社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
某些网页需要输入账号密码才能进入到特定的页面,比如cdsn登陆之后才能进入自己的博客管理页面。
博客页面url:https://mp.csdn.net/postlist
登陆的方式有几种,如下具体描述。
假如没有输入用户名密码的原始爬取,代码
import urllib.request
url = "https://mp.csdn.net/postlist"
headers = {'User-Agent:': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
content = urllib.request.urlopen(req)
with open('a.html', 'w', encoding='utf-8') as f:
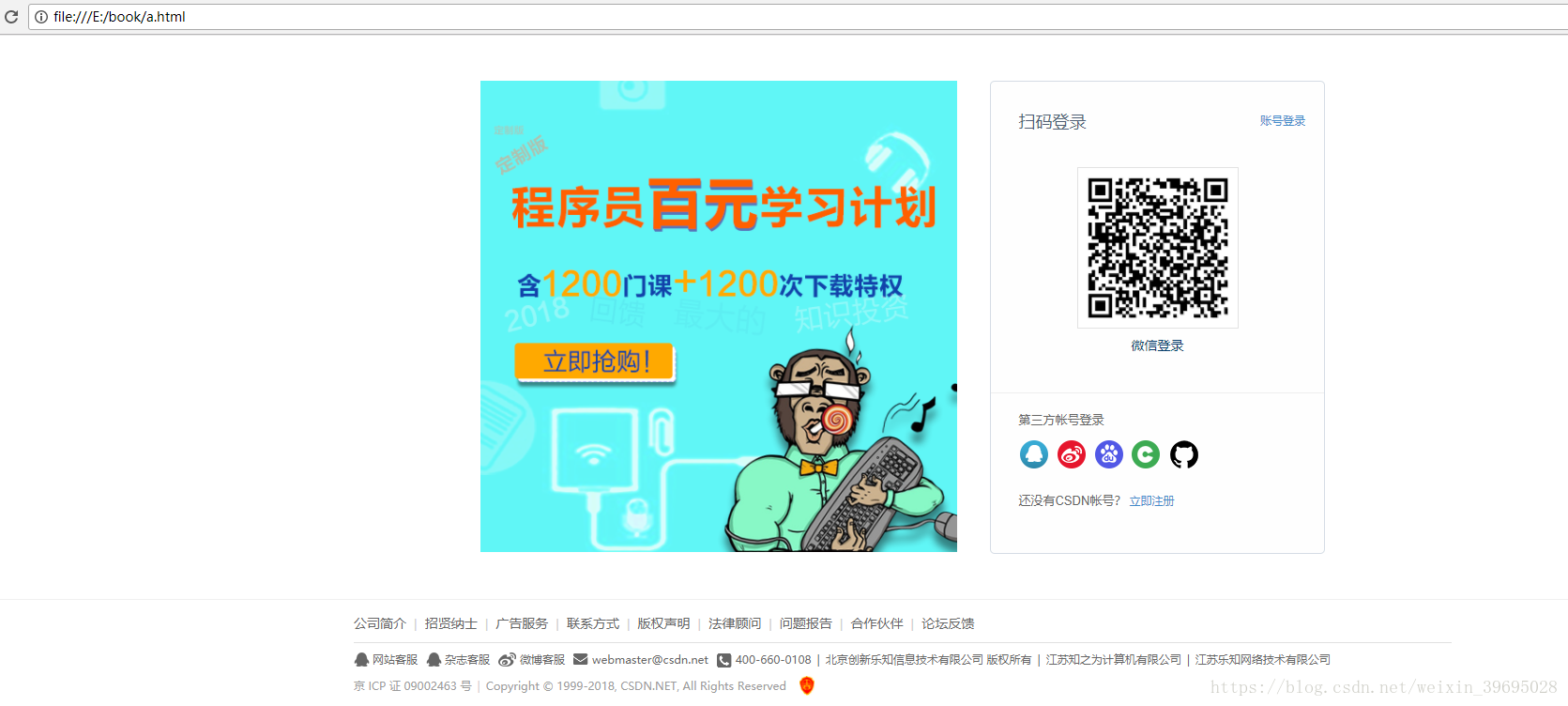
f.write(content.read().decode('utf-8'))运行之后,得到的html页面为
爬取的网站,会默认的回到登陆页面
所以需要使用用户名和密码的登陆方式。
方法一:
打开登陆页面,f12调出开发者工具,使用账号密码登陆,相应的在开发者工具network中查看该网页,点击后寻找到cookie
cookie中包含了账号密码信息,将cookie写入headers中,执行代码
import urllib.request
url = "https://mp.csdn.net/postlist"
headers = {'User-Agent:': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'cookie': "xxxxxxxxxxxxxxxxxxxxxxxxxx"}
req = urllib.request.Request(url=url, headers=headers)
content = urllib.request.urlopen(req)
with open('a.html', 'w', encoding='utf-8') as f:
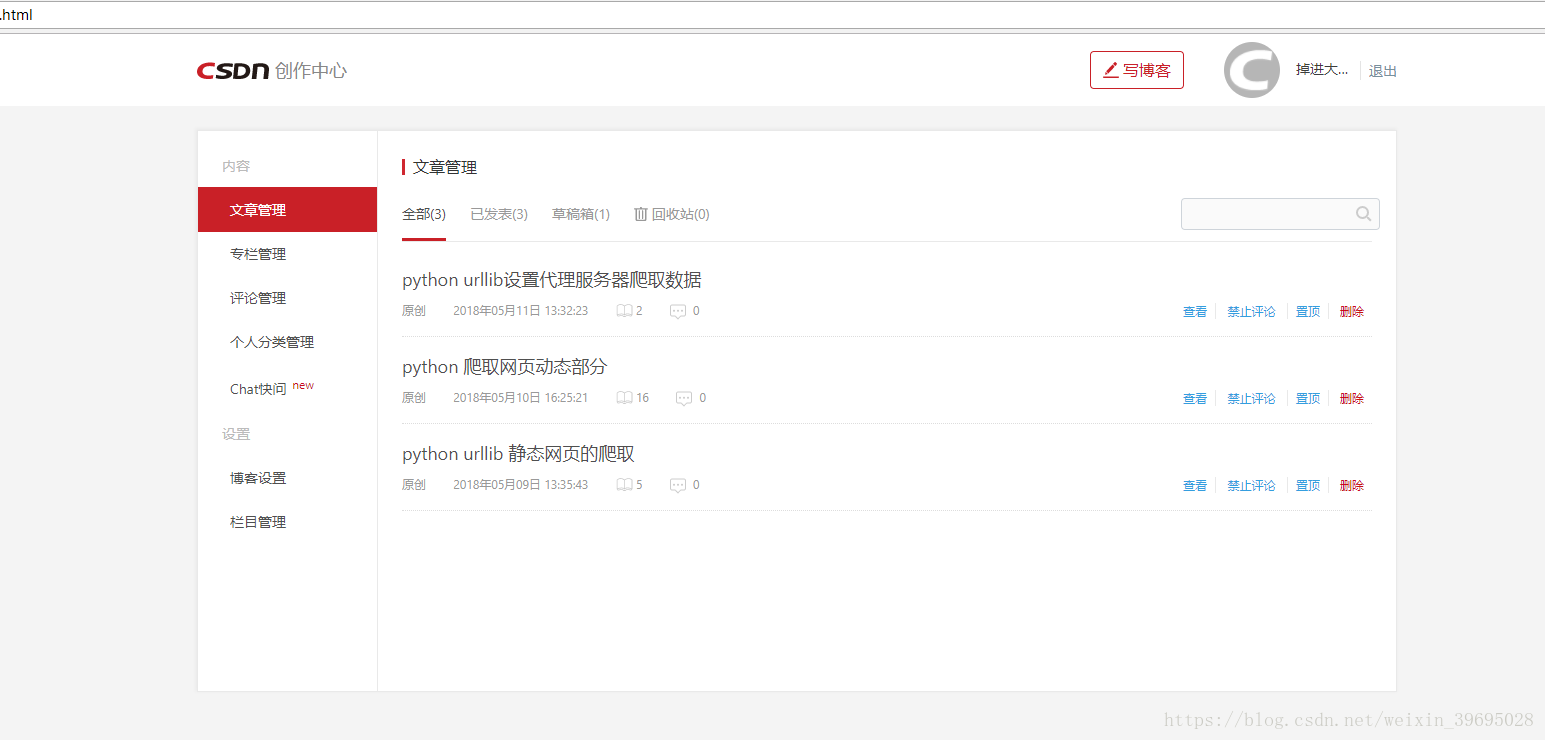
f.write(content.read().decode('utf-8'))打开a.html,页面为
方法二:
使用模拟登陆
模拟登陆就是先用账号密码模拟登陆,得到相应的cookie(python直接获取,不去查找),然后再用得到的cookie登陆网站
代码依次为
import urllib.request
import urllib.parse如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!