论': comments})
df = df.drop_duplicates()
df.to_csv('观察者网.csv', index=False, encoding='gb18030')
这样100页就爬完了,去除掉重复的大概有700条评论。
后续可以用python读取csv文件进行词频统计等。
reference
https://blog.csdn.net/change_things/article/details/79260274
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!